Quick Links
- Questions for Norm about Math in Metamath
- set.mm discussion replacement - set.mm is a set theory database written in the Metamath language
- (set.mm discussion - obsolete due to spam activity; do not use - instead, use set.mm discussion replacement)
- Open and closed intervals in R - discussion of notation for intervals in set.mm
- jorend - discussion of Pi (3.14…)
- antecedents - techniques for removing redundant antecedents in a proof
- Natural deduction based metamath system
- metamath program discussion
- metamath website issues
- Related projects discussed on this wiki, roughly sorted by increasing distance from Metamath
- mmj2 - Metamath proof verifier (written in Java by ocat)
- mmj2 download (external link)
- eimm (external link) - export/import for proofs in progress between mmj2 and metamath (written in C by norm)
- mmverify (external link) - Metamath proof verifier (written in Python by raph)
- Hmm - Metamath proof verifier (written in Haskell by marnix)
- verify (external link) - Metamath proof verifier (written in Lua by Martin Kiselkov)
- mmide - Metamath integrated development environment (written in Python by William Hale)
- Ghilbert - Ghilbert proof language and verifier (written in Python by raph)
- Barghest - content management system for Ghilbert (by raph)
- Shullivan (external link) - Ghilbert proof verifier (written in C by Dan Krejsa); loads and verifies translated set.mm in 500 ms
- bourbaki - Bourbaki proof language and verifier (written in Common Lisp by jarpiain)
- IsarMathLib - Proof library based on the Isabelle's ZF logic; includes some theorems translated from set.mm
- ufomath - Proof-checking ATP interface by alih
- mmj2 - Metamath proof verifier (written in Java by ocat)
- metamath utilities and links
- metamath tasks
- metamath bugs
- metamath feature requests
- Translation Systems
What is Metamath?
Quoting from the project's homepage,
- Metamath is a tiny language that can express theorems in abstract mathematics, accompanied by proofs that can be verified by a computer program.
Another quote:
- What really makes Norman Megill (the creator) such a great guy is the fact that you can download the GPL'd source for the software used to build and verify the proofs in the Metamath language. Also available are a complete tarball of the entire site and a GFDL'd book about meta-mathematics and the Metamath software (with TeX source).
Indeed, most of the actual (meta)mathematics on this site has been released to the public domain. See Norman Megill's interesting essay on copyright in mathematics included in the metamath copyright terms page (and compare the QED manifesto, also cited in Norm's essay).
Writings
On this wiki
- Comparison of Ghilbert and Metamath
- Metamath Module Metadata
- Metamath and HDM Phase I
- Metamath Proof Assistant Metadata
- Calculational Proofs from Metamath Proofs
- Why are Metamath proofs so short?
- Notes on Various Proof Systems
- Formal maths bibliography
- Fair Use of Code Snippets
Elsewhere
There is a "Metamath book", entitled "Metamath: A Computer Language for Pure Mathematics" available as a PDF download (http://us.metamath.org/downloads/metamath.pdf) or as a printed-on-demand paperback book (http://www.lulu.com/content/124435, 207 pages for around 11 dollars).
However, I am not finding the LaTeX sources for this book anywhere on the web, nor does the PDF version include a copy of the FDL (although it says it is released under the FDL). Maybe I'm just not looking in the right place for the sources. A copy of the license should be included in published versions of the book, and it would be good to include links to the machine-readable source (see the FDL for exact details).
--jcorneli
Oops, the LaTeX source link got deleted during a recent home page revision. It is restored here: http://us2.metamath.org:8888/index.html#book and a direct link is: http://us.metamath.org/latex/metamath.tex. The comment at the beginning explains how to compile it.
As for the license details, I am not an expert on such matters and just followed the instructions of someone some years ago. Is not a link to the license adequate? If not, where should the license go? Is there an example I can look at? --norm 21-Oct-05
A link is not adequate, as it says in the FDL:
ADDENDUM: How to use this License for your documents
To use this License in a document you have written, include a copy of the License in the document and put the following copyright and license notices just after the title page:
Copyright (c) YEAR YOUR NAME. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled "GNU Free Documentation License".
Furthermore, it says
- If you publish or distribute Opaque copies of the Document numbering more than 100, you must either include a machine-readable Transparent copy along with each Opaque copy, or state in or with each Opaque copy a computer-network location from which the general network-using public has access to download using public-standard network protocols a complete Transparent copy of the Document, free of added material.
Thus, you should be including the above-mentioned link to metamath.tex somewhere in PDF and print versions of the document, probably as part of section entitled "History".
That should be sufficient. book.pdf in http://www-texdev.ics.mq.edu.au/FEM/ gets at least some of these things right. Hopefully I've made the issues clear by quoting the relevant portions of the FDL, however. --jcorneli 23 Oct 05
It does seem that strictly speaking, the license must be included in the work and not simply referenced indirectly by reference. Using the LaTeX version they provide, it adds 10 pages to the book! The cost of the book will increase accordingly, and it seems like a waste of trees. For a 2- or 3-page manual, say for a small program, to turn into a 12- or 13-page manual seems a little absurd.
I'm a little unhappy with this aspect of the license, and I really don't want to add 10 pages of legalese to my book. Right now I am considering just making the whole thing public domain for simplicity. Other than possible plagiarism, which seems unlikely and in any case rather easy to expose, I don't see a clear benefit of the FDL for a book like this.
One thing I wonder about is that some of the "fair use" quotations are not yet in the public domain, so if I declare the book public domain, does that misrepresent the "fair use" quotations that, strictly speaking, may still be under copyright? --norm 24-Jul-2006
I'd support that choice.
In response to your question, to sum up, I don't think that's a problem.
And in a bit more detail: when you put something in the public domain, what you are doing is waiving the special status had under copyright. You can't waive rights that you don't have. If, hypothetically speaking, those quotes were a copyright infringement, then there can be downstream copyright infringments once the document is transfered to public domain (this is one of the reasons that one should be "careful" to make sure that things that advertise themselves as being public domain actually are). However, since you say that you are in fact making fair use of the quotations, people who use the document under public domain terms aren't committing any crime. --jcorneli
General Discussion
Ghilbert?
