(back to mmj2)
(The MetamathOMDocBridge is now just a gedankenexperiment but there are many things in OMDoc that can be stolen for mmj2…)
Any input, feedback or desired enhancements please input here (bitches about mmj2 go in the usual place :-)
A primary goal of this release will be to make mmj2's Proof Assistant work a lot more like Metamath.exe's. In addition, certain preparations can be made to clean up, modularize, and expose interfaces so that more help can be provided in the Proof Assistant in the form of automated proving "assistance" (a generalized prover is probably far beyond what I can reasonably accomplish within a realistic timeframe, but there are things that need to be done to clear the way for even a stupid, brute-force solver.)
Any proposals? Feedback? Users all happy as-is, and prefer no change?
I. MAKE PROOF ASSISTANT GUI "DERIVE" MORE LIKE metamath.exe
1. Handle $d errors in a more sophisticated way.
At present the mmj2 PA GUI treats all $d
errors as equally severe -- the error
messages are different but the resulting
action (error!) does not distinguish
between $d errors resulting from (1) a
violation of a Ref'd assertion's existing
$d restrictions, and (2) the case where the
theorem being proved merely lacks $d
restrictions of its own (to "inherit" the
$d's of assertions it references in the
proof.) The former case (1) is a "hard" error
that could only be eliminated by modifying
the Ref'd assertion whereas the latter (2)
probably just means that the user needs to
add $d restrictions to the theorem being
proved.
A. Create a "generate $d's" mode, enabled by
RunParm and a menu option to automatically
generate $d statements for type 2 $d errors
when the proof is complete. The generated
$d statements will be inserted in the Proof
Worksheet at the end of the generated RPN
proof to ensure that the user sees them.
Also, provide an option to generate "all"
or just the extra $d's to be added to the
theorem being proved.
The RunParm is
ProofAsstGenerateDjStmts,Yes,All (or Diff)
will be the new default setting. The generated $d statements will be
"compact", meaning that the program will
attempt to build the fewest number of
separate $d statements needed to express
the pair-wise $d restrictions
(e.g. "$d x y", "$d x z" and "$d y z"
compress to "$d x y z").
B. At present the PA GUI unification search
for a unifying Ref label (when not input
by the user) accepts the first unifying
assertion it finds. If the found Ref has
a $d error the search continues for another
Ref without $d errors. In the new and
improved PA GUI the search will NOT accept
a Ref with a "hard", Type 1 $d error; it
will accept a "soft", Type 2 $d error. In
either case, the search will continue
and a better match (no $d errors) will be
automatically accepted.
C. At present the PA GUI validates an input
Ref for $d errors and if the input Ref
label has a $d error, a message is produced
showing alternative assertions. This
behavior will continue except that
alternative Ref's will be reported only
if they actually reduce the $d error severity
or eliminate the $d error completely.
D. For testing purposes, a new RunParm (utility)
command will be created to derive $d's for
one or all theorems and then compare the
generated $d statements to the original
input. In the case of "all", the utility code
will proceed from first principles, thus
catching cumulative $d over-specification
problems (and coding errors.)
2. A "?" in the Hyp sub-field of "Step:Hyp:Ref" will no
longer be required to invoke the Derive Feature --
when a Ref label is input. If Ref is input on a
Proof Step and the number of Hyps input is fewer
than the number of Logical Hypotheses used by the
Ref'd assertion, then Derive is invoked to generate
the missing hypothesis steps.
A value of "?" is *permitted* and will be treated as
an omitted Hyp when Ref is entered. Thus, if the
Ref'd assertion requires three Hyps and "1,2,3,?"
is input in the Hyp sub-field, the "?" will be
ignored (and stripped from the output display on
return).
In the current processing, the PA GUI is very
particular about the user entering the correct
number of Hyps for a Ref. This obsession with
accuracy is annoying and even causes confusion
because sometimes the user may not know whether
the Ref'd assertion has 0, 1 or 2 Hyps.
(It will continue to be a severe error if the Ref'd
assertion requires 'n' logical hypotheses and the
Hyp contains more than 'n' Hyp numbers.
Also, note that the use of "?" in Proof Step
fields is not consistent at present. A "?" is
not required if the user doesn't desire to
enter a Ref, and a "?" is not required in the
Formula if the user desires the Derive Feature
to generate the Formula.)
Thus, after enhancement, the only real use of
"?" on a Proof Step will be in the Hyp sub-field
of a Proof Step that is not ready for Unification.
In this case the user leaves Ref blank and the
"?" Hyp sub-field indicates an "Incomplete"
step status. An Incomplete step can be used
as a Hyp for a subsequent step even if *it*
does not contain complete Hyp numbers itself --
this *feature* facilitates piecemeal proof
development, top down, bottom up or mixed.
3. Make generated Proof Asst GUI "dummy" variables
valid, typed "Work Expressions" and modify
the unification algorithm to handle Work
Expressions correctly.
Presently, when the PA GUI "Derive" is used and
the user-input "under-specifies" the set of variables
used by an assertion and its hypotheses, the PA GUI
creates "dummy variables", "$1", "$2", etc., where
the "$" prefix is specified by RunParm
'ProofAsstDummyVarPrefix,$'.
One problem with these "dummy variables" is that
they are not treated as variables by the PA GUI
when the Proof Worksheet is re-edited. Instead
they trigger a severe error, such as "invalid token".
Another problem is that even if "$1", "$2", etc.
were successfully parsed as variables, in
metamath.exe they are treated as expressions, that
can be expanded or assigned values. For example $11
could be assigned the value "( ph -> ps )" and
this value would be used throughout the proof
in place of each occurrence of $11. And
metamath.exe can treat $11 as an expression
during unification (try proving syl in metamath.exe
and notice that the dummy assigned to the ax-mp
step's "maj" and "min" hypotheses is then split
when a2i is assigned to the "maj" step). In mmj2
the initial $11 dummy could not participate in
the a2i assignment because mmj2 treats it as
an indivisible variable, not as an expression
(or sub-expression).
A. Create new 'ProofAsstWorkExpr' RunParm
allowing the user to specify the names and
the numbers of generated "work expressions":
'ProofAsstWorkExpr,wff,W,99'
-- signifying up to 99 allowable work
expressions of type "wff": W1, W2, ... ,
W99. Note that the generated variable
names must be valid Metamath variable
names and not conflict with any other
user-defined variable names.
B. Internal to the program, work expressions
will be treated as a special kind of
variable, one which has extra information
attached. Prior to actual assignment of an
expression's value, a work expression will
be displayed with its value = its name; thus,
W1 is shown as "W1" on the Proof Assistant GUI
screen. After assignment, and assuming
a valid assignment not generating unification
or syntax parsing errors, a work expression's
display is *expanded* to display its assigned
value everywhere the work expression occurs
on the screen. Furthermore, the PA GUI
will "discover" that work expressions are
present in a Proof Worksheet and processing
will ensue in an appropriate manner (described
below, and in more depth later...)
C. Create new feature allowing the user to assign
values to work expressions. For example, the
user must be able to assign "( ph -> ps )" to
W1 and have that change reflected in every
occurrence of W1 in the Proof Worksheet.
This requirement can be met with a
Search/Replace feature. Assuming that more
sophisticated enhancements involving manipulation
of sub-expressions in a proof are not implemented,
a simple Replace will be adequate. Whether or
not a full-blown Find/Replace dialogue is
implemented is perhaps a matter for the
programmer to look into. All that is really
needed is the ability to select a work expression
(variable name), right-mouse click and select
"Replace", then accept the input replacement
tokens and apply the changes; the user can use
Undo if the changes are unacceptable.
With respect to matching criteria, the option of
complete token matching instead of exact character
string matching might be provided. Thus,
replacing "( ph -> ph )" would replace the given
five tokens if the occur in sequence with the
input token sequence. This option would be handy
given that formulas can be reformatted -- and
given that one would not want to replace "W11"
when intending to assign a value to W1.
Idea: these "work expressions" can be thought of as "macros", or as "sub-formulas". I guess we're all familiar with a math text that uses them like this: let g = (xy/z) then we have f = g**2 + 5. Or somesuch. I propose to allow the PA GUI user to declare/define work expressions as part of a Proof Worksheet – not simply to generate them during the Derive function's process. This would be similar to metamath.exe's "let" command, 'let $1="( ph → ps )". To make this work I would create a new sub-menu devoted to work expressions. The "assign" menu option to assign a value to a work expression variable name would actually create a line in the Proof Worksheet:
@WFF1 = ( ph -> ps )
or $w WFF1 = ( ph -> ps )
or
*@WFF1 = ( ph -> ps )
The last variation creates a Proof Worksheet Comment statement. The other variations might require a modification to eimm.exe.
The beauty of the idea of creating a new Proof Worksheet statement for work expression value assignment is that it uses the Proof Worksheet text area as a sort of memory. After entering the "@" command (or whatever we label it), the user hits Ctrl-U for Unification, and if the result is unsatisfactory, he uses the Undo menu option and is able to alter the work expression value assignment.
There are other possibilities for work expressions on the proposed sub-menu. One is the idea of a formula "compress" function that seeks out repeated sub-expressions in the Proof Worksheet and replaced them with work expression variables. That would mean, if "( ph → ps )" is repeated in several places, the "Compress" function would replace each occurrence of that sub-expression with "WFF1", a work expression variable name. The compression could be triggered for sub-expressions with syntax >= 2 levels deep (or 3.) Then a formula "Expand" function could reverse the compress function and replace each work expression variable name used in the Proof Worksheet with its assigned value. Would this make "grothprim" easier to understand? I doubt it…much.
What do you think? Any alternatives or variations?
D. Unification processing in the case where a
Ref label is present, (either user-input or
from a previous unification,) must be changed
not just to create Work Expressions instead
of dummy variables, but also to handle
existing Work Expression present in the
formulas being unified. The case where the
PA GUI searches for a unifying Ref is related
but more complicated and will be dealt with
elsewhere.
Example: assume proof step 3 is as follows
when the user presses Ctrl-U to Unify:
3::a2i |- ( W1 -> ( ph -> ch ) )
Since a2i's formula is
|- ( ( ph -> ps ) -> ( ph -> ch ) )
Unification using the old algorithm would
reject a2i as not unifiable. But instead
it now must recognize that W1 is unassigned
and instead of matching the W1 subtree to
find substitutions to ph and ps to make
their subtree identical to W1, it must
assign "( ph -> ps )" to W1 and then
proceed in the normal fashion using the
assigned value of W1 *as* the content of
W1 and any of its input hypotheses -- each
subsequent occurrence of W1 in step 3 and
its hypotheses would, during unification
be unified using the new value,
"( ph -> ps )". After successful unification,
W1 would be replaced in the output with the
new assigned value...BUT if unification
fails then W1 must be left unchanged in
the Proof Worksheet.
In effect then, W1 operates as a constraint
on unification, like a wildcard search
parameter in the original formula.
E. Unification processing in the case where a
Ref label is not present, where we are in
effect, trying to derive the Ref label,
presents difficulties and opportunities
when Work Expression (variables) are
present in the step being unified -- or
in its hypotheses. The unification search
process could return many unifying
assertions within the contraints imposed
by the Work Expressions -- and the first
match found during the search will not
necessarily be correct. The problem is
like solving a system of equations with
multiple unknowns!
Therefore, during "normal" Unification
processing formulas containing unassigned
Work Expressions will not participate
in the Unification search. They will be
given a status of "Incomplete-Unassigned-
Work-Variables".
However, the "Unify+Get Hints" menu option
can, logically, be modified to generate
"hints" about unifiable assertions that
match a formula containing Work Expressions.
4. Do not generate an incomplete proof step in the
"New Proof" function. The generated proof step,
which looks like
3:?: |- ?
is annoying and is most often just deleted by
the user. It was originally intended to clue
the user that another step is probably
required somewhere between the hypotheses and
the "qed" step.
At the very least, make it a comment step
that doesn't interfere with subsequent
unifications:
*3:?: |- ?
II. MAKE USE OF INPUT DEFINITION AXIOMS
1. Formally represent Axiom subclasses: SyntaxAxiom,
DefinitionAxiom and LogicAxiom.
A. existing RunParms "ProvableLogicStmtType" and
"LogicStmtType" will be utilized during input
file loading. Thus, any .mm database author not
using "|-" and "wff" (the defaults) needs to input
the "ProvableLogicStmtType" and "LogicStmtType"
RunParms prior to the "LoadFile" RunParm.
B. New RunParm "DefinitionAxiomLabelPrefix" will be
added, with default 'DefinitionAxiomLabelPrefix,"df-"'.
2. Discover and formally describe definition links in
an input .mm database file.
A. Perform iff new RunParm "DiscoverDefinitions,On"
is input (the default is "On" in the new release.)
B. new RunParms "equalitySyntaxLabel" and
"biconditionalSyntaxLabel" will be added to avoid
hardcoding -- with defaults as follows:
equalitySyntaxLabel="wceq"
biconditionalSyntaxLabel="wb"
C. Link "defines" will be created in Assrt
(Assertion) for use by DefinitionAxiom and Theorem
pointing to 0 (null) or 1 SyntaxAxiom. The defined
Syntax Axiom may be either a Named Typed Constant
or a Notation Syntax Axiom (not a Nulls-Permitted
Syntax Axiom). A defining DefinitionAxiom or
Theorem may not have any associated Logical
Hypotheses but may have Distinct Variable
Restrictions (if any such definitions are input by
the .mm database author the occurrence will be
flagged with a warning message but processing
will continue without the definition.)
D. List "simpleDefinition" will be created
in SyntaxAxiom pointing to 0 -> n Assrt (Assertion)
objects. Definition links will be present only on
NamedTypedConstant and Notation Syntax Axioms. The
type of the defined object may be logical (i.e.
"wff") or non-logical (i.e. "class), and *by
convention* will be the left hand child of the
defining Assrt, whose root node must be either the
biconditional or the equality syntax axiom.
E. In theory (pun intended), a Prover algorithm
ought to be able to use valid simpleDefinitions
to create valid derivations. One method that
might be used is:
1) discovering an occurrence, "E" of a simply defined
Syntax Axiom, "S" in a formula, "F";
2) unify expression "E" (which has the defined Syntax
Axiom as root) with the left-hand side of the
defining Assertion, "D".
3) If unification is successful, apply the unifying
substitutions to the right-hand side of D and
replace E with the substituted right-hand side of
D (the unifying substitutions make E identical to
S -- there will be none when the defined Syntax
Axiom is a NamedTypedConstant Syntax Axiom.)
4) NOTE: if the right-hand side of D
has more variables than the left-hand side do not
apply any substitutions to the under-specified
variables -- output them as-is. The reason is
that these "extra" variables must be bound
variables within the right-hand side of the tree
and logically will not conflict with other uses
of the same variable names within formula F. If
this is not the case then the definition itself
is not valid -- and that is the author's problem,
not the program's (and eventually the error would
come out during proof verification...)
5) The converse operation, finding an expression "E"
that unifies with the right-hand side of D and
replacing E in F with the substituted left-hand side
of D is also possible (computationally expensive,
but perhaps faster than wandering randomly in the
forest...)
F. A Syntax Axiom that has no defining
DefinitionAxioms is implicitly defined by
LogicalAxiom occurrences and is given the attribute
"primitive" = true in class SyntaxAxiom. Examples of
"primitives" are implication ("wi") and negation
("wn") in set.mm.
G. A "primitive" Syntax Axiom may have,
theoretically, defining Theorems; this is not
disallowed.
H. A DefinitionAxiom that does not
match the simpleDefinition pattern but which
-- likewise -- has no Logical Hypotheses and
contains one or more occurrences of a
"primitive" syntax axiom will be considered an
"implicitDefinition" of the primitive Syntax
Axiom in its formula with the highest sequence
number (this specification relates to the
process of discovery -- and will be a
convention.) In set.mm only "df-bi" meets this
criterion. The defined Syntax Axiom will then
be marked "primitive = false" (i.e. we will
perform discovery in input file order and
assume that the DefinitionAxiom applies to the
most recent un-defined ("primitive") Syntax
Axiom used in the definition.
I. List "implicitDefinition" will be
created in SyntaxAxiom pointing to 0 -> n
DefinitionAxiom objects. Definition links will be
present only on NamedTypedConstant and Notation
Syntax Axioms. The type of the defined object may
be logical (i.e. "wff") or non-logical (i.e.
"class).
J. In theory, a Prover algorithm ought
to be able to use valid implicitDefinitions to
create valid derivations. One method that might
be used is:
1) discovering an occurrence, "E" of an implicitly
defined Syntax Axiom, "S" in a formula, "F";
2) unify expression "E" (which has the defined Syntax
Axiom as root) with S, thus obtaining a set of
substitutions for the variables used in E for S
(which will make S == E after substitution).
3) If unification is successful, apply the unifying
substitutions to implicit definition formula "D"
thus generating formula "D'".
4) Create derivation formula by
.1 Outputting D' as a complete formula
and/or
.2 ?
5) NOTE: if D has more variables
than S, do not apply any substitutions to the
under-specified variables -- output them as-is.
The reason is that these "extra" variables must
be logically bound variables, and logically
ought not conflict with other uses of the same
variable names within formula F. If this is not
the case then the definition itself is not valid
-- and that is the author's problem, not the
program's (and eventually the error would come
out during proof verification...)
III. CODE TIDY-UP / TINY FIXES
1. Provide a "terse/verbose" RunParm option for
output of "info" messages by mmj2 (these are
different than the error messages and are
output to a separate file/stream):
VerboseInfoMessageOutput,No (the default)
In particular, direct "logging" type info
messages, such at the logging output as
each RunParm is processed to the "verbose"
category. (Error messages will remain
verbose :-0)
2. Add support for input Apple line ending character
sequences in mmj.mmio.Tokenizer.java. (Line
endings on output are O/S dependent, since mmj2
uses Java's "write line" commands.)
Line endings are used when reading a .mm file
solely for line counting, so that error messages
can be assigned a location within the input.
Presently, mmj2 supports Unix (CR) and Windows
(CR-LF) sequences, but does not support Apple/
Mac (LF).
The current algorithm is imperfect, in the sense
that it doesn't take into account the host
O/S when detecting line endings. That is, it
*assumes* that a matching sequence of line
ending characters is intended to signify a
line's end. Any mixture of line endings within
an input file is accepted (e.g. xCRyCRLFCRz
would be countedd as 3 complete lines and a
partial line containing "z".)
3. Provide a "mmj2jar" download containing just the
bare minimum for running mmj2 -- as was done
prior to the 1-Nov-2006 for user testing -- in
addition to the full "mmj2" download.
This should be slightly less confusing than the
current packaging, which provides "mmj2jar"
as a sub-directory of "mmj2". I myself use mmj2
as follows out of the mmj2jar directory:
cd mmj2jar
mmj2
In addition, in the event that a bug-fix needs
to be applied, it will be much easier for users
to just get an updated version of mmj2jar.
The full download will contain mmj2jar and will
contain the documentation, tutorial, etc.
4. Make the inner classes of ProofWorksheet
standalone classes.
Initially they were envisioned as simple data
structures but over time grew into beasts
containing code that obfuscate matters
unnecessarily.
5. Split ProofWorkStmt.status into separate "status"
variables, one for each sub-status. (This should
be totally invisible to users...)
The present "status" serves multiple needs and
originally was envisioned as a sort of "milestone
marker" on the path to unification and proof
generation. But combining multiple status values
into a "combo" code value is nearly always a
mistake (in fact, this status field has caused
at least two bugs because it makes the Proof
Assistant code even more inscrutable...)
6. Speed up processing of RunParm "ProofAsstFontFamily",
which seems to take nearly as long as verifying
every proof in set.mm! The problem is in
mmj.util.ProofAsstPreferences.validateFontFamily()
which does a
GraphicsEnvironment.
getLocalGraphicsEnvironment().
getAllFonts();
The program then scans through every returned font
looking for a matching font family name -- if not
found it returns an error.
It would probably be faster to just attempt to
build a font using the input name, as is done in
mmj.pa.ProofAsstGUI.buildProofFont(). If any error or
exception occurs *then* go through the old verification
logic and generate the appropriate error message -- and
if no error occurs, just return the input font family
name, "trimmed".
This will save at least 1 second start-up time, and
probably 2 seconds!
Discussion and Some comments
I would applaud improved $d handling in mmj2. BTW there are really 3 categories of $d errors, "soft", "medium", and "hard". :) The soft errors are omissions of $d's on dummy variables used by the proof.
Some verifiers do not check for soft ones - e.g. Ghilbert and, I think, hmm - because their authors disagree with the Metamath spec and feel that $d's on dummy variables should be implicit. I have mixed feelings, but so far I have felt that "implicit $d's", even though they make the database slightly more compact, would philosophically complicate the spec and introduce another concept that the user must learn. But the fact that I don't show $d's on dummy variables in the web page display (I used to, and took them out in recent years to simplify the display) shows that I am torn about this issue.
- I will follow Metamath on this one and generate, as requested, the $d's for dummy variables, not treating them differently from other variables with respect to "soft" errors.
As for generating the missing "soft" and "medium" $d's, that would be fantastic. BTW it would be nicer if you don't just output a list of pairs - the list would be enormous for some theorems - but compact them into groups of 3 or more where possible. For this to be useful, you would want to do this in the mode that regenerates all $d's, not just the missing ones, for the user to use to replace the existing $d list. The metamath program does this recombination for its "show statement" and web page displays; the algorithm starts at line 205 in mmcmds.c if you want to glance at it to get a rough idea. My algorithm is not always optimal, but is "good enough", being optimal AFAIK for all existing cases in set.mm. But I may refine it some day - line 209 notes a pathological test case where my algorithm is not optimal.
- Right. I planned to generate "compact" $d's. --ocat
- I hope I understand what you are speaking of. I think there is an ad-hoc algorithm to generate $d n-uplets. (1) you put all the dummy variables together. (2) you consider all the other variables and you try to generate the better n-uplets you can (3) you add the list of dummy variable to each of the newly created n-uplet.
- The interest of this algorithm is to remove most of the variables in order that the problem in most cases become trivial.
- Obviously the generated conditions are often too strongs but very often it's not important. However the user must be conscious of the way you do the work because sometimes it can lead to errors. – fl
- The code will (1) collect missing $d pairs by collecting the "hard" errors generated in VerifyProof?; then (2) build consolidated list of $d restrictions ("all" or "diff"); (3) compact the consolidated list. I will also write test code triggered by an optional RunParm? to re-derive all $d's from the axioms' $d's, but it too will use the empirical method involving the output of VerifyProof?. There will be no bugs. --ocat
There is another complication with the $d list - it may affect multiple theorems in its scope, and you'd ideally want to ignore existing $d's already specified at outer bracket levels - this gets to be a really messy problem to do optimally. It's up to you how far you want to go. I'd be happy if you just focused on theorem at a time, but keep this in mind if they find a cure for mortality, and you find yourself bored 100 years from now…
- mmj2 builds Frames at the statement level and does not retain the original scoping information. For the few cases where the user has outer scoped $d's, the "diff" option for generating $d's may come in handy (assuming that the outer scope $d's are correct. --ocat
As a general comment, I am glad you are looking at whether anything can be done to improve its startup speed. For the metamath program, one trick I used was reading the set.mm file as a single binary object instead of a line-by-line text file, which was about 100 times faster in C, or at least the older C I used when I wrote the program. This made the startup time (including reading and error-checking set.mm without proof verification) almost instant. I don't know how much is intrinsic to Java vs. how much has to do with the algorithms you use (you do syntax analysis that the metamath program doesn't).
- There are new Java options ("NIO") for speedy file reading, and it might be that using your method would be somewhat faster. That portion – the reading in – is not the major bottleneck, though it is not instantaneous. The slowest task is syntax parsing, followed by proof verification (excluding validation of font family name :) I find it interesting that subsequent start-ups run faster, so a good part of the elapsed time is Java itself – and I think part of the disk data is loaded into virtual memory. I don't know if you recall, but the change to enable mmj2 to read compressed proofs speeded up the load by a lot! That was because compressed proofs require fewer input tokens, so yes, doing the input with the Metamath approach would probably be a speed-up. --ocat
Also regarding startup, fl and myself would both like to see a "brief" mode by default where only real errors are shown in the startup messages, with the details of what's going on only shown in a "verbose" or debug mode.