I have begun a comparative analysis of Ghilbert in relation to Metamath. Ghilbert contains some interesting ideas. The Python code to verify a Ghilbert proof doesn't appear to be a problem (don't need it), and the files referenced at ghilbert.org contain a Metamath copyright from 2003 – but since then Norman Megill has put set.mm into the public domain via a "Creative Commons" license (no, public domain is technically not a "license"; one places works into the public domain with a declaration – raph), and the rest of Metamath is GPL'd. So is the IP status of the Ghilbert design the issue here? The design document states, "Ghilbert can largely be considered to be a patch on Metamath to improve those weaknesses." So where is the beef? Ghilbert patents? Does someone want to contact Raph Levien and find out – because for sure if he wants Ghilbert to become a planetary standard he will want people to use his file specifications. --ocat
My intent is for Ghilbert to be very, very free, and sorry for not making that clearer. I haven't done a careful release just out of laziness, but when I do it will definitely be either GPL or less restrictive. The set.mm database that I've converted to Ghilbert syntax should have the same copyright as the original, which as ocat points out above is none at all. As it happens, over the last year or so I've done a ton of work on Ghilbert that I have not yet released, including a nearly complete interpretation of HOL logic in ZFC set theory, and a development of predicate calculus that's more decoupled from set theory than Norm's version in set.mm (for example, his definition of substitution uses set abstraction). In any case, I'm more than willing to discuss Ghilbert, its design, and so on, but am a little unsure about the netiquette. I don't want to just barge in here and create a ton of pages; perhaps it would be more appropriate to do the gardening of ghilbert.org and put some more detailed writing there.--raph
Metamath and logic agnosticism
One question for the metamathematically minded people investigating this software package is: how does metamath "do" logic agnosticism? Can you explain this to the rest of us in concrete terms (I know, it is asking a lot to be concrete about metamathematics!) Are there examples in alternate logics? Does anyone care to try to do some math in weird logics (e.g. using category theory instead of set theory as the basis of mathematical reality)? Don't get too overwhelmed (or too overwhelming), but it would be interesting to see something about these topics. --jcorneli Sun Jun 19 01:28:40 2005 UTC
Tenative Answer: Metamath has no built-in logic or definition of "truth". A valid proof is simply a reverse polish notation sequence of statement labels that when fed into the Proof Verification engine exactly recreates the formula being proved. The Proof engine itself may be termed a stack-based automaton. The difference between a Proof and the RPN version of a formula's parse tree is that the parse tree's RPN can refer only to syntax axioms and variable hypotheses, while a proof can, in addition, refer to any previously defined logical hypothesis or assertion. "Proving" is simply the work involved in substituting expressions for variables – and ensuring that only valid substitutions are performed (there is much to be said about "Type Codes", which are implicit in Metmath but don't get a whole lot of airtime in Metamath.pdf.)
Metamath includes a rather large Quantum Logic database (ql.mm), as well as a very instructive work by Bob Solovay, peano.mm. In addition, set.mm's axioms are defined throughout the file, as needed, so it is possible to see how far one can get using the "Intuitionist" approach--ocat
Cool, thanks for the answer. Ray put together some template utilities that seem similar on a mechanical level, and has just recently been talking in more theoretical terms about "Terms, Definitions, and Systems of Axioms" (the ideas there again seem similar, on a theory level). --jcorneli Sun Aug 07 01:01:40 2005 UTC
I created a page showing several Grammars recently extracted from key Metamath databases: metamath-Grammars Perhaps the information will be interesting? I know set.mm rocked my world when I tried my hand at writing a "naive" parser, and the Bottom Up algorithm will not complete set.mm before next Friday (but Earley Parser works fine, about 8 seconds for building the grammar, validating and parsing.) The problem isn't the size of the database but the complexity of some of the statements (very!) I think the job of OCR'ing arbitrary math texts will definitely entail handling Notations that are challenging, and their Grammars will perhaps be very challenging as well. ocat Sun Aug 07 01:22:22 2005 EDT
(norm here) In addition to the examples mentioned by ocat, the Metamath Solitaire applet demonstrates implicational logic, intuitionist propositional calculus, modal logic, modal provability logic, Euclidean geometry, and weak D-complete logic. The applet's axioms can be used as the starting points for Metamath theorem databases in these logics for anyone interested in them.
Category theory can be done in Metamath by extending the ZFC axioms with the Grothendieck axiom (Metamath book, p. xii).
As for other "weird logics," one interesting example I'd like to investigate some day is quantum set theory, proposed by Takeuti. It has the strange property that quantum-set equality is non-Leibnizian, i.e. x = y does not necessarily imply x \in z iff y \in z for all z.
Most "weird logics" such as intuitionistic, relevance, quantum logic, etc. are weak fragments of classical logic, i.e. all of their theorems hold in classical logic. A very interesting exception is the family of paraconsistent logics. For example, one such system has an axiom called "relativity", ((A → B) → B) → A, which does not hold in classical logic!
I agree that Metamath is "logically agnostic"; that is an interesting way to describe it that I haven't heard before. Specifically, it can implement all the above logics natively, since you tell it what the axioms are, starting from an empty framework that is devoid of any logic at all. Most other proof languages presuppose a fixed built-in logic that is usually classical. This is not to say that they can't work with the above logics, just that they must deal with them as external mathematical objects rather than doing their proofs directly in the logics themselves. – norm 6 Sep 2005
Agnostic – noncommittal – is a better description than "catholic" – broad or liberal scope.
http://dictionary.reference.com/search?q=catholic
--ocat
Metamath content
I'm interested in using metamath to explore propositional and predicate calculus using a natural deduction based system of axioms. I wonder if this wiki is a place where some questions about this subject could be asked. In my mind it would be a sort of commentary to the set.mm which is a liitle bit "too dry" for mere beginners like me (since there are only the theorems and very few commentaries). Questions would look like this : "how the substitution definition has been coined ? What was the (potential) intellectual process of its creator when he/she invented the definition. I think it can be helpful to grasp a definition that is not as straightforward as the usual one ? "
But perhaps this wiki is only about the metamath program in itself (and other connected programs) and not about the content of the set.mm file ?
--frl
Hello frl! Bienvenue. I hope you will provide a copy of your .mm files. Are you planning to use textbooks as the basis for your experiments with Metamath, or do you plan to create your own language from scratch? I look forward to hearing about your experiments. --ocat
Hi ocat, merci de m'accueillir. If you need it I will give the .mm file but I still need to polish it up. To realize the .mm file I mainly used a text by Christoph Benzmüller called "from natural deduction to sequent calculus (and back)". And obviously I learned a lot by studying the proofs in set.mm. Eventually I asked some questions to norm who helped me a lot.
Here is a link to Benzmüller's text :
http://www.ags.uni-sb.de/~chris/papers/2002-pisa.pdf
– frl 27-Sep-05
Hi frl, that is very exciting information. I first heard about Sequent Calculus a few days ago at:
http://en.wikipedia.org/wiki/Sequent_calculus
Excerpt: "… sequent calculi and the general concepts relating to them are of major importance to the whole field of proof theory and mathematical logic… "
and from:
http://en.wikipedia.org/wiki/Proof_theory
we obtain the list of primary suspects in the investigation!
"Together with model theory, axiomatic set theory, and recursion theory, proof theory is one of the so-called four pillars of the foundations of mathematics."
So, Mr. Holmes (frl), I await your final .mm results with great anticipation – Dr. Watson ( --ocat 27-Sep-2005 )
More Discussion
Thanks for posting folks. Feel free to use the wiki to talk about your projects as much as it is helpful to you – I think it would be great if AM could be the wiki center for metamath & its clan.