- There is an option to send the non-error messages, the "info" messages to a file instead of the screen. But since I did not make this the default option, it doesn't get used. However, I will bow to the request. I think the main grievance is the log output as each RunParm? command is processed, and that is easy to remedy with a "verbose/terse" option (default to "terse" :-) --ocat
– norm 29-Mar-2007
Command line suggestion
Another thing related to startup - could certain things be provided as command-line options? It is a nuisance to have to edit the parameter file just to have it, say, skip proof verification for speedup when we know it passes, or to specify a different database. I suppose a script could be written to do this with the existing setup, but it might be nice if it was provided (either directly or as a script) with the standard release. E.g. mmj2 --noverify --db=ql.mm, or some such. Perhaps mmj2 --nogui would just do verification, report any errors, and stop. And mmj2 --help to list all available command-line options. This needn't control all possible parameters, just a few commonly used ones, and more could be added as time goes on – norm 30-Mar-2007
- The author's intention was that a user would have clones of mmj2.bat and its RunParm? (command) file, with one variation for each Metamath file and set of options. So you could have a "mmj2set.bat", "mmj2setnv.bat", "mmj2ql.bat", etc. Assuming that the code can be made into something of sufficient quality and merit that you use it constantly, I believe you would find that having multiple .bat (.cmd) files is preferable for daily use – and in the case where you are running a lot of quick variations, it is easy enough to keep a text editor open and repetitively dink with the RunParms?. I think my preference now is to do these other enhancements and then if everything is looking good consider bold new approaches to the start-up sequence. --ocat
fl, regarding the "work expressions", the plan is to emulate metamath.exe's proof assistant and allow the user to enter only Ref labels – in reverse order – to complete a proof. The amount of typing is minimized, though the user is burdened with having to know the labels (but can use a separate metamath.exe screen to do searches.)
I am thinking that it is more clear to call them "temp variables". That is because the existing mmj2 doesn't work quite right and its "dummy variables" – $1, etc., are not treated by mmj2 as actual variables. These will be actual variables, conforming to the metamath.exe syntax requirements for variable names (like WFF1, WFF2, whatever.)
The thing is, once mmj2 creates one of these things in the Derive function, it becomes part of the language of the Proof Worksheet – that is, we have to consider allowing the user to enter a "temp variable" manually as part of a formula, and the program has to deal with their presence. Also, metamath.exe has a 'let $1 = "( ph → ps )"' command allowing the user to assign a value to a temp variable, and that will be needed to assure a satisfactory user experience.
So now, we have a new language feature, and the question is what will be requested next to make it "well rounded" – meaning, what will a user expect to be able to do with temp variables, regardless of mmj2's petty authoritarian disciplines? I'm guessing that the user will want to have a menu option for assigning a value to a temp variable, as well as a "select" text followed by right-mouse click menu option "assign" – and I think the user ought to be able to just assign a value in the proof text, like this:
@ WFF1 = ( ph -> ps )
where "@" occurs in column 1 of a line. That will store the assignment command in the proof text, thus making it "undoable" / "redoable".
But "well rounded"? What about going the other way? What if the user "select"s a sub-expression and wants to assign it to a temp variable…and then replace every occurrence of that sub-expression throughout the proof with the temp variable name? Is that helpful? And then the inverse operation will be wanted, to "expand" the proof formulas, replacing temp variables by their assigned values.
Are there other features that might be useful (before I start coding and we can experiment with this?)
--ocat 3-Apr-2007
It's difficult to say what might be useful: that sort of thing is very incremental in fact. But emulating the way Metamath automatically replaces temp variables by subformulas as soon as possible is a great feature. In my experience it is the only reason why using mmj2 may be boring.
Concerning the undo/redo paradigm I have come across a "pattern language" that I have found very interesting. A class is attributed to each command that can happen in the buffer (deleting a line, replacing a variable, generating the hypotheses…). As soon as the user makes something in the buffer an instance of the class representing the command is stored on a stack with the associated data (the content of the buffer in fact or a difference between the ciontent before and the content after) so undoing and redoing are really easy. This pattern can be found on the internet. I don't remember where.
To tell the truth I'm a unix user. I know that you are a windows one. But I'm not convinced that the menu paradigm is very good. When you use a software a lot, clicking on a menu again and again can get tedious very quiclky.
Is it interesting to replace a sub-formulas by a temp variable ? I would say no because in a certain way it can be very dangerous.
May I suggest once again (I know I shouldn't) that multi-tabbing can be a relatively simple feature to implement and it can allow us to find new good ideas for mmj2.
– fl 4-Apr-2007
More rambling thoughts to take or leave
1. The unification algorithm in the metamath program is necessarily imperfect because its paradigm of imposing no grammar, in order to allow for the full generality of the spec (for better or worse). In other words, the user sometimes has to tell it which unification to select from several possibilities while the proof is being built. But mmj2, because it works only with databases that impose a grammar, has the big advantage that unifications are always unambiguous, in the sense that there always exists a unique "most general" unification between two wffs, mod variable naming, if they can be unified. I don't know enough about the internals to know if the algorithm for this is in there (if not, the algorithm exists in the MM Solitaire applet, as I've mentioned before). It might be worth thinking about how this could be used in the context of fl's remarks.
2. One idea to help assign unknown wffs might be to have a "wff select mode" where the smallest complete wff (or class expression) containing the user's selection will automatically be highlighted for copying, analogous to full-word selection in a word processor. This could be pasted over an unknown wff variable selected by the user, or a subwff of them if they unify with the original copied selection.
3. If things are done right, I wonder if it might be possible, in principle, do an entire proof with no keyboard entry at all (analogous to MM Solitaire but of course far more sophisticated). One thing I (don't think) mmj2 has now is the ability to select a theorem or matching theorem from a drop-down list (or tree?) analogous to MM Solitaire (which shows the user only legally matching axioms at any point).
4. There is a distinction between the $1, $2, etc. type variables, whose source is the referenced theorems, and the "fixed" variables in the theorem to be proved, which aren't really variables but behave like constant symbols. The variable variables (or "unknown" variables) of course change over time as they are unified with other wffs, assigned by the user, etc. I am still confused by relationship between the $1, $2 type variables and the proposed WFF1, WFF2, etc. Is WFF1 just an abbreviation for an arbitrary user-selected subwff? Can it contain "unknown" variables, e.g. ( ph /\ $2 ), that will be invisibly updated automatically when an assignment is made to $2 somewhere in the proof (by a user assignment or by a unification)? BTW the variables you see in MM Solitaire are really $1, $2, etc. renamed P, Q, etc. for friendliness; there is no such thing as the "fixed" variable names of the final theorem.
5. Personally, I can be less efficient trying to work "forward" (as in MM Solitaire and to a certain extent mmj2) than working "backwards" (like in MM-PA). Part of this, of course, is simply due to being used to it in MM-PA. But the "backwards" approach keeps track of the wffs that must match the final theorem, whereas with the forward approach there might be some accidental slight difference e.g. a right- instead of left-associated conjunction that prevents it from matching the final theorem. Kind of like the cartoon where two teams building a railroad track from opposite ends meet at the wrong rail. In the forward approach, you need to be very, very careful to correctly assign the subwffs you need, perfectly and without typos, or the whole thing might have to be redone. I think for an optimal prover we would want to implement both approaches well. In the backwards approach, while you can't exactly be sloppy, things sort of work themselves out to "tell" you what you need next. Interestingly, on my sketches on paper I often have little subproofs that work "forward" to a missing piece that I need, combined with arrows and circles around the final theorem to roughly indicate how things fit together. One area where I work forward a lot is in proofs involving negation and contraposition - even after many years, I often find proof by contradiction difficult because the intermediate steps don't seem natural. – norm 4 Apr 2007
- In my experience too working "backward" is the normal way to make a proof and working "forward" is a less frequent option used to finish a proof. However this less frequent option can be very useful to experiment what sort of formulas we can expect to generate from a theorem or another. There is also something else that can be dangerous. I don't remember exactly but it seems to me that working "forward" leads to make very contrived theorems (using variables replacement or other unnecessary things). --fl
Norm:
OK, here is grist for your mill, I won't respond to your ideas at this time as I want to consider them carefully…
(1) "I am still confused by relationship between the 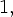 2 type variables and the proposed WFF1, WFF2, etc. "
2 type variables and the proposed WFF1, WFF2, etc. "
- They are the same things, except with different names. I want the "work variables" (?if that is good nomenclature) to satisfy Metamath's requirements for variable names, so therefore they cannot begin with "$". Also, I want the names to provide a clue to the user about the Type of variable. The wff work variables could be "ph1", "ph2", or whatever is chosen by the user on a (proposed) 'ProofAsstWorkVar?,wff,W,99' RunParm? which would generate W1, W2, … W99.
(2) "Is WFF1 just an abbreviation for an arbitrary user-selected subwff? ? Can it contain "unknown" variables, e.g. ( ph /\ $2 ), that will be invisibly updated automatically when an assignment is made to $2 somewhere in the proof (by a user assignment or by a unification)?"
- Yes, WFF1 could be any sub-wff (though it must be parseable into a sub-tree – "ph → ps )" would be an error. I haven't completely ruled out "nested" work variable assignments, but on top of the need to validate them to ensure that they have no cyclical references (loops), I don't know if there is any benefit to offset the complexities. Work variable sub-expressions containing references to other work variables sounds appealing, and would be part of a "well-rounded" solution (for a user with an IQ of 350 these might be essential, though to me they have the same potential that an electron microscope would have for the job requirements of a seeing eye dog…)
- .
- Another question about them is when the assigned values are "bound" to the work variables. I think fl is right that as soon as a proof step is unified with a Ref label, and the "unknown" work variable's contents become known, that the new value should propagate throughout the Proof Worksheet, replacing each occurrence of the work variable. So if formula F is "|- ( WFF1 → ch )" and F is unified with, say, "syl", then every place WFF1 occurs in the proof will be replaced with, say, "ph", and WFF1 will no longer appear in the text of the Proof Worksheet. I think that is what the user would rightly expect to happen – the knowns replacing the unknowns as we progressively solve the problem. The end result will be a lot like a spreadsheet in that after propagating the assigned value of WFF1, the updated formulas will/may need to be re-unified (and the order the formulas are processed by the program during the unknown work variable stage may need to be strategized…)
--ocat
Norm, you were right about a "work variable" assigned value being able to refer to another work variable. This is an inescapable result of the new unification algorithm. For example, suppose we have Assertion "A" (which is in the database, the formula is arbitrarily chosen here to illustrate the point):
|- ( ( ph -> ps ) -> ( ch -> th ) )
And Step 3 is to be unified with A in a proof step. Here is step 3 just prior to the user hitting Ctrl-U to unify the proof:
3::A |- ( WFF1 -> ( ch -> th ) )
After unification, step 3 will look like this:
3::A |- ( ( WFF2 -> WFF3 ) -> ( ch -> th ) )
and WFF1 will now have the assigned value
@ WFF1 = ( WFF2 -> WFF3 )
Then, any occurrence of WFF1 in other proof steps would be replaced by "( WFF2 → WFF3 )". The tricky thing is that WFF1 cannot simply be assigned "( ph → ps )" because ph and ps are not determined by this unification; their meaning in assertion A may be completely different that their meaning in this context, so they are undetermined, and receive their own "work variables".
- I hope we aren't making the concept of "determined" vs. "undetermined" more complex than it needs to be. Essentially, the final theorem to be proved should be treated like a string of constants, and the "ph" in the final theorem would be treated no differently from a "named typed wff constant". The only "variables" are those that arise from the theorems referenced by the proof steps, i.e. the WFF1, WFF2, (or $1, $2,) etc. These evolve (become more specialized) as the demanded by unifications as the proof progresses, eventually becoming completely "determined" i.e. replaced by wffs containing only these effective constants. I think this is probably what you mean but wanted to clarify it. When you say that the ph in a referenced theorem "receives its own work variable" this is meaningful only prior to unification; as soon as two referenced theorems are unified, all such work variables in both theorems may vanish to be replaced by more specialized expressions containing new work variables. – norm
One question I have is whether or not the user will actually need to be able to do the equivalent of metamath.exe's "let" command. In theory the user could just manually type in any assigned work variable values – and in the normal case for experts like you and fl, manual entry of work variable value assignments will never be necessary, you will just enter Ref labels and build the proof bottom-up (the undetermined variables will be determined by the unification algorithm as you enter the Refs.)