Raph, on Ghilbert, I assumed that you did want to make a FAIF release & simply hadn't had time yet. I'm glad that this is the case & look forward to news of the release of the legally sanctified version. Again, if the wiki seems to be a good medium for you and your audience/contributors, go ahead and use it as much as you like. I'll certainly have some questions as time goes by.
--jcorneli
Ocat, on your metamath vs ghilbert notes: I wonder if you'd be interested in writing a metamath vs mizar note. Of course, it would have a different flavor. Or maybe there is something on Norm's site that already says the things most people would be interested in knowing about the relationship (and differences) between these programs.
--jcorneli
jcorneli: ghilbert is metamath plus definitions plus interfaces plus sexps minus notation – and with a great improvement in the proof algorithm (AFAIK - a proof of the ghilbert proof algorithm is needed.) my only qualification for saying anything about metamath or ghilbert is that i paid expensive tuition by writing code expressing the Metamath.pdf specifications. i'm just a code monkey, in other words. --ocat
Well, I think someone should write such a thing at some point. Had I written a master's thesis, one of the possible topics might have been "a comparison of several provers." Freek has written a comparison (of sorts), but it lacks narration. Incidentally, since Freek's comparison is sort of a rosetta stone of provers (by way of the irrationality of the square root of two), someone might want to write a proof of this lemma in hcode, and presumably a ghilbert proof could be added to the list very soon.
{this looks better than the raw source file at Freek's page: http://us.metamath.org/mpegif/sqr2irr.html ) --ocat
The overall goal of comparing and understanding the various provers is huge. Ocat, I'm sure that if you felt like it, you could use your expert knowledge of one system to learn another one somewhat more easily than an average new user, who'd be learning cold. But it isn't imperative that you write such a thing, it was just a passing thought I had. --jcorneli
Great. I was also going to post a link to Freek's paper. Since I have looked at Mizar in some detail, and HOL in more, I hope you'll find some Notes on Various Proof Systems helpful. – raph
Thanks Raph! Seems very helpful, written at a nice level, and with a good set of hyperlinks to other material. This should be expanded upon as time goes by, but its a very swell beginning. As for the goals of HDM vis a vis formal systems (or maybe "objectives" would be a better word), that may be somewhat in flux.
Figuring out how things will be proved and processed is a big task, and right now I'm dealing with finishing up a presentable demo of something else that HDM needs. Ray has been focusing on more formal things, but of late his availability has been somewhat limited (and may continue to be).
But to come to the point: I think the objectives are (1) to assemble the tools (hopefully from existing pieces when possible) to do basic proof checking and theorem proving, and make them work with a general-purpose high-level mathematical language; (2) If we can figure out a way to do it legally, which in many cases we probably can't, it may be possible to use existing work in computer math by translating their code into a format we can use. However, (2) is only going to work when the corpus's rights are either public domain or (more generally) GNU GPL compatible. And of course there is the actual work involved to be considered (could be quite non-trivial).
Given the somewhat limited mindpower behind this problem at present, you're welcome to jump in and suggest and/or define some new objectives. Ray may be able to say more about specific immediate goals and also about his current work in this area. I'm mainly just in "learning background material" mode right now.
--jcorneli
[(norm:)Good-but-not-that-]big news today at the Metamath headquarters!
http://us2.metamath.org:8888/mpegif/mmnotes.txt
(21-Oct-05) A big change (involving about 121 theorems) was put into the database today: the indexed union (ciun, df-iun) and indexed intersection symbols (ciin, df-iin) are now underlined to distinguish them from ordinary union (cuni, df-uni) and intersection (cint, df-int). Although the old syntax was unambiguous, it did not allow for LALR parsing of the syntax constructions in set.mm, and the proof that it was unambiguous was tricky. The new syntax moves us closer to LALR parsability. Hopefully it improves readability somewhat as well by using a distinguished symbol. Thanks to Peter Backes for suggesting this change.
Originally I considered "…" under the symbol to vaguely suggest "something goes here," i.e. the index range in the 2-dimensional notation, but in the end I picked the underline for its simplicity (and Peter prefered it over the dots). Of course I am open to suggestion and can still change it. In the distant future, there may be a 2-dimensional typesetting to display Metamath notation (probably programmed by someone other than me), but for now it is an interesting challenge to figure out the "most readable" 1-dimensional representation of textbook notation, where the symbol string maps 1-1 to the ASCII database symbols.
iuniin is the same as before but has an expanded comment, and also illustrates the new notation.
(18-Oct-05) Today we show a shorter proof of the venerable theorem id. Compare the previous version at http://de2.metamath.org/mpegif/id.html .
I threw in the new "id" proof announcement because that theorem has been looked at more than any other one, AFAIK. The proof is now down to 3 steps :)
About LALR, I have been informed that instead of creating a parser that can handle ambiguous grammars, the difficulty of proving un-ambiguity (impossible in the general case), means that that is just living with the problem instead of fixing it. The preferred approach is to make the grammar fit LALR(k) for some k, thus "proving" the grammar to be unambiguous. And if that is done, then standard tools can generate a parser, which is an added benefit. I think this is relevant for HDM as well, especially since an industrial strength parser is not really that fun a thing to write from scratch.
--ocat 21-Oct-2005
It appears I mispoke when I said "The new syntax allows LALR parsing," so I changed it to "The new syntax moves us closer to LALR parsability" above. From Peter Backes:
- It makes it more LALR than before, but not completely. ;)
- What remains is
- 1) set = set (trivial, since redundant) [i.e. weq vs. wceq]
- 2) set e. set (trivial, since redundant) [i.e. wel vs. wcel]
- 3) [ set / set ] (trivial, since redundant) [i.e. wsb vs. wsbc]
- 4) { <. set , set >. | wff } (we already discussed it and agreed it was not easy to solve) [i.e. copab]
- 5) { <. <. set , set >. , set >. | wff } (ditto) [i.e. copab2]
These are all easy to fix by brute force (eliminating weq, wel, and wsb, and changing "{", "}" to "{.", "}." in copab and copab2), but I am looking into whether there are "nicer" ways to do this first as I plod along slowly but carefully. It will get there eventually. :) On the off-chance anyone actually needs a true LALR set.mm, let me know and I can quickly prepare a custom version with these brute-force changes. It should be noted that if (4) and (5) are left alone, and only (1)-(3) fixed, we would have a LALR[7] version of set.mm, but LALR[7] cannot be handled by bison/yacc. --norm 21-Oct-2005
windy exposition regarding weq/wceq and other topics: metamathGrammarFacilities --ocat 23-Oct-2005
Related to ql.mm at www.metamath.org, I came across this today at BoingBoing?.net: David Deutsch, founder of the field of quantum computation, named recipient of the 2005 $100,000 Edge of Computation Science Prize
Areas of related interest also mentioned:
"Also in 2000, in "Machines, Logic and Quantum Physics" (with A. Ekert and R. Lupacchini), a philosophic paper, not a scientific one, he appealed to the existence of a distinctive quantum theory of computation to argue that our knowledge of mathematics is derived from, and is subordinate to, our knowledge of physics (even though mathematical truth is independent of physics).
In 2002, he answered several long-standing questions about the multiverse interpretation of quantum theory in "The Structure of the Multiverse" – in particular, what sort of structure a 'universe' is, within the multiverse. It does this by using the methods of the quantum theory of computation to analyse information flow in the multiverse."
Wow. --ocat 14-Nov-2005
As a curious coincidence I am reading Deutch's original paper right now. --norm 15-Nov-2005
ocat 17-Dec-2005
First, I would like to thank Planet Math and Asteroid Meta for hosting mmj2 and the Metamath+Friends discussion area. The kindness is appreciated greatly. And I would like to thank Norm Megill for inventing Metamath, thereby providing a source of endless amusement and educational benefits for people all over the world!
Secondly, Merry Holidays to everyone! I am very sure that everyone here will be receiving presents from Santa instead of coal :) (Or not.)
Finally, I have an idea for the possible benefit of HDM when it reaches the stage of being able to Borg up all available mathelogical content. I am unsure of the popularity of this idea, but I will run it up the flagpole anyway to see who salutes… If the Friends of Metamath – Ghilbert, Bourbaki, Hmm, (and future friends) – can provide a utility to convert to and from Metamath ".mm" format, then all HDM needs is a similar utility in order to be able to hoover up all content from Metamath and these other systems! Later, HDM can presumably write conversions for Earth's other great math systems and snarfle up their content – as permitted by law and consent of the owners. In theory HDM should be able to convert Metamath .mm statements to HCode, if that is on the final agenda, so eventually everything will come together without a lot of extra work (except for ontological reconciliation, but we knew that already :)
- Good point; regard .mm as a "metalanguage" for the FOM programs. Seems reasonable to (non-expert) me. Similarly, hcode is supposed to be a metalanguage for many and various mathematical languages. --jcorneli
- Perhaps "metalanguage" does not convey the intent of my idea accurately. Bourbaki and Ghilbert provide additional language capabilities. A conversion to Metamath wouldn't necessarily preserve 100% of information in every file/database in these languages -- that would depend on the content. So Metamath could be considered a lowest common denominator, a base. The beauty of having a common "base" language and converters to/from these other languages is portability amongst themselves, as well as the obvious benefit to HDM of having, potentially one day, tens of thousands of proven, consistent theorems in various axiom systems starting from the bare metal of logic. Then when you have a "standard", mainline HDM ontology, it should be possible to reconcile everything, assimilate it all, including the FEM entries, and detect duplicates, congruencies, etc. --ocat
Ghilbert's design was driven in very large part by the desire to allow smooth translations to and from other systems. In theory, it can translate seamlessly to and from Metamath (it just needs some more code to do this in practice). I think there are some other advantages to the Ghilbert approach, including much simpler handling of syntax. --raph
hierarchy of systems
Let's suppose I have a sound system of axioms. Let's suppose I derive theorems from this system. Now if I replace one of my axioms by one of the theorems I derived I think my system is still sound. But it may be less complete (if I dare say) than the previous one. Now if I use this new system to derive another set of theorems and if once again I replace one of the axioms by one of the new derived theorems I get a third system still sound and still less complete than the two previous ones. If we call T1, T2, T3 the sets of theorems we can obtain in each system I think we have T3 is included in T2 and T2 is included in T1. I wonder if we can use this process to have a system where a given theorem is not provable ? frl 1-May-2006
- I don't understand the algorithm you are proposing, that would lead to making a given theorem unprovable. How would you use the given theorem as the "input" to the algorithm? norm 2-May-2006
- You are right it is the weak point. :-) frl 2-May-2006
How Does Norm Create New Proofs?
Norm, would you describe the actual process you use to create new Metamath proofs? Specific items of interest:
- Do you first outline a new proof on paper?
- If a proof is very simple, like chaining together a few equalities to achieve the result, I don't write anything down but just type it in directly.
- .
- The harder the proof, the more detail I put on paper before I start. In the case of very difficult proofs, I work out every detail on paper before I start. The reason is mainly that there are often little gotcha's that I'll overlook in my mental proof sketch, that will get identified when I force myself to think through the details. If I try to enter such a proof directly, without working out the details, I will often get stuck in a path that can't be completed, which is frustrating.
- .
- I may try to enter a moderately difficult proof directly, sometimes with luck, and other times I'll see that I really need to work out the details. And even the details on paper can vary in detail - a rough sketch is more efficient time-wise, but with a higher risk I'll get stuck. There have been proofs where I've worked out on paper 3 or 4 versions of successively increasing detail, each in response to another gotcha I ran into.
- .
- For the most difficult proofs, I often work out every detail in pretty much the same way it will be entered in Metamath. Even though it is tedious, it will usually actually save time and certainly much frustration with multiple false starts. I may do this on a plane or while waiting for a doctor's appointment.
- .
- Perhaps a concrete example might be helpful. Consider the theorem [alephfp], "the aleph function has a fixed point." I found this to be a reasonably difficult proof to do in Metamath. I scanned the page from the notes that I wrote down before entering the proof, which you can see here as [alephfp.png] (1700 by 2200 hi-res scan). (24-Sep-2006 - the corrupted png was fixed. -norm) This proof sketch, which is about the most detailed that I would ever do, has about half the number of steps as the Metamath proof. I do proof sketches this detailed only for the most difficult proofs. Note that lines 2-4 led down a false path, and you can see that I crossed them out (barely visible diagonal line) when I realized that. The big "V" through the middle of the proof is a giant checkmark I made when Metamath told me the proof was complete. I picked this one, by the way, because it is one of the rare cases where my notes are semi-legible. :)
{kind=link}
- Do you see the proof sketch in your mind's eye before typing anything?
- See above.
- Do you begin by asking yourself what is the "qed" assertion (i.e. working backward)?
- Actually, when I work the proof out on paper, I usually work forward. Basically, I'll have smaller subgoals of several intermediate pieces will be needed, and I tend to make fewer mistakes working forwards on those. On the other had, in order to identify the subgoals, I'll have either worked backward from the final theorem, or they will be proof steps in a textbook, each of which is like a little local lemma.
- .
- To obtain the major subgoals, I will often combine paper and the Metamath program, using the latter to do simple manipulations to get it in the form I need (rearranging antecendents, etc.), then using that as my subgoal to work out on paper when things start to become less obvious.
- What portions of a proof do you create using the computer? Are these "fill-in-the-blanks" steps primarily the propositional logic steps, with perhaps some predicate calculus identities thrown in?