- At a minimum, a "let" equivalent is needed to specify dummy variables in the proof. But I also use it sometimes to help me see my intermediate goal better especially in complex proofs, even though theoretically the proof itself will eventually determine it when the proof is completed. – norm
- In metamath.exe, the "let" command is necessary because the user cannot directly modify formulas displayed on the screen; only commands can be entered. The mmj2 PA GUI text area is just a big text blob and in theory the user could just replace WFF1 with the desired value (including the Edit/cut, copy, and paste features provided). So is a separate "let"-type command really needed?
- No. What I meant by "equivalent" included a GUI equivalent. I assume, though, that if the user replaces WFF1 with the desired value, it would be smart enough to automatically replace all other WFF1's with the same thing at the same time. This is what would be "equivalent". Actually, anything else wouldn't make a whole lot of sense, since a text-editor type replacement of only the WFF1 occurrence that the user highlights could make the proof step unifications become inconsistent. – norm
- Or a search/replace feature?
- Well, I think what we would need would essentially be that. If you change one WFF1, all the others one the screen should presumably change instantly at the same time. – norm
- Because how often is it necessary in metamath to manually enter a "let" command? --ocat 6-Apr-2007
- I wonder if this "big text blob" design doesn't bring more problem than it solves. If you adopted (?) a "command oriented" design you could implement an undo/redo mechanism easily for instance. I see only two qualities to the "big text blob" design: (1) you can have several independant proofs in the same buffer (2) you can add extra comments everywhere. But I'm not sure these advantages are worth the difficulties the "blob" design brings. And I'm not sure either wether these features couldn't be implemented in a "command oriented" design. – fl 6-Apr-2007
- I don't know what you mean by "command oriented" in this context. A fully GUI-ized approach, say with tables or a tree, or something, might offer advantages – but complexities of its own. The "big text blob" approach has advantages also. One thing that might not require a total rewrite of the GUI code in mmj2 would be using an HTML text blob instead of a plain text blob. Also, I might work harder at gaining contextual awareness of the mouse location so that step-specific commands could be easily added (e.g. put the cursor on a certain line and press F8 to …. do something for a specific step). One thing I like about the text blob approach is that the Proof Worksheet is a language and is not tied to the programming or GUI environment, and in theory a Proof Worksheet could be transmitted to a server for processing by any server who knows the language. Also, you know, mmj2 is doing some pioneering stuff, and other approaches may come later to correct its deficiencies. Perhaps a Smalltalk Proof Assistant will win the blue ribbon… :-) --ocat
- Well in fact what I have in mind is "vi". In "vi" there are three modes: the first one is the "big text blob mode". In this mode when you strike "d" then d is inserted in the buffer. The second mode is the "command mode", in this mode when you type "dd" for instance the line under the cursor is deleted. The third mode is the "command line mode". There is a line at the bottom of the window where you can type full commands and edit them (for instance you can type "1,5s/gg/hh/" and it will substitute "gg" by "hh" in the first five lines of your buffer. For the moment, mmj2 uses a mixture of "big text blob mode" and of "command mode". I think the "big text blob mode" shouldn't exist. Allowing the end user to modify the buffer leads to problems. The buffer should be frozen in some way. I think you should develop the "command mode" and that you should add a "command line mode". By the way mmj2 considers that the buffer is a set of characters. "vi" considers that the buffer is a list of lines. I think it is more appropriate to consider that your buffer is a list of lines. Because it allows you to code commands that move them, delete them and son on. Obviously what I'm describing is the most outer interface. I haven't read very carefully what Norm has written but we can consider that the device he describes would be a middle layer that interacts with this outer interface. By the way I hope that you use object-oriented design ? – fl 7-Apr-2007
- I don't know what you mean by "command oriented" in this context. A fully GUI-ized approach, say with tables or a tree, or something, might offer advantages – but complexities of its own. The "big text blob" approach has advantages also. One thing that might not require a total rewrite of the GUI code in mmj2 would be using an HTML text blob instead of a plain text blob. Also, I might work harder at gaining contextual awareness of the mouse location so that step-specific commands could be easily added (e.g. put the cursor on a certain line and press F8 to …. do something for a specific step). One thing I like about the text blob approach is that the Proof Worksheet is a language and is not tied to the programming or GUI environment, and in theory a Proof Worksheet could be transmitted to a server for processing by any server who knows the language. Also, you know, mmj2 is doing some pioneering stuff, and other approaches may come later to correct its deficiencies. Perhaps a Smalltalk Proof Assistant will win the blue ribbon… :-) --ocat
- I wonder if this "big text blob" design doesn't bring more problem than it solves. If you adopted (?) a "command oriented" design you could implement an undo/redo mechanism easily for instance. I see only two qualities to the "big text blob" design: (1) you can have several independant proofs in the same buffer (2) you can add extra comments everywhere. But I'm not sure these advantages are worth the difficulties the "blob" design brings. And I'm not sure either wether these features couldn't be implemented in a "command oriented" design. – fl 6-Apr-2007
- In metamath.exe, the "let" command is necessary because the user cannot directly modify formulas displayed on the screen; only commands can be entered. The mmj2 PA GUI text area is just a big text blob and in theory the user could just replace WFF1 with the desired value (including the Edit/cut, copy, and paste features provided). So is a separate "let"-type command really needed?
A feature such as a new Proof Worksheet statement type, like:
@ WFF1 = ( ph → ps )
is a "nice to have", but it adds a fair amount of complexity to what is already the gnarliest, gnastiest bit of code I have ever been guilty of perpetrating…(right now I am re-engineering the Proof Assistant code for simplicity – but that is just so that I will be capable of re-adding the complexity right back in…)
- I am still confused by @ WFF1. There are two concepts. The first is like the "let" command: WFF1 is replaced with ( ph → ps ) throughout the proof, and WFF1 itself simply disappears, being no longer needed. The second is that WFF1 acts like an abbreviation for ( ph → ps ) but stays visible as "WFF1" in the proof itself. Which concept do you mean? If the former concept, I don't see how this would be much more complex than reusing the existing substitution mechanism already in place for unification. If the latter concept, would all existing occurrences of ( ph → ps ) be replaced with "WFF1" on the screen? – norm
- I am primarily focused on the former – during unification the program updates all formulas with the assigned work variable values and displays the revised formulas on the screen. So if WFF1 has been assigned a value, either with a "let" type command, or by unification with a Ref'd assertion, then WFF1 disappears from the screen. Most of the complexities in this scheme/concept are internal to the program.
- .
- . Regarding the latter concept, my idea was that there could be a command (and its inverse) to display (or undisplay) work variables – as you mentioned '( ph → ps ) be replaced with "WFF1" on the screen'. So with this, the user could enter a "let" command and then use this hypothetical command to show the work variable in place of the "let" assigned value; then unification would reverse the display and make the work variable go away. I'm not sure just how handy this latter concept would be – I am pretty sure the user would expect to see work variables disappear as progress is made towards proof completion (and fl is probably right that coloring portions of a formula is the most desired enhancement…) --ocat
Perhaps a simple Search/Replace command on the edit menu would be almost as good?
- I am wondering if this comment suggests that maybe we have the wrong paradigm in mind; see my comments that immediately follow. – norm
--ocat 5-Apr-2007
I'm am not sure that the present paradigm of the user area being allowed to be an unconstrained text blob is the right one. I like that it has the "look and feel" of a text editor, giving the user the flexibility of having expressions formatted the way they want, commented as they like, and so on, and hopefully this can be retained. But I don't think that arbitrary edits should be allowed in the way they are now. Ideally, only edits that, after they are made, keep the proof-in-progress consistent should be allowed. If an edit can't be made, the user could be told why perhaps with a right-click selection. The goal should be that no error messages can occur after an edit is made - i.e. no inconsistent partial proof should be allowed on the screen. And when edits are made, such as replacing a work variable with a more specialized expression, everything affected by it should instantly be updated on the screen - not with a separate ctrl-u step.
I really think that if the right underlying paradigm is chosen, it can be relatively simple, with what I just described happening more or less as an automatic by-product. The main user-interface complexity would be preserving its behavior as "almost" a text editor, but the text on the screen would map to a much simpler underlying structure than the one that I vaguely sense growing in complexity (although I am guessing since I don't really know), and the main purpose of the interface between the screen and this underlying structure would be to keep the mapping always consistent. The user would have complete editing flexibility - adding new-lines, tabs, etc. - as long as that constraint is not violated.
The underlying structure of the paradigm I have in mind is actually almost exactly like the one in the present MM-PA, except that it is automatically more powerful to due its having a grammar (like MM Solitaire). The unification algorithm could be exactly that of MM Solitaire, which is relatively simple. If the user doesn't specify any "let" assignments (or its GUI equivalent), then what you see would be almost exactly what results in MM-PA after an "initialize all" and "unify all" sequence. The user can specialize the display by let-equivalent assignments (via pasting, etc.), but underlying it all would be the unique "most general" representation of the proof-so-far. The user should be able to "un-let" any ill-chosen assignments to recover more generality, or then reassign them, or even re-initialize the whole thing as in MM-PA's "initialize all".
A difference from MM-PA is that there can be isolated subproofs, but even these are no different from what would result in MM-PA with the dummylink mechanism - i.e. everything would be "work variables" until specialized by the user.
I can think of a number of neat features that could eventually be added that would fit very naturally into this paradigm. A "paste over wff" feature would allow e.g. ( WFF1 → ps ) to be pasted over "( ph → WFF2 )" if the result unifies. This would result in "user assigments" of WFF1=ph and WFF2=ps. You could have a pull-down menu with all of the user's let-equivalent assignments for alteration or deassignment. The user could ctrl-click the result of an isolated subproof then an unknown proof step, to merge them together if they unify. You could copy a subproof then duplicate it elsewhere as a new isolated subproof, with all of its variables turning into "most general" work variables - then attach it to a matching unknown step - very handy for repeated subproofs e.g. to satisfy the substitution hypotheses of tfinds. Overall I could envision it as being a powerful GUI extension of the present MM-PA model. I don't think we should overlook the power of that model. As crude as the command-line MM-PA may seem, it can't be denied that it has been very successful and quite efficient for at least one user. :) In particular, not being allowed to do things that are illegal (can't be unified, etc.) - rather than an error message after the fact - I think can make proof entry more efficient as well as help new users learn faster.
Perhaps all of this is actually what you already envision, and I'm just putting it into words - I'm not sure. But no matter what is chosen, I do think it is worth trying to have a single, conceptually simple underlying "engine" onto which GUI features can be added naturally and not just as hacks. – norm 6-Apr-2007
(Later.) I'm not being sure how much I should write on this - perhaps this isn't the model you want at all - but let me just say something about the underlying data structure I had in mind. There would be 3 arrays stored in memory:
"most general" --> proof-in-prog. --> screen
proof-in-progress w/ user assignmentsI'm assuming the MM Solitaire unif. alg., complete with $d handling, would be used.
Note that a separate user assignment list is redundant; it can be computed by unifying the "most general" proof with the user-assignment version. If this list is empty, these two proofs would be the same.
The screen would be represented by a map from each symbol in the user-assigned proof to screen characters: e.g. "ph" might map to "space space ph return tab comment". A certain amount of optional "AI" could be applied when wffs change as the proof is built: e.g. comments could be reattached to a nearby symbol if the original one vanishes, so they won't get lost. But this is a luxury; even without such prettiness the various nice proof formatting algorithms you already have should suit most users and needs.
I believe it can really be that simple - 3 arrays in memory (m.g. proof, user proof, screen) would contain essentially the complete information that is needed. The GUI would simply do various manipulations to these 3 structures, with no operation allowed that destroys a consistent connection between them.
In principle you wouldn't have to store the the wffs corresponding to proof steps of the m.g. proof, since they can always be computed. The user proof could be equivalently replaced with a user assignment list, although you might need to keep the user proof in memory to more easily map to the screen. When the proof is complete, of course we will have m.g. proof = user proof. Well, with the exception of dummy variables, that must be user-assigned. – norm
Norm, your 3-array approach has induced an idea in my mind. An exciting idea it is too. I believe I comprehend most of what you are suggesting, though your proposed mapping to the screen and the associated UI is fuzzy – given your initial nod to making the GUI feel like a text editor, but just not allowing the user to enter anything impermissible … haha… (I know, pull-down menus…)
- I'm not sure why you think it is fuzzy, but I think it can be precisely defined. One internal symbol to one symbol on the screen, surrounded by optional whitespace. How are the symbols on the screen currently mapped to their internal representation?