- If I can "see" in my head how to prove a little local lemma or subgoal that I described above, then I'll often try to enter it (when I'm at that point in building the proof via the MM-PA CLI) directly without writing it down.
- How do you decide that a proof is too long (and why do we see these 100 or 200 step proofs – aren't there reusable components inside those long proofs)?
- Recently, I've tended to impose about a 1/2 megabyte limit on the web page size - bigger than that, and I tend to break it into lemmas. The big proofs very rarely have reusable components - if they do, it has probably already been broken out by a new utility theorem that was proved separately. Consider the really big proofs, the ones that may have half a dozen or more lemmas. Even though I try to pick "natural", self-contained subproofs for the various lemmas, they are rarely reused for anything else, and if you look at them you can see why - they tend to be long and specialized, and it's hard to imagine a use for them.
- .
- Assuming that there are no reusuable components, from a database size perspective it is more efficient not to break a long proof into lemmas, because there tend to be common subproofs and subwffs that aid compression, and there is the overhead of the lemma itself.
More questions if you don't mind:
In theory sub-goals could be input on the mmj2 PA GUI's Proof Worksheet as:
h1 |- blah blah hyp 1
h2 |- blah blah hyp 2
100:?: |- blah blah sub-goal 1
200:?: |- blah blah sub-goal 2
300:?: |- blah blah sub-goal 3
qed:?: |- blah blah final goal
The "?"s prevent the derivation step from being considered "in error" and thus prevent generation of a message (though the new Unify-Get Hints is specifically coded to output "hint" labels of assertions that unify with just the formulas of these steps).
So in theory, the working out of a proof could proceed using the mmj2 PA GUI by breaking down the problems and completing sub-goals in any desired order.
- But…is the process involving pencil, paper and manual symbol manipulation a necessary ingredient in your (human? :) proving activities?
- Probably. When I'm "thinking" about how to formalize a (nontrivial) proof, the biggest hurdle is often trying to figure out the informal textbook proof. Typically I translate the sentences into what the Metamath steps corresponding to them would look like. These become the subgoals. 5 sentences in a book might be 50 or 100 steps in a Metamath proof.
- Does use of ASCII shorthand symbols instead of the semiotically hardwired math symbols interfere with the creative process?
- No. Of course I picked the ASCII shorthand I liked, so this might not be true for everyone, who are stuck with my choices. On paper I'll often use an intermediate local shorthand like "r" for "rank", or a little box to represent a group of symbols I need to drag around but don't feel like rewriting.
- If you had a digital pad and stylus plus voice recognition software wired with grammatical parsing, unification searching (like mmj2 PA) and perhaps a dialogue module, would it be possible to not use pencil and paper? What if the digital pad were instead a huge electronic whiteboard equipped with the same software – or VR gear with a contralto vocoder?
- I have never been able to get used to inputting things on digital pad. But I also haven't made a concerted effort to do so. When PDAs were all the rage, my "PDA" was a little notebook and a pencil. I also can't "think" easily on a blackboard, like many people can. So my experience might not be a good example.
- Is the advantage of pencil and paper that you can scribble much faster than you can input math via the keyboard? OR is the advantage that you can write a formula's symbols on paper out of sequence without inconvenience?
- I think it is the latter, although probably little of both. I don't like writing out or typing long, tedious expressions. Example: the proof of grothprim was done entirely on the computer, letting the computer figure out the long expressions via unification. But there, I knew what the steps would be, since they are just expanding definitions. Someone naive looking at grothprim might think, "my god, what an incredibly tedious proof" when in fact it was one of the most trivial.
- .
- alephfp was extreme in the other direction. That proof was so frustrating for me, and I went through so many false starts due to mistakes in my rough sketches, that in the end I just brute-forced it, almost in anger, by writing out everything in such meticulous detail that it couldn't be wrong. And, in a funny way, writing out the details, even to the point of copying the same subexpressions from one line to the next instead of some shorthand like a box representing them, provided a subconcious excuse not to have to think so hard, providing mental breaks between the hard thinking. And possibly writing things out in such detail may have provided subconcious clues to the hard thinking via some kind of osmosis, who knows.
- .
- Thinking back to alephfp, why didn't I just type it in (say in an editor, forgetting about metamath for the moment)? I'm not sure. It just seemed more natural to write that one (and most of my sketches) on paper, which I could stare at and think through while pacing, etc. Also, the metamath ascii wears out my thumb (space bar) as Raph has noted. There have been proofs that I've done the sketches for in a text editor, sometimes using an abbreviated pidgin math (one letter per symbol, no spaces except to separate blocks whose parens might be omitted for brevity) invented for the one-time purpose of the problem. The editor lets me copy and paste subexpressions carried from step to step. But this is usually when I already know roughly what the proof will look like and just need a more detailed sketch; the hard stuff is always on paper initially.
- Is it true that – when you are "in the zone" -- that you are working at a sub-verbal level? That the formulas merely express your ideas? That the derivation steps make the lists of formulas conform to your thoughts and what you already believe to be true? (Granted some cases of discovery of truths seemingly embedded in the symbols – idiomatic shortcuts, say.)
- Answering your questions requires deep psychological introspection that eludes me right now. Perhaps I should just say, "yes".
- Is it generally the case that you work on families of related proofs in an area of math/logic…over a period of days or weeks? (Thus we can predict the benefits of a "current workspace" PA'ing metaphor involving most recently/frequently used symbols, sub-expressions, syntax and assertions.)
- I will tend to have a specific goal in mind, like proving every metric space is a topology, and this will naturally lead to all kinds of little lemmas from prop calc to the theories themselves that I discover I need but aren't in the database yet. The prop calc/pred calc/elementary set theory part has been stable for a long time, with virtually everything you would encounter in a logic/elementary set theory book and much more, and there are probably few new things I will add over time. Although surprises crop up occasionally.
- .
- But, given a goal, there are certainly specific areas in the database where I know to look for the previous relevant results. If I am trying to prove an inequality involving multiplication of complex numbers, I'm not going to be using the theory of ordinals.
- .
- Unlike what has been speculated, I have a poor memory for theorem labels, except for a small handful that are used all the time (ax-mp, bitr, eqtr, etc.). I do have a general idea of what's in the database and use the 'search' command with wildcards all the time to find out their names and their specific forms.
Also:
- Is there an overnight process involved in proving (for you) that involves subconscious problem solving?