First my idea :-) Your 3-array approach is definitely related to the mmj2 "hint" feature which provides a list of assertions whose formulas could unify with a given proof step's formula.
For proving, we could repeatedly 1) get hints; 2) build 'n' new proof sub-trees using each hint (Deriving the hypotheses by applying each hint to the given step), 3) attempt to match generated hypotheses to the theorem's hypotheses; 4) repeat 1->3 until ? proof magically found…
Here is the gist of the idea: in '1) get hints', at each iteration there will be n*m steps requiring "hints"('m' hypotheses for each hint). So instead of doing the unification search one step at a time, at each iteration we make a single pass through the database and do them all!
Thanks to your economical design it should be possible to examine quite a few proof sub-trees in memory before running out of space – and the forest would be pruned if a "hint dead end" is reached for a proof. This approach to proving would really lend itself to parallel computations on a multicore processor too!
It would also be possible to generate "hints" using the to-be-proven theorem's hypotheses, so that possible proof sub-trees could be generated top-down, and maybe meet the bottom-up sub-trees somewhere in the middle.
Of course, in the real world of set.mm the number of sub-trees would grow exponentially -- into the billions, even, very fast.
But we could do some searching for proofs anyway…a few levels.
There could even be a Metamath@home program to dole out the proof searches across the planet (finally, those Microsoft machines will do some real work…)
About your overall scheme though, that is not possible for mmj2 in my available timeframe now. Even if it were, I would not modify mmj2 in that way, but would keep it available as a reference (for bootstrapping other work). Your scheme then, would be a new program.
Also, I think your approach is elegant but it is an Authoritarian approach. My concept -- which is represented in the mmj2 PA GUI – is that the users are free to write anything they want, and the program "dialogs" with them about what they write.
- Regardless of the underlying implementation, we may agree to disagree on whether an "Authoritarian" approach is better. In the "dialog" scenario, the user types something, separately checks for errors, the dialog points out any errors, the user goes back and corrects them,… My gut feel is that this isn't the most efficient way, and I can't see any point or purpose to allowing the user the freedom to enter something wrong in the first place, since they'll have to go back and correct it anyway.
They do not need to progress towards a solution; they can work from the top down, bottom up, and middle out, or none of the above.
- With the Authoritarian approach, the user can also work from the top down, bottom up, and middle out, or none of the above. The only difference is that the assorted pieces of the proof would always be consistent with no worries about typos (only "thinkos"). I can't think of any feature that would be lost by this approach. While I accept that what I have suggested may not be feasible for mmj2, I would still be interested in anyone else's opinion on Authoritarianism vs. the unconstrained text editing of mmj2, for future consideration. – norm 6 Apr 2007
It is much like the Blackboard Paradigm, except that the 'qed' step is a fixed point (based on the assumption that somehow arriving at a proof is the goal).
- I would say the Authoritarian approach is also a Blackboard Paradigm, but with an automated blackboard. Rather than forcing you to erase and rewrite a wff you want to change throughout the proof (=global search/replace in the "dialog" approach), if you paste over a work variable, the rest of the proof would automatically change as well in order to keep the structure consistent. No need for the separate step of doing a manual global search/replace. And, as I mentioned, you could paste "( WFF1 → ps )" over "( ph → WFF2 )", which would require 2 global search/replaces with the dialog approach. Generalize that to compound paste overs with complex unifications. – norm 7 Apr 2007
One neat feature of the mmj2 PA is that once the 'qed' step if unified the generated Metamath RPN proof contains only the essential steps from the mmj2 Proof Worksheet – the "islands" of derivations are just ignored, and that is not an error….
- That is good. :) – norm
But back to what I am actually doing…I am busily doing "simplicity engineering" on mmj2 right now. I started with the totally compatible changes so that I can regression test with the existing version. Once I get things squared away then I will do the $d soft/hard error enhancement and make mmj2 use real "work variables" instead of the dead dummy variables it uses now. Then I will put a trial version up here in the "mmj2jar" download file for you all to experiment with. I think you will find that it mimics the MM PA to a great extent, at least with respect to entering assertion labels bottom up to enter a new proof. I might even hold off on the "let" command equivalent so that we can see how things look before venturing off and maybe doing something that isn't to your satisfaction. Unofficially, I am planning a June 1 date for upload of the trial version – which is basically a fix-up version, and then we'll see. Thanks to your input and fl's input I think I have enough insight to proceed on a good path.
--ocat
- I applaud to your decision to replace dead variables by work ones. It's certainly the most desirable feature to add to mmj2. – fl
P.S. Norm, you have given me an idea about how to test the new unification algorithm (using work variables).
- What unification algorithm are you using? If it is "home-grown" you may be risking incorrect behavior in pathological cases and/or speed inefficiency, especially if it is the "ad hoc" sort that is developed and refined by trial-and-error on test cases. A good test for both are the ones here, where small input expressions blow up to thousands of symbols: big-unifier.in and big-unifier.out. One reason I bring this up is because an early algorithm I did, before I was aware of the literature, had to be "fine-tuned" as I found more and more cases where it didn't work, becoming more and more complex, and even though it seemed to work in the end, I was always uncomfortable about it. The algorithm in MM Solitaire is based on a standard algorithm for condensed detachment invented by Peterson. A recent algorithm (2006) that is supposedly efficient, and also seems to be described clearly, is here: "Yet another efficient unification algorithm". It also has some references to earlier unification literature. – norm 10-Apr-2007
- It appears to be a case of apples and oranges. They appear to be looking for a 3rd formula, a MGU – Most General Unification -- of 2 formulas (terms).
- I don't think it is apples and oranges at all. An MGU is exactly what you should be looking for. If not, I am fearful that you are looking at this in the wrong way and may be going down the wrong path. See my comments at the end of the page. – norm
- In my case, I am looking to unify step S with database assertion A – and create a set of substitutions.
- When step S consists of 100% work variables, this "set of substitutions" is (or should be) a set that creates an MGU.
- The only "pathological" case in my unification algorithm (which may not be the most efficient…) is when the order of the logical hypotheses does not match that of the database. I use heuristics to minimize the chance of an N! combinational explosion (where N is the number of logical hypotheses – set.mm has one theorem with 19 logical hypotheses!) I suspect they are also explanding expressions/constants into the underlying primitives, which we do not do – a constant either matches or it doesn't, we make the proof do the proof…so to speak. --ocat
- It appears to be a case of apples and oranges. They appear to be looking for a 3rd formula, a MGU – Most General Unification -- of 2 formulas (terms).
To pass the test, my program must be capable of successfully unifying and reconstructing every proof in set.mm given only the RPN list of logical assertion labels for each theorem (plus the formulas of each theorem and its logical hypotheses.) So, for syl the RPN input is "syl.1 syl.2 a1i a2i ax-mp", and it should be able to construct the full Proof Worksheet – and reconstruct the original set.mm RPN proof. If it can do that then we also know that in theory we could really compress Metamath proofs :-) There is a bonus problem here too, which would make an excellent exercise: to code the search algorithm to efficiently traverse the forest of possible assertion label RPN lists and generate a proof (it is impossible to do every proof in reasonable amount of time, but the fun/trick would be to code efficiently to search as much as possible and find some proofs within a given time limit -- without any hardcoded knowledge of propositional logic, set theory, etc., just pure Metamath.) The ideal approach would employ parallelism, such as using one pass through the database for each subsequent level deeper into the forest. --ocat 7-Apr-2007
Yes, what you have described is MM Solitaire's algorithm, and that is exactly what I had in mind (although I seem to have communicated it poorly). Essentially, the grammatical parsing that mmj2 has (which the Metamath program lacks) will allow you to reconstruct the internal Polish notation used by MM Solitaire, and from that point you can use MM Solitaire's algorithms - even its exact Unification class code if you want (since you are using Java), although I won't claim it is the most optimal code possible.
MM Solitaire came well after Metamath, and in a sense is more "advanced" - it is really more than just the simple toy that you see on the surface. It was meant to be a "reference implementation" for the unification algorithm it embodies, with a vague intent to be used in more advanced proof assistants or even to revise the Metamath language itself for a more compressed database, as you suggest.
As for compression, I looked at this a while back and checked it again today. (This is done by entering MM-PA, 'delete floating', and 'save new/compr', then removing all ?s from the output file.) The compressed proof for projlem7 (a large proof) reduces from 2277 to 562 characters, or about 75%, which is nice. However, the overall the size of the current set.mm reduces from 5.53MB to 3.72MB, or about 33% - not the huge savings I had hoped for, mainly because because many proofs are already not much longer than their theorem+description. It does make the larger proofs in set.mm a little more pleasant to scroll through in a text editor, though. (Later… I determined that with all proofs deleted completely, set.mm is 2.69MB. -n)
I suggested this approach to Raph as a possibility for Ghilbert, but he was worried that the verification speed for the whole db might be slower, since computing substitutions with unification is inherently slower than directly constructing them in the proof itself. (He also felt that unification detracted from the conceptual simplicity of Metamath.) But for a working on a single proof, I don't think unification speed is an issue. – norm 7 Apr 2007
I have 2 thoughts, in ascending order of seriousness, beginning with the nearly whimsical:
- 1) Eliminating the syntax labels from the proofs is a form of extreme database normalization :0-) If formulas were stored as syntax RPN's and proof were stored without any syntax labels, then the database contents would be relatively immune to syntax changes – as well as Metamath's quaint convention of stacking hypotheses in database order. In any case, if it were decided to include the proof step formulas in RPN format to speed up unification, most of the same "syntax invariance" would be obtained (I'm not sure what would be lost, possibly nothing.)
- 2) (this is more serious…) It would be interesting to construct a database of repeated subproofs – where only the non-syntax labels are included in the proof sub-trees (e.g. syl's proof = "syl.1 syl.2 a1i a2i ax-mp"). A "sub-tree" is any complete sub-tree of a proof tree extending down to the leaf nodes. This database of repeated non-syntax label sub-proofs might be very useful in proving. For example, suppose that proof step 'S's formula can theoretically unify with 'n' assertions. Then we go to the repeated sub-proof database and pull out the existing subproofs that terminate in the 'n' different possible assertions – before trying to invent a new sub-proof we use these subtrees as candidates for proving step S (with our work variable assignments). --ocat
(norm:) Re (1): In principle, the only thing that would be lost would be the variable names chosen to represent dummy variables used by the proof. However, here is one reaction to my suggestion that the language be changed, from a 24 Feb 2007 email:
(norm:) … Off and on, I have considered a major revamp of the Metamath language to use the MM Solitaire approach, although that probably won't happen.
(correspondent:) Don't do it! :) The MM language should stay as an "assembler language", with add-on programs to translate to and from it.
(norm:) One advantage is that the proofs would be shorter since the syntax construction steps don't have to be specified.
(correspondent:) "Shorter" is not "better" - that mistake is what led to CISC winning out over RISC. ;)
(norm:) Raph also looked at the MM Solitaire unification method for his Ghilbert language proofs… [but] he was concerned with proof verification speed using unification, and he found a clever method for specifying wff constructions that is much more compact than Metamath's non-compressed notation.
(correspondent:) Part of the reason I plumped for Metamath over, say, Ghilbert was that it can work (and in the case of set.mm, does work) with "traditional" syntax, making its proofs more familiar to mathematicians. LISP's syntax [or RPN/Polish] is elegant but unfamiliar outside the fraternity.
(end of email excerpt)
- Yes, RPN is good! --ocat
- .
- igblan AKA Paul Chapman was the correspondent, and has now joined the Wiki.
- .
- Welcome, Paul! (BTW you can check the "This change is a minor edit" box for cosmetic changes to prevent them from showing on the RecentChanges page.) – norm
A program can use any representation of an MM db it wants or needs for speed, internally or even translated to an external file if speed is an issue, since it isn't a big deal to reformat it given the mmj2 parser. Incidentally, is that parser a self-contained part of the mmj2 program? If not, it might be nice to "package" it for general use. It is the important "missing link" between an MM db and an MM Solitaire-type representation that could have other applications.
- People seem to enjoy writing their own parsers. As I predicted, Metamath is a treasure trove for computer science students :-) Even more popular than Spring Break in Fort Lauderdale.
- .
- FYI, the mmj2 Earley Parse implementation is tied to the mmj2 object hierarchy in "LogicalSystem?". And the parsing code has some quirky things – not my best work :0-) However, there are several ways to "repurpose" it. One way is to write a new module for "BatchMMJ?2" and trigger it via a RunParm? command. That means that with almost zero work a new program can have available to it a fully loaded, proof-verified, parsed Metamath database in memory, ready for … whatever. The BatchMMJ?2 "RunParm?" language makes it very easy to add-on or reconfigure how mmj2 runs. It would be possible therefore to simply invoke a different Proof Assistant. Or, an obvious solution is to write a translator module -- which could spit out all of the parsed formulas in RPN or S-exp's… Anyone needs a "consultation", just ask… --ocat
- There is a relatively new parser called the packrat parser. I wonder if it would have any advantage over Earley Parse. --norm
- According to the paper it trades increased space for faster speed. A gotcha is that it cannot handle ambiguous grammars – unlike Earley. The fun part of doing this, whichever algorithm is chosen, is that the grammar must be constructed from the input file – unless the user chooses to handcode a parser for a specific file (which may be a viable approach.) --ocat
- There is a relatively new parser called the packrat parser. I wonder if it would have any advantage over Earley Parse. --norm
BTW, since you probably mean "quaint" as a euphemism for something else, :) what ordering would you consider more natural?
- The most painful thing is that some syntax axioms have a different hypothesis order than the order of the variables within the formula, and that means extra code to test and resequence. It is probably too late to change Metamath now though, since there are so many programs written to the spec. --ocat
Re (2): For even more generality, the hypotheses in "syl.1 syl.2 a1i a2i ax-mp" can be unspecified. Just as there is a unique most general theorem that results, there are unique most general hypothesis that may be more general than the $e's in the db. For an example of how this works in MM Solitaire, see this example, which coincidentally is also syl.
As a general comment on what you are proposing, what advantage would there be in trying to match the "pattern" in syl's proof? Why not just match syl itself (or rather the "most general" result of the pattern - which in this case is syl itself)? Wouldn't that be faster? Or is that actually what you mean - creating a temporary db with all possible subproofs in set.mm, compute each subproof's "most general" result, then scan the collection as if it were the actual db? This sounds like fun and might be an interesting experiment, although my gut feel is that the payback may not be quite as good as you might expect. But who knows. – norm 8 Apr 2007
- The interesting part of the subproof in syl would be the "a1i a2i" sequence. The (proper) subproofs demonstrate actual derivation processes that have been proven useful – which are no doubt much rarer than random combinations, even excluding random combinations that can be legally combined. The idea is different than your idea of creating a DB of "most general" results and scanning the formulas as if they were theorems, but your idea is worth considering separately. The concept behind my idea is that there may be cases where to use, say, Theorem1 and Theorem2, there needs to be an intervening derivation step using Theorem99 – but once that fact is known it becomes a great shortcut. So if I compute the "hint" that Theorem2 is one of the assertions that can possibly unify with Step S, then I can check see if the Theorem1-Theorem99-Theorem2 subproof combination is useful. --ocat
- .
- Here is another idea for speeding up searches during proving. For each formula (axiom and theorem, including logical hypotheses), precompute the list of all assertion formulas that can be unified with the formula – including the assertions that occur later in the database. (This is very much like the Earley Parser "FIRST" list used for lookahead.) This is actually different that building a table/database of all proper subproofs in the database – perhaps it is complementary. What it would save is that, in proving an assertion, it is only necessary to do a unification scan of the entire database once, at the beginning; then, once you've established the possible unifying assertions (mmj2's "hints"), you can then follow the precomputed chains! --ocat 8-Apr-2007
By the way something that could be useful and is certainly not easy to do.
Here is the worst proof I have ever written:
http://us2.metamath.org:8888/mpegif/cnpco.html
In this proof I've kept all the antecedents in every step even when they are no longer useful. To simplify the proof I need to be able to identify those that will never be used in the tree above a certain step. Is there a way to do that ? – fl
- maybe my idea for replacing repeated/selected sub-expressions automatically with "work variables"? would that provide insight, at least? --ocat
- The possibility to highlight sub-formulas in different colors seems more appropriate I think. – fl 6-Apr-2007
- In the "Authoritarian" approach discussed above, you would disconnect the subproof above that certain step. (E.g., copy the subproof and paste it as a new disconnected proof, unless some other command implements a disconnect function.) Any antecedents that become work variables that don't appear in the consequent are not needed.
- .
- In an advanced proof assistant with a scripting language (i.e. the "command mode" you suggested), you might even be able to write a script that would do this for each proof step, and tell you all the steps that have work variables in the antecedents that don't appear in the consequent. Then you could rework the proof until all such steps disappear (except for the actual "adantl" type step that removes them from earlier steps). – norm 7 Apr 2007
'Metamath "unification" is the process of
determining a consistent set of valid, simultaneous
substitutions to the variables of an assertion ("A")
and its essential hypotheses such that the resulting
formulas are identical to another assertion formula
("S") and its essential hypotheses.
An "incomplete unification" is a unification where
one or more of the substitutions to the variables
of A and its hypotheses contains work variables -- in
this case the two sets of formulas can be made
identical with consistent, valid, simultaneous
substitutions to the work variables.
To say that "S can be unified with A" is to say that
"S in an instance of A".
Definitions:
"Type" - the constant, first symbol of a
Metamath formula (e.g. "wff", "class"
or "set").
"Expression" - the 2nd through last symbols
of a Metamath formula (i.e. a Metamath
formula disregarding the Type code.)
"Sub-expression" - an expression which may be a
portion of a formula's expression, which
can be syntactically parsed, and thus
has an implicit Type.
"Work Variable" - a special kind of variable that
acts as a placeholder in an expression
for an unknown sub-expression.
"Valid Substitution" - a variable can be validly
substituted with any expression whose Type
matches the Type of the variable's floating
hypothesis formula.
"Simultaneous" - all substitutions are made at once,
which means in effect, that each
substitution is independent of every other.
For example, given "x + y" and substitutions
"x * y" for each "x", and "y * z" for each
"y", the resulting expression is
"x * y + y * z" -- not "x * y * z + y * z".
"Consistent" - all occurrences of a given variable
in the referenced assertion and its hypotheses
must be substituted with the same expression.
An alternative explanation that may be easier to
understand is based on the algorithm used in the
mmj2 program -- which has grammatical requirements that
are slightly stronger than those in metamath.exe, but
which are satisfied by the grammars of set.mm and ql.mm:
Suppose that proof step S uses database assertion A as
proof justification (for simplicity assume there
are no essential hypotheses involved).
Also suppose that S may contain "work variables"
but that, A cannot (since it is an assertion in a
Metamath database.)
Then, if S and its hypotheses can be unified with A
and its hypotheses, then proof step S is justified --
and provable, subject to any disjoint variable
requirements -- and valid, consistent, simultaneous
assignment of values to any work variables in S.
Now, a Formula S can be "unified" with Formula A if
the formulas' abstract syntax trees are identical
except at:
1) variable nodes of Tree A;
and
2) work variable nodes of Tree S;
where:
1) For each variable node "x" in Tree A, there is
a subtree "T" at the corresponding tree node
position of Tree S such that:
T and x have the same Type;
and,
Simultaneous, consistent substitution of subtree
T for every x node in Tree A is possible.
2) For each work variable node "w" in Tree S, there is
a subtree "B" at the corresponding tree node
position of Tree A such that:
w and B have the same Type;
and,
Simultaneous, consistent substitution of subtree
BW for every w node in Tree S is possible where:
Subtree BW is constructed by cloning subtree B
and replacing every assigned variable in B
with its assigned value, and every unassigned
variable in B with a new work variable.
If all of these conditions are met then unification
yields a consistent set of valid, simultaneous
substitutions that make Tree A equal to Tree S,
and assertion A can be said to justify proof step S,
subject to any disjoint variable restrictions and
-- and valid, consistent, simultaneous assignment of
values to any work variables in S.
Example 1: Let A = "( ( x -> y ) -> ( x -> z ) )" and
S = "( WFF1 -> WFF2 )".
S unifies with A to yield:
S" = "( ( WFF3 -> WFF4 ) -> (WFF3 -> WFF5 ) )"
Then A's syntax tree: A's assrtSubst
=============== |-------|---y---|---z---|
| x | y | z |
-> |-------|-------|-------|
. . | WFF3 | WFF4 | WFF5 |
-> -> ------------------------
. . . .
x y x z
S"'s syntax tree: S"'s Work Variable Subst:
================= |---------|---------|------|------|------|
| WFF1 | WFF2 | WFF3 | WFF4 | WFF5 |
-> |---------|---------|------|------|------|
. . | -> | -> | x | y | z |
WFF1 WFF2 |WFF3 WFF4|WFF3 WFF5| | | |
-----------------------------------------
Updated S" syntax tree:
=======================
->
. .
-> ->
. . . .
WFF3 WFF4 WFF3 WFF5
Example 2: Let A = "( ( x -> y ) -> ( x -> z ) )" and
S = "( ( F -> G ) -> WFF1 ) )".
S unifies with A to yield:
S" = "( ( F -> G ) -> ( F -> WFF2 ) )"
Then A's syntax tree: A's assrtSubst
=============== |-------|---y---|---z---|
| x | y | z |
-> |-------|-------|-------|
. . | WFF3 | WFF4 | WFF5 |
-> -> ------------------------
. . . .
x y x z
S"'s syntax tree: S"'s Work Variable Subst:
================= |---------|---------|
| WFF1 | WFF2 |
-> |---------|---------|
-> . | -> | z |
. . WFF1 | F WFF2| |
F G ---------------------
Updated S" syntax tree:
=======================
->
. .
-> ->
. . . .
F G F WFF2There is no difference between the "Metamath unification" you propose and the unification in the literature. You just need to map the terminology in the right way. In the terminology of the unification literature, your "work variables" are the variables. The symbols ph, ps,… in the hypotheses and conclusion of the theorem to be proved are (in the terminology of the literature) 0-ary functions or constants, because they are fixed (cannot substituted with an expression).
- "they" seem to have dug a deep semantic hole if variables ph, ps, … are called "constants". Substitutions can be made for them in Metamath…in Verify Proofs variables such as ph, ps, … are the only places substitutions can be made; certainly not in the constants such as ")", "+", etc. No wonder they find this trivial concept of unification so confusing – I appear to have reinvented it with zero difficulty :-) Hahah. --ocat
- You are mixing up a theorem that is referenced in a proof with the theorem to be proved. In the latter, you are not allowed to substitute ph, ps, etc. with anything - otherwise you would be changing what is to be proved - so they definitely act like wff constants, 0-ary predicates, or whatever equivalent name you want to use. In the former, you replace ph, ps, etc. with work variables in order to use it for the proof. Well, I'm not sure what you do :) - but that's what unification assumes, and it certainly will be what the user expects to see on the screen if an earlier theorem is pulled in as the first step of a new, isolated subproof. – norm
The unification between an expression with work variables and the conclusion of the theorem to be proved is an "easy" or "one-way" unification - you are just replacing the work variables with constant subexpressions in the conclusion.
The hard work is in the middle of the proof, before there is any connection to the theorem being proved. There is subtle interplay between the work variables of the two expressions that the algorithm needs to work out to compute the MGU, and this is the "difficult" part of the algorithm. What you should focus on is the behavior of your algorithm when the user creates an isolated subproof with 100% work variables, i.e. that is completely disconnected from the hypotheses and conclusion of the theorem being proved. This is where the real work of standard unification comes into play.