- First, it is rare that what I put into the database is something that would be considered a "new result" in the sense that, for example, it could lead to a peer-reviewed publication (i.e. would be considered new and significant by mathematicians). I am just encoding existing knowledge. But given that, there are many, many proofs in the literature that are so sketchy that I have doubts that the author actually worked out the details. Or maybe the author did, in his/her head, and left the details as an implicit exercise/torture for the reader. Nonetheless, it is suprisingly rare (although not unheard of) that the final theorem being proved is actually wrong. It is almost like the mathematician is able to "see" that a theorem is true before proving it, and the proof is just a nuisance to be worked out in just enough detail to convince his/her colleagues. Sometimes I discover that there are additional assumptions that the author has left unstated, e.g. that a certain set must be nonempty for the theorem to hold. But in such a case, it usually is nonempty in the theorem's final application, so I don't know whether the author knew that it had to be nonempty for the theorem to hold and just omitted it as an irrelevant distraction. It can be an additional complication in formalizing the proof, though, since I may not know what the actual theorem will look like until the proof is worked out in detail.
- .
- Unlike most mathematicians, I often do not feel confident in my own proofs with the sparse level of detail that is typical. This can make me feel not as smart as them, and I am often in awe the things they are able to prove that way yet not make a mistake. Most computer programmers can't do this, since their programs almost always have bugs. (I know some computer programmers are mathematicians and vice-versa, and there seems to be something intrinsically different about the two activities. But deep mathematical proofs seem to have as many possiblities for error as a typical computer program, if not more, with subtle special cases where a statement may not be true and that can't be overlooked, and it amazes me that there aren't more errors. Something like Wiles' proof boggles the mind.) I think that many mathematicians have an ability to perceive things at a much higher level than I am able to, and this seems to be a talent that you are either born with or not. I am to able perceive things this way to a certain extent, since I obviously have to understand the proofs to formalize them, but it is often after much pain and hair-pulling. The whole point of Metamath was to try to bring this down to a lower level that people such as myself who aren't so gifted could understand, and the fact that a computer can "understand" it means, to me, that in principle I can too. But I digress…
- .
- To answer your question, among these subgoals are often problems whose proof initially eludes me, and those of course aren't in the book if each subgoal equals a book sentence. Often I can't solve them right away, and the answer will sometimes come the next day, almost automatically. When I first started set theory 12 years ago, the proof of pwpw0 was so frustratingly elusive that I went to the MIT library and looked in virtually every set theory book, and none of them had the proof worked out formally. It was always presented as an "obvious" step towards some other result. It's not that I didn't believe it - to me it was also "obvious," intuitively - it's just that I couldn't figure out how to formalize it. It was 5 days before I finally figured it out on my own, going to sleep each night thinking about it. Given the set.mm tools available at that point, it ended up requiring a very tricky (to me at the time) theorem of predicate calculus, exintr, that I'd never seen in a book and had to stumble across on my own. In restrospect, pwpw0 now seems trivial to me, and in the database its proof is currently reduced to 1 step (using another result). Perhaps I should put back my original proof for history's sake. (Later - for anyone who is curious, the original proof is still at the de2.metamath.org "archive" site: pwpw0. It is embarrassing to admit that it took 5 days to figure this out - you can see exintr in step 6 - but maybe it will help others who are struggling with formal proofs not to feel so bad.:) )
- The essential difference between computer programming and proving mathematical theorems is, in Metamath terminology, that a Metamath proof cannot modify the proof statement stack. – ocat 24-Sep-2006
- A minor nit. I might be misunderstanding, but it seems you're talking about imperative programming languages, or perhaps more generally side-effecting languages. For example, Haskell is a purely functional language, and has no side effects. If you are not talking about side effects, I'm not understanding. – marnix 28-Sep-2006
- The Metamath Proof Verifier maintains an hypothesis stack but cannot modify its instruction stack – the (RPN) proof statements. See http://en.wikipedia.org/wiki/Stack_automaton, "two-stack machine". The Metamath proof language is not Turing equivalent. It cannot loop, it cannot alter the instruction pointer, etc. A proof is a list of commands that is executed in a single, unalterable direction – just a long computation to compute the formula that is to be "proved". --ocat 28-Sep-2006
- A minor nit. I might be misunderstanding, but it seems you're talking about imperative programming languages, or perhaps more generally side-effecting languages. For example, Haskell is a purely functional language, and has no side effects. If you are not talking about side effects, I'm not understanding. – marnix 28-Sep-2006
- The essential difference between computer programming and proving mathematical theorems is, in Metamath terminology, that a Metamath proof cannot modify the proof statement stack. – ocat 24-Sep-2006
- Is there suffering and frustration until a proof is complete, or is the process "in the zone" where time disappears and no suffering exists? Or both, depending?
- There is suffering and frustration. Most of it is involved in figuring out how to formalize the original proof, independent of Metamath, which means the proof and all of its hidden assumptions and leaps of logic "left to the reader" must be figured out in complete detail and understood perfectly. Once that is done, for me the process of translating it to Metamath is pretty mechanical and not usually not very painful if painful at all. The things I hate the most is having to scrap and re-do a half-completed proof due to a logical hole I overlooked in the formalization. Of course, there is satisfaction and pride once the proof is done, and that provides a motivating reward. This feeling for me is deeper than the satisfaction that I get from say completing a computer program - since there can be no bugs, it is done once and for all, and I feel a sense of relief that I'll never have to worry about it again for the rest of my life.
- Do you ponder relevant issues during your "spare" time or while doing other things?
- Yes.
- Is it possible to "get anything done" in less than a few hours (i.e. the work involves immersion and construction of complex mental structures in RAM)?
- That depends. Long blocks of time are definitely more efficient, but I carry around a piece of paper with "subgoals" on it to work on as life's other activities permit. During these times, the thing that makes me inefficient is not having metamath/set.mm to browse for existing theorems whose name/form I forgot. A little handheld device the size of a calculator with metamath/set.mm/mmj2-browser on it would be handy at those times, if such a thing existed. A big problem with PDAs, for me, is the lack of a keyboard; I haven't been able to get used to that (or to those ridiculously tiny keyboards). But since a keyboard automatically implies greater than pocket size, such a thing may be physically impossible, so maybe someday when time/price permits I should try to put metamath on a Linux PDA and try harder to learn stylus input.
- I finally broke down and bought a used PDA on EBay (Palm Tungsten E) for
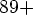 13 shipping, which came on Wednesday. This is the first PDA I've ever owned or used. I put a simple Metamath browser on it, and here is a screenshot. Now I don't have to lug my laptop around everywhere. I couldn't figure out how to put a symbol font on it, so I settled for ASCII, but that is adequate for what I need. It holds all 8300 definitions and theorems in 600KB, so there is plenty of room for future expansion (the PDA has 32MB). I'm still keeping my appointments in my little red book, since I don't really trust it yet. :) --norm 13 Oct 2006
13 shipping, which came on Wednesday. This is the first PDA I've ever owned or used. I put a simple Metamath browser on it, and here is a screenshot. Now I don't have to lug my laptop around everywhere. I couldn't figure out how to put a symbol font on it, so I settled for ASCII, but that is adequate for what I need. It holds all 8300 definitions and theorems in 600KB, so there is plenty of room for future expansion (the PDA has 32MB). I'm still keeping my appointments in my little red book, since I don't really trust it yet. :) --norm 13 Oct 2006
- I finally broke down and bought a used PDA on EBay (Palm Tungsten E) for
{kind=link}
- Do you like proving "just because" you like proving (it is sufficient unto itself, requires no justification and is its own reward)?
- I like seeing the goal and knowing that it has been rigorously confirmed. Once it is proved, I don't care that much about the proof itself anymore (other than being proud of knowing that I did it), except that the shorter it is, the happier I am with it, to reduce the size of set.mm. I don't really expect others to plow through my proofs except either to use as examples of how to prove things, or to convince themselves when they are stuck trying to figure out at a higher level how something is derived (which, from my own experience, can often be done just by looking at a few higher-level steps until you grasp the idea).
OK, Thanks for the information – it is useful stuff that I can apply to the task of writing the user manual/tutorial for the mmj2 Proof Assistant GUI. One conundrum I faced is that the mmj2 PA GUI provides no magic bullet, regardless of the number of tricks, hints and labor-saving features; the user still has to get into the mindspace, and there is no substitute for knowing the subject matter (which was never the intention, but rather to allow subject matter knowledge to predominate in spite of a lack of knowledge of Metamath statement labels.) I have several ideas about how to proceed (still procrastinating). A tutorial will use Proof Worksheet files: example001.txt, example002.txt, etc., and the instructional remarks will be comment lines in the Proof Worksheets. And I am pondering the idea of providing a set of exercises using the Natural Deduction approach adapted for Metamath (Hilbert style) – the completed proofs will then be re-verified minus the tutorial's "axioms" using just set.mm as a final educational experience! This will emphasize the necessity of knowing, say, propositional logic prior to proving propositional logic theorems. And I feel comfortable now in asserting that when learning a completely new subject a student is likely to experience discomfort and suffering, but that these emotions are typical, if not actually necessary!
--ocat 24-Sep-2006
Wanted: theorems, at least a few in peano.mm!
- I guess no one has volunteered yet, so I'll continue your request in the "Summary" line. norm 3-Oct-2006
I tested the mmj2 Proof Assistant with ql.mm, peano.mm and miu.mm.
The problem with miu.mm is, I believe, that the grammar is infinitely ambiguous – and theorem1's proof will not unify successfully, as is (I need to graph the syntax trees and nail this down, but note that "info" messages are produced during startup of mmj2.bat about the grammar, and I have examined the ambiguity of miu.mm extensively in the past and am not surprised to see the unification problem in action.)
- The MIU system, unfortunately perhaps, had a strong influence on the flexibility built into Metamath. While trying to figure out exactly what a "formal system" was, I was deceived into thinking that if it couldn't even handle the trivial MIU, how could it possibly handle "real" formal systems? My current feeling is that the substitution with empty strings that miu.mm requires is ugly and should be forbidden by the spec. The problem is that a lot of newcomers tend to be attracted to miu.mm because it's simple and, being Hofstadter-related, seems to have a certain coolness factor, and I'd hate to turn them away. So empty substitution will stay in the spec for that purpose, for the time being, but no one should use it in a new mm database.
- .
- In later years I have felt that the real essence or spirit of what Metamath "should" be is that built into the Metamath Solitaire applet, with a much more restrictive syntax (split into separate internal RPN and external human representation) that can still do everything in set.mm, but cannot do miu.mm or many other creative variations of $a's. Off and on I have been tempted to drastically revise the Metamath spec/program/database accordingly, but in the end have felt there is still a certain convenience to having the source file somewhat human-readable, which would be lost with RPN. Now of course there is Ghilbert, so it would probably be pointless to convert to the Solitaire method.
- .
- So, we currently have the somewhat "too flexible" original Metamath, and we have the more disciplined Ghilbert. But in a way it perhaps it is nice to have a choice, for the time being. It can be fun to toy with crazy $a's that people invent, and usually proving them inconsistent. :) And, it appears, people enjoy writing verifiers for it. --norm 3-Oct-2006
- The interesting thing for me about miu.mm is that if we remove axiom "wxy", the proof of the theorem still holds. This is the only extant example, AFAIK, of a provable Metamath theorem whose formula cannot be parsed. That topic/question was a real boggler for me back in 2004 :)
- .
- A possible project – or unsolved problem – for a Friend of Metamath is to create an unambiguous context-free grammar for miu.mm, whether or not it includes "empty substitution".
- .
- mmj2 deals with "Nulls Permitted" Syntax Axioms, which provide the syntactic mechanism for enabling empty substitution. For example, "nullWFF
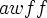 ." is a Nulls Permitted Syntax Axiom.
." is a Nulls Permitted Syntax Axiom. - .
- Metamath, as presently defined provides an excellent playground for both novice language designers and computer programmer/scientists -- not to mention "mathelogicians" of the Hilbertian variety (Bertrand Russell would have really liked Metamath, I am sure!)
- Imagine how he must have felt knowing that Principia Mathematica could collapse like a house of cards if there was even one slip-up or "bug" in the fragile tangle of theorems it was built on, with no way to verify it with certainty and requiring arduous human checking that at most would reduce the risk. In his autobiography he wrote, "My intellect never quite recovered from the strain of writing it."
- Therefore, I recommend leaving in place "empty substitution" in the Metamath spec and program, whether or not set.mm uses them. Null substitutions hold a solid position in the theory of formal languages – see: [ http://www.cs.vu.nl/~dick/PTAPG.html Dick Grune and Ceriel J.H. Jacobs, "Parsing Techniques - A Practical Guide" ]
- .
- In the manner discussed in the PTAGP book, mmj2 uses an algorithm to systematically eliminate null syntax constructions from the grammar it produces. However, a variety of the Earley Parser algorithm can easily accomodate null substitutions – though the language designer's task is not so simple!
- .
- BTW, Metamath.exe could easily derive the state value "empty substitutions on" by examining the input syntax axioms for formula length = 1.
- That's a very clever idea; I never thought of it. I'll add to my to-do list the automatic setting or even elimination of the 'set empty_substitition' command. Please don't patent it. :)
- --ocat 3-Oct-2006
The problem for the mmj2 Proof Assistant with peano.mm is that there are no theorems. I accept personal responsibility for never having invented any, but it would be great if one of Metamath's fans could write some! The interesting thing about peano.mm right now is that it uses prefix notation and it would be nice to see TMFF in action with prefix syntax.
ql.mm is not a problem. It gets little publicity but it works fine with the mmj2 Proof Assistant, and it is especially nice to have the Metamath English description of each theorem displayed on the mmj2 PA GUI screen.
--ocat 28-Sep-2006
Questions about EIMM.exe
1) A quick review of the source code for EIMM did not indicate that its Import function recognizes or stores mmj2 Proof Worksheet $d statements. Is that correct? Is it doable?