I don't know if there is sufficient information in your description to determine if your algorithm is mathematically correct or to figure out its run time, but even if there is that is a significant effort. Maybe yours is correct, but I don't see the point of reinventing the wheel unless there is a clear benefit. In any case, I would feel better if at least you make sure that your algorithm works with the "big unifier" I mentioned above as a test case. – norm 11 Apr 2007
Norm, perhaps you would consent to create a test case or two for me, translating big into a Metamath Proof Worksheet or a Metamath theorem – I don't see how to map whatever "they" are talking about to Metmath-speak. Thanks…--ocat
Here is the translation to a mm db. While I give the theorem and its proof for reference, the proof itself is not difficult for a unifier because it mostly involves one-way unifications with the fixed conclusion. The real test would be to create the theorem as an isolated subtheorem, where the conclusion (which will consist of 100% work variables) is not known in advance until the steps are unified - i.e. it is derived from the unification of the steps. – norm 11 Apr 2007
$( big-unifier.mm - Translation of William McCune's "big-unifier.in".
http://www-unix.mcs.anl.gov/AR/award-2003/big-unifier.in
http://www-unix.mcs.anl.gov/AR/award-2003/big-unifier.out $)$c wff |- e ( , ) $. $v x y z w v u v1 v2 v3 v4 v5 v6 v7 v8 v9 v10 v11 $.
wx $f wff x $. wy $f wff y $. wz $f wff z $. ww $f wff w $. wv $f wff v $. wu $f wff u $. wv1 $f wff v1 $. wv2 $f wff v2 $. wv3 $f wff v3 $. wv4 $f wff v4 $. wv5 $f wff v5 $. wv6 $f wff v6 $. wv7 $f wff v7 $. wv8 $f wff v8 $. wv9 $f wff v9 $. wv10 $f wff v10 $. wv11 $f wff v11 $.
wi $a wff e ( x , y ) $.
${
ax-mp.1 $e |- x $.
ax-mp.2 $e |- e ( x , y ) $.
ax-mp $a |- y $.
$}ax-maj $a |- e ( e ( e ( e ( e ( x , e ( y , e ( e ( e ( e ( e ( z , e ( e ( e ( z , u ) , e ( v , u ) ) , v ) ) , e ( e ( w , e ( e ( e ( w , v6 ) , e ( v7 , v6 ) ) , v7 ) ) , y ) ) , v8 ) , e ( v9 , v8 ) ) , v9 ) ) ) , x ) , v10 ) , e ( v11 , v10 ) ) , v11 ) $.
ax-min $a |- e ( e ( e ( e ( e ( e ( x , e ( e ( y , e ( e ( e ( y , z ) , e ( u , z ) ) , u ) ) , x ) ) , e ( v , e ( e ( e ( v , w ) , e ( v6 , w ) ) , v6 ) ) ) , v7 ) , v8 ) , e ( v7 , v8 ) ) , e ( v9 , e ( e ( e ( v9 , v10 ) , e ( v11 , v10 ) ) , v11 ) ) ) $.
theorem1 $p |- e ( e ( e ( x , e ( y , e ( e ( e ( y , z ) , e ( u , z ) ) , u ) ) ) , v ) , e ( x , v ) ) $= ( wi ax-min ax-maj ax-mp ) ABBCFECFFEFFZFZKDFADFFZAFZFJMFFZKNJFFNFZFAO FFZMPAFFZFPFQPFZFLRFFLNKMJAJNQPLAPGPMKBADCEOARLHI $.
Wow, thanks! You should add big-unifier.mm to the Metamath downloads file. Excellent test case. I ran it through mmj2 and the mmj2 Proof Assistant GUI, which passed with flying colors. The existing unification algorithm will need some changes to accomodate "work variables", but I don't see that big-unifier.mm will pose any problems for it. Generating "theorem1" as an isolated sub-proof using the mmj2 PA "Derive" is nothing that I'm not planning for – it is just uses huge formulas. --ocat
So, by theorem nega, we should conclude that it is something you are planning for. :) I'm happy big-unifier.mm (which is what I will call it, to match McCune's name) verifies with mmj2, but I expected that. My concern is whether the generation of theorem1 as an isolated subtheorem can be done correctly, and also "instantly" from the user's point of view. (Peterson's algorithm takes about 7 ms in C on my 2GHz laptop, which I tested using a modification to my program drule.c.). The speed will be much more important, of course, if you need to scan for database matches to expressions containing work variables. I should also mention that I don't really know if big-unifier.mm "stresses" the algorithm in any pathological way other just having big substitutions. There are also pathological cases where unification is "almost" but not quite possible, and of course the algorithm needs to recognize those - hopefully quickly, and certainly with no infinite loops under any conditions at all. These are potential pitfalls for ad-hoc unification algorithms that haven't undergone a theoretical analysis, from personal experience in long ago naive days before I even knew what unification was - hopefully you are smarter. :) While choice is up to you, of course, I still strongly encourage the adoption of a standard algorithm, or perhaps at least modularizing yours in such a way that would allow another (perhaps faster) algorithm to be plugged in in place of it in the future. Alternately, perhaps yours will be faster and better than any thus far, and you can publish a paper on it.
BTW what would be the procedure for proving theorem1 starting from scratch with the existing mmj2 program? Can it be done without having to provide the program with the huge expressions in the first 2 steps?
A curious factoid - the compressed proof is 125 characters, vs. 18488 characters for the uncompressed proof, thus providing 99.3% compression.
igblan, if you are reading this, how does the proof viewer you are working on fare with this beast? – norm 12 Apr 2007
- It sounds as if you just bought MMJ2 put options :) … OK… 1) Do you have a link for "Peterson's algorithm"?
- See below.
- I'm not opposed to doing something intelligent here … 2) mmj2 "Derive" works on big.mm to a point, but it kicks out the "dead" dummy variables – which have to be manually fixed before proceeding to Derive the next step. But, it easily derives one missing hypothesis on the qed step.
- Yes, that is what I observed. But since we have to manually assign an expression to the dummy variable that no human could figure out, what you are saying is that for practical purposes we can't complete the proof of theorem1. Is that a correct understanding?
- 3) I don't envision having to do the "hard" two-way unifications in the mmj2 PA GUI – the Derive function unifies with (against) a Ref label assertion, which contains zero work variables; it isn't looking for an MGU. --ocat
- I don't get why you say won't be looking for MGUs. If you unify a step with all work variables against a theorem in the db (which is what you mean by "Ref label assertion"?), you need to compute the MGU. Even though the referenced theorem has ph, ps, etc., you still make substitutions into them just as if they were work variables. Or perhaps more to the point, if you connect two isolated subproofs together - use the result of one to match an unknown step of the other - and each of them have 100% work variables - you need to compute the MGU. What am I not understanding? – norm
- This is partly my ignorance of the formal nomenclature, "MGU". Wrt your question about connecting two isolated subproofs, any given proof step (on the Proof Worksheet) can only be justified by a Ref to an assertion in the database, and so unification is with assertions in the database – a prior step in the proof worksheet can only be used as an hypothesis, so mmj2 is only doing "one-way" unifications, assigning the Proof Worksheet's variables (work and regular) to the variables used in the proof step's Ref'd assertion (and its hypotheses.) When I think of "MGU" I am thinking of taking two arbitrary formulas and producing a third formula that each of the two can unify with; that is not what is happening in mmj2's PA.
- See my response below. – norm
- .
- I may end up failing to complete the mods properly, in which case I would revert and try again. But look at it this way before you buy more put options: mmj2's unification is directly derived from Metamath's proof unification algorithm. The difference is that it uses a tree algorithm instead of a stack. What keeps mmj2's PA – the current version – from being wildly pathological is that the unification attempt of S with A makes at most one traversal of the S/A tree pair. As substitutions of S subexpressions for A variables are generated they are stored in a table, and later during tree traversal, a subsequent substitution to a variable in A that has already been substituted triggers a comparison to the previous substitution to see if they are equal – if not, the unification is not possible. There may be low-level issues, such as string comparisons that compile directly into machine ops, which mmj2's approach can never equal in terms of efficiency, but as long as the algorithm doesn't have to make repeated traversals of the same tree, it should perform adequately. The pathological problem involving random Hyp order on proof steps is addressed with a fairly sophisticated "checkpoint/restart" mechanism in mmj2's ProofUnifier? – since we may not know which logical hypothesis in the proof step corresponds to which logical hypothesis in the Ref'd assertion, our problem in the N! search is to match up the input hyps with the assertion hyp's, and for that the ProofUnifier? uses a table to record previous attempts at unifying a pair of logical hypotheses. It will likely be the case that unification searches involving work variables will be restricted to hint generation for this reason – thus, you would need to enter a Ref label on a proof step to initiate unification (we'll see how this plays out…) --ocat
- This is partly my ignorance of the formal nomenclature, "MGU". Wrt your question about connecting two isolated subproofs, any given proof step (on the Proof Worksheet) can only be justified by a Ref to an assertion in the database, and so unification is with assertions in the database – a prior step in the proof worksheet can only be used as an hypothesis, so mmj2 is only doing "one-way" unifications, assigning the Proof Worksheet's variables (work and regular) to the variables used in the proof step's Ref'd assertion (and its hypotheses.) When I think of "MGU" I am thinking of taking two arbitrary formulas and producing a third formula that each of the two can unify with; that is not what is happening in mmj2's PA.
- I don't get why you say won't be looking for MGUs. If you unify a step with all work variables against a theorem in the db (which is what you mean by "Ref label assertion"?), you need to compute the MGU. Even though the referenced theorem has ph, ps, etc., you still make substitutions into them just as if they were work variables. Or perhaps more to the point, if you connect two isolated subproofs together - use the result of one to match an unknown step of the other - and each of them have 100% work variables - you need to compute the MGU. What am I not understanding? – norm
Peterson's algorithm is shown as "Rule D" at the bottom of p. 5 (PDF p. 6) of finiteaxiom.pdf. However, it is specialized for "condensed detachment," which is intended only for unification of a major and minor premise of a modus ponens inference.
The generalization to arbitrary lists of hypotheses and $d's is done in the Unification class in mm.java at line 2953. Peterson's algorithm (which it really is, although the comments don't correlate to it) is in lines 3013-3053; the rest is "overhead". Even though the algorithm may seem simple, it didn't occur to me independently when I needed it, and it was considered nonobvious enough to merit publication. One of the key things is the correct recognition of when unification is not possible. Because I didn't do this right in my early naive algorithm, each time I thought it was perfected I kept running into new pathological cases that sometimes resulted in infinite loops, with the resulting patch upon patch…
An implementation of Peterson's algorithm in C, this time keeping the original specialization to condensed detachment, is the function dAlgorithm at line 817 of drule.c. You can see the exact mapping to "Rule D" of the paper in the comments of lines 919-1083 of drule.c.
Whether or not you use it, it would be nice if possible to keep it modularized for possible replacement with another algorithm. I don't think Peterson's, with O(n^2) behavior according to Raph, is optimal, but for most things it is adequate. It might also be the simplest. – norm 12 Apr 2007
(Reponse to ocat's 'so mmj2 is only doing "one-way" unifications' above – norm)
Here are two isolated subproofs, as I assume should appear on the screen.
subproof 1:
1::ax-1 |- ( WFF1 -> ( WFF1 -> WFF1 ) ) 2::ax-1 |- ( WFF1 -> ( ( WFF1 -> WFF1 ) -> WFF1 ) ) 3:1,2:mpd |- ( WFF1 -> WFF1 )
subproof 2:
11::ax-1 |- ( WFF3 -> ( WFF2 -> WFF3 ) ) 12::? |- ( WFF2 -> ( WFF3 -> WFF4 ) ) 13:12:a2i |- ( ( WFF2 -> WFF3 ) -> ( WFF2 -> WFF4 ) ) 14:11,13:syl |- ( WFF3 -> ( WFF2 -> WFF4 ) )
Now we want to use subproof 1 (step 3) to satisfy the missing step in subproof 2 (step 12). In other words, we want to connect steps 3 and 12. I don't know what your mechanism for doing that will be, but it isn't important right now. But in order to do this, we have to compute an MGU that will match both steps 3 and 12 simultaneously. The unique MGU (disregarding work variable naming) that will do this is:
( ( WFF5 -> WFF6 ) -> ( WFF5 -> WFF6 ) )
based on the two-way substitutions (i.e. two-way unification)
WFF1 <= ( WFF5 -> WFF6 ) WFF2 <= ( WFF5 -> WFF6 ) WFF3 <= WFF5 WFF4 <= WFF6
The final combined isolated subproof will look like this:
1::ax-1 |- ( ( WFF5 -> WFF6 ) ->
( ( WFF5 -> WFF6 ) -> ( WFF5 -> WFF6 ) ) )
2::ax-1 |- ( ( WFF5 -> WFF6 ) -> ( ( ( WFF5 -> WFF6 ) ->
( WFF5 -> WFF6 ) ) -> ( WFF5 -> WFF6 ) ) )
11::ax-1 |- ( WFF5 -> ( ( WFF5 -> WFF6 ) -> WFF5 ) )
12::1,2:mpd |- ( ( WFF5 -> WFF6 ) -> ( WFF5 -> WFF6 ) )
13:12:a2i |- ( ( ( WFF5 -> WFF6 ) -> WFF5 ) ->
( ( WFF5 -> WFF6 ) -> WFF6 ) )
14:11,13:syl |- ( WFF5 -> ( ( WFF5 -> WFF6 ) -> WFF6 ) )At no point in connecting the two subproofs was there a reference to the database. A two-way unification was required to connect them. – norm 12 Apr 2007
Wow, this is very helpful stuff you are providing. I am definitely happy with this help. This example is actually going beyond where I envisioned the immediately next version of mmj2 going. You are postulating that somehow the program knows to "Solve" for step 12 using step 3,
- Yes. The standard unification algorithm will "solve" it trivially. Hopefully your version of the algorithm will too, or if not, it may be time to look at the standard algorithm.
and then it applies "mpd" to Step 12.