- That is correct. It is not doable at present, because the present MM-PA proof assistant has no concept of $d's, which have to be checked with normal proof verification. While I have a to-do list item for it, so far I haven't been motivated to put $d handling in MM-PA (particularly because it isn't a trivial retrofit the way MM-PA is written) because it hasn't been a significant problem for me (and might even be an impediment since I usually put them in "after the fact," not always knowing what they will be until the proof is done). It might be a problem for others; I'm not sure.
2) Is it true that EIMM can only import proofs for theorems that already exist in the input .mm database?
- That's correct. You have to be inside of the MM-PA session of the theorem being imported.
- I think it may be time for a utility for batch import of theorems and proofs, with $d's, etc. Could be a standalone utility based on the .mmp format. Could be a java program :) Or C. Or python…lisp…whatever. --ocat
- Yes, this would be nice to have. As with all such decisions (like whether to develop a full-blown IDE, etc.) I try to put things into perspective: in a practical sense, what are the time savings that the tool will buy over doing the task via a text editor, compared to the overall time spent developing a proof? Except for very simple proofs, most of the time I spend is working on the proof itself, and the time needed to place the theorem in the .mm file with a text editor is small by comparison. In the very long run, any automation will most likely pay for itself. But I am always torn between the time I have available to develop the content of set.mm and the time neeed to develop additional automation tools - typically I take the selfish approach of doing the latter when some repetitive task starts to annoy me. Hopefully, there will continue to be other people who enjoy tool development more than formalizing proofs, and I can benefit from their efforts, just as they can benefit from having the database developed further. --norm
- Perhaps a new project can provide the additional features the customers are demanding :) Adding new theorems and their proofs manually does not require a lot of time compared to actual creation/invention, but the limitations require explanation. The illusion is marred… Did you know that internally mmj2 actually creates theorem, log hyp and cnst "temp" objects but does not reuse them if the user goes on to create another proof – that is because the .mm database is not updated and inconsistency would create its own problems. A metaphor: the tropical garden patch near the swimming pool at our house… I spent a couple of hours pruning and cleaning it, generating half a recycling container of waste. After I was done no one noticed anything different! My work was of such high quality that I made the garden look exactly like it was supposed to look, therefore the changes were invisible to the eye of the casual observer. --ocat
- Yes, this would be nice to have. As with all such decisions (like whether to develop a full-blown IDE, etc.) I try to put things into perspective: in a practical sense, what are the time savings that the tool will buy over doing the task via a text editor, compared to the overall time spent developing a proof? Except for very simple proofs, most of the time I spend is working on the proof itself, and the time needed to place the theorem in the .mm file with a text editor is small by comparison. In the very long run, any automation will most likely pay for itself. But I am always torn between the time I have available to develop the content of set.mm and the time neeed to develop additional automation tools - typically I take the selfish approach of doing the latter when some repetitive task starts to annoy me. Hopefully, there will continue to be other people who enjoy tool development more than formalizing proofs, and I can benefit from their efforts, just as they can benefit from having the database developed further. --norm
- I think it may be time for a utility for batch import of theorems and proofs, with $d's, etc. Could be a standalone utility based on the .mmp format. Could be a java program :) Or C. Or python…lisp…whatever. --ocat
3) Is it possible to execute EIMM for Export and Import via a batch command file? If so, can provide example statement? That would be a great feature for regression testing!
- If I understand you correctly, I think so. For example, the manually typed:
...
MM> prove a1i
MM-PA> submit eimmexp.cmd
...- can be put into a complete metamath session on one line of a batch command file, thus:
metamath "r set.mm" "prove a1i" "submit eimmexp.cmd" "ex" "ex"
- (I haven't tried this but I assume it will work.)
- OK, thanks. That works. I'll have to try the eimmimp.cmd version – (note to self: remember to add the "save"). --ocat
- Don't be shy about changing the .cmd's themselves, or creating your own, if it would be beneficial; they are just scripts to let metamath talk to the actual eimm program. 'eimm --help' describes the usage of the eimm program itself, which normally isn't - but could be - used on a standalone basis. Note that in a .cmd, a line in quotes is sent to the OS, although I try to avoid that since it makes the script OS-dependent. The metamath 'tools' command can do limited file manipulations to achieve some OS independence. --norm 10-Oct-2006
- OK, thanks. That works. I'll have to try the eimmimp.cmd version – (note to self: remember to add the "save"). --ocat
4) Is it possible to modify EIMM to not produce all of those work files, and to just have it operate in memory – this behavior clutters up the user directory. If not, can it tidy up after itself?
- It currently needs work files, since it is outside of the metamath program and it "talks" to metamath via the metamath 'submit' command, which reads in a file, and metamath "talks" to it via logged output (show proof, etc.).
- .
- A possible solution would be to add it as native metamath commands, in which case intermediate files could theoretically be avoided. But I don't have time to do that right away, and anyway I want to accumulate some eimm experiences (such as the one you are reporting here) before making that big a change to the metamath program. For example, your report will provide a motivation for keeping all work internal.
- .
- As an intermediate solution I can have it delete the temporary files when done. Also, maybe I can add a '/silent' qualifier to 'submit' to suppress the screen output. I'll look at that.
- .
- The old versions of the proof worksheet are renamed to ~1, ~2, etc. instead of deleted. I personally would prefer to keep those since such "journaled" files have allowed me to recover work countless times. They can be periodically purged with 'rm *~*' (or the equivalent in Windows). But if people feel strongly about it, maybe I could add a '/no_journal' qualifier to 'open log' and eimm.
- --norm 9-Oct-2006
--ocat 8-Oct-2006
Yahoo Interstellar Time Capsule
I would have submitted Metamath's set.mm and ql.mm but the Yahoo page for this project required Flash software, which I abjure for security reasons.
If anything deserves to be beamed into the cosmos, it is Metamath's set.mm database, which is one of mankind's most beautiful works of epistemological glory. I have no doubt that aliens would be able to decipher the Metamath .mm file format, which is self-defining and is capable of constructing logic and math from first principles. (I suspect they would struggle with the $d statements though :)
Would someone do the honors of informing Yahoo about their most qualified new "astronaut"?
--ocat 11-Oct-2006
Identity card
I have added a Metamath identity card http://en.wikipedia.org/wiki/Metamath in the spirit of what exists for wikipedia http://en.wikipedia.org/wiki/wikipedia. As you can notice yourself it's not terrific. Any idea ? I find the Octave identity card particularly nice (http://en.wikipedia.org/wiki/GNU_Octave). – fl
Mirrors
The mirrors are no longer updated . Something broken ? fl
I usually keep them updated about once a week, although it slipped recently due to a problem with the AU mirror that has been fixed. I will try to update the mirrors in a day or so. I don't update them more often (e.g. daily) because the rsync's bring my home network to a crawl. – norm 31 Oct 2006