- Well, not in the sense that it has to reference the database for this. The information it needs is already available in step 3.
In my immediate vision the user would request "Unify+Hints", which would return the fact that – disregarding logical hypotheses – mpd and maybe some other assertions could unify with step 12.
- I gave you a trivial example (one mpd) for the subproof ending in step 3. But in practice this could be 100 steps. I don't think you need or want to reference "mpd" at all; you need simply to reference step 3.
Then the user would input "mpd" in the Ref field of step 12 – and maybe enter "3" in the Hyp field -- and hit Ctrl-U to request Unification.
- Or perhaps just enter "3" or "#3" in the Ref field, or even ctrl-click to highlight both steps 3 and 12 then hit ctrl-u. The user shouldn't have to care that "mpd" was used for the last step in subproof one - all the user cares about is that the result of the subproof as a whole will satisfy step 12 (after the two-way unification).
- .
- But I think this is digressing; the actual mechanics of how the user does this isn't important right now. This important thing is that I am showing you a specific example where two-way unification is required.
- .
- Now let us go further, and talk about what happens when we do directly reference a database assertion (rather than another isolated subproof). What I am hoping is that you will come to see that anytime an expression with a work variable is unified with an assertion from the database, you have a potential two-way unification. You may have to substitute compound expressions for the WFF1, WFF2,… in the expression on the screen, and simultaneously substitute compound expressions for the ph, ps,… in the database assertion that is referenced, in order to make them unify. Such a substitution will result in an MGU.
- .
- In fact, take this very example, and instead of connecting the subproof result of step 3 with step 12, just put "id" in the Ref column of step 12. This is what mmj2 would have to do:
ph <= ( WFF5 -> WFF6 ) WFF2 <= ( WFF5 -> WFF6 ) WFF3 <= WFF5 WFF4 <= WFF6
- to result in
( ( WFF5 -> WFF6 ) -> ( WFF5 -> WFF6 ) )
- at step 12. Do you disagree that this is a two-way unification?
So are you saying that metamath.exe would automatically solve this one without user intervention?
- No, metamath.exe doesn't have the concept of isolated subproofs. However, MM Solitaire will do this - you enter subproof 1 and save it as a subtheorem "user-1". Then you enter subproof 2, using "user-1" to satisfy the missing step 12. A two-way unification will happen, effectively joining them together. You will see exactly step 14 in the "final combined isolated subproof" above, except for the work variable names.
- .
- If you have a proper unification algorithm built in, then "automatically solving" this is quite easy.
Because I was of the mindset that the UI for the PA in Metamath was based on entering Ref labels in reverse order.
- Yes, it is. But metamath.exe is unrelated to this discussion, I think - it is a different mindset from mmj2's goals, and I'm not sure why you are bringing it up.
- Well, at the top of this webpage I write "A primary goal of this release will be to make mmj2's Proof Assistant work a lot more like Metamath.exe's." I want to retain mmj2's existing "good" functionality – not take away good stuff like giving the user the option of entering formulas and having mmj2 look up the Ref labels – but I want to upgrade to Metamath's PA's capabilities, like having "live" work (aka "dummy") variables. (Actually, Raph was the originator of the idea to have mmj2 "Derive" formulas and steps when a Ref label is entered – it was not part of the original mmj2 scheme.) That said, I did spend some time with drule.c and your Finite Axiom pdf, and I think it makes sense to think long and hard before launching the code-writing blitz :-) Also though, I really do need an idea of the mechanism for triggering these features so that I can integrate the mechanisms in a holistic manner – I need to be able to "tell the story" in English, then I can write the code. So the idea about entering "#3" as a Ref label sounds like a winner. Or maybe a new unification algorithm would be so dang fast that more ambitious automatic features can be added. P.S. tree cutters coming, they may destroy out our network access tomorrow accidentally, so if you don't hear back right away… --ocat
- I agree completely that what metamath.exe does have would be desirable to have in mmj2. What I meant by my comment (and I see that I worded it rather poorly - sorry) was that metamath.exe doesn't handle isolated subproofs, and its "mindset" doesn't even have any concept of them, so it isn't too relevant to this discussion of how to handle isolated subproofs. On the other hand, being able to reproduce exactly my example below by entering steps backwards from the conclusion - with $1, $2… replaced by WFF1, WFF2… - would certainly be a great thing to have.
- .
- I believe that everything I have been describing could be accomplished in a relatively straightforward way if a robust 2-way unification algorithm is used in conjunction with the the "3 array" approach I talked about above. It would provide a conceptually simple and powerful engine that would take advantage of the existing parsing mechanism you already have, and re-use the GUI structure you already have in place, two important features that metamath.exe lacks. It should be very flexible in the sense of being able to easily add new features just by unifying the arrays and/or expressions in the database in different ways, using the same unification algorithm and the same arrays for everything. I think pretty much all of the existing features of mmj2 could fit into this model, except they would be even more powerful with two-way unification - for example, the expressions in big-unifier.mm would be filled in instantly as soon as the Ref labels are provided, whereas it is now stuck because there is only one-way unification, requiring the user to manually enter hopelessly complex expressions. It would be very user friendly because there would be little need for entering expressions (the thing that slows me down the most in mmj2), since most of them would be computed automatically like they are in metamath.exe, when the user knows in advance what theorems to use (which could be selected from a right-click-on-step pulldown list of all the ones that unify with the step). And, if combined with a philosophy like metamath.exe's of only allowing consistent things to appear on the screen (which we, or I, agreed to disagree about above), I think that would be a very usable and powerful assistant.
- .
- While I haven't studied the mmj2 code closely, and you can correct me if I'm wrong, my feeling is that features are being added with sort of ad hoc algorithms as the need arises but don't really have a simple, coherent model underneath them, and there is corresponding pain in adding new features. For example, there is no point in having a separate one-way unification algorithm if you have a two-way one available. With the 3-array/2-way unification model I have in mind, once the core algorithms are developed, hopefully all you would need to do is to call them at a high level in different ways to implement the existing features, and you should be able to add new commands and features relatively easily. – norm
- Well, at the top of this webpage I write "A primary goal of this release will be to make mmj2's Proof Assistant work a lot more like Metamath.exe's." I want to retain mmj2's existing "good" functionality – not take away good stuff like giving the user the option of entering formulas and having mmj2 look up the Ref labels – but I want to upgrade to Metamath's PA's capabilities, like having "live" work (aka "dummy") variables. (Actually, Raph was the originator of the idea to have mmj2 "Derive" formulas and steps when a Ref label is entered – it was not part of the original mmj2 scheme.) That said, I did spend some time with drule.c and your Finite Axiom pdf, and I think it makes sense to think long and hard before launching the code-writing blitz :-) Also though, I really do need an idea of the mechanism for triggering these features so that I can integrate the mechanisms in a holistic manner – I need to be able to "tell the story" in English, then I can write the code. So the idea about entering "#3" as a Ref label sounds like a winner. Or maybe a new unification algorithm would be so dang fast that more ambitious automatic features can be added. P.S. tree cutters coming, they may destroy out our network access tomorrow accidentally, so if you don't hear back right away… --ocat
Perhaps you are saying that "Improve All" would be used? --ocat
- No, metamath.exe won't do this at all, because it doesn't have the concept of isolated subproofs. However, if we use the dummylink trick to force the use of work variables throughout, two-way unifications will happen properly as the proof steps are entered, resulting in the following that you can reproduce if you wish: – norm
MM-PA> sh n/lem/ren
1 ? $? |- ( 2 + 2 ) = 4
2 ax-1 $a |- ( $1 -> ( ( $1 -> $12 ) -> $1 ) )
3 ax-1 $a |- ( ( $1 -> $12 ) -> ( $4 -> ( $1 -> $12 ) )
)
4 ax-1 $a |- ( ( $1 -> $12 ) -> ( ( $4 -> ( $1 -> $12 )
) -> ( $1 -> $12 ) ) )
5 3,4 mpd $p |- ( ( $1 -> $12 ) -> ( $1 -> $12 ) )
6 5 a2i $p |- ( ( ( $1 -> $12 ) -> $1 ) -> ( ( $1 -> $12
) -> $12 ) )
7 2,6 syl $p |- ( $1 -> ( ( $1 -> $12 ) -> $12 ) )
8 1,7 dummylink $p |- ( 2 + 2 ) = 4
MM-PA>Issues Involving One-Way Unification With "Work Variables".
Below we deal only with wff's – x, y, z, etc. are wff type variables. And WFF1, WFF2, … , WFF9 are "Work Variables", also of type wff.
The Formulas "A" and "S" refer to database Assertion "A" (e.g. ax-mp) and proof step "S", where proof step S has Ref (label) = A (A justifies S).
The first two examples are clear, I think.
Example 1: Let A = "( ( x -> y ) -> ( x -> z ) )" and
S = "( WFF1 -> WFF2 )".
S unifies with A to yield:
S" = "( ( WFF3 -> WFF4 ) -> (WFF3 -> WFF5 ) )"
Then A's syntax tree: A's assrtSubst
=============== |-------|---y---|---z---|
| x | y | z |
-> |-------|-------|-------|
. . | WFF3 | WFF4 | WFF5 |
-> -> ------------------------
. . . .
x y x z
S's syntax tree: S's Work Variable Subst:
================ |---------|---------|------|------|------|
| WFF1 | WFF2 | WFF3 | WFF4 | WFF5 |
-> |---------|---------|------|------|------|
. . | -> | -> | x | y | z |
WFF1 WFF2 | x y | x z | | | |
-----------------------------------------
Updated S" syntax tree:
=======================
->
. .
-> ->
. . . .
WFF3 WFF4 WFF3 WFF5
Example 2: Let A = "( ( x -> y ) -> ( x -> z ) )" and
S = "( ( F -> G ) -> WFF1 ) )".
S unifies with A to yield:
S" = "( ( F -> G ) -> ( F -> WFF2 ) )"
Then A's syntax tree: A's assrtSubst
=============== |-------|---y---|---z---|
| x | y | z |
-> |-------|-------|-------|
. . | F | G | WFF2 |
-> -> ------------------------
. . . .
x y x z
S's syntax tree: S's Work Variable Subst:
================ |---------|---------|
| WFF1 | WFF2 |
-> |---------|---------|
-> . | -> | z |
. . WFF1 | x z | |
F G ---------------------
Updated S" syntax tree:
=======================
->
. .
-> ->
. . . .
F G F WFF2
Example 3 is different.
Example 3: Let A = "( x -> ( y -> x ) )" and
S = "( ( WFF1 -> WFF2 ) -> WFF1 ) )".
S unifies with A to yield: ?
S" = " ? "
Then A's syntax tree: A's assrtSubst
=============== |-------|---y---|
| x | y |
-> |-------|-------|
. . | | |
x -> -----------------
. .
y x
S's syntax tree: S's Work Variable Subst:
================ |---------|---------|
| WFF1 | WFF2 |
-> |---------|---------|
-> WFF1 | | |
. . | | |
WFF1 WFF2 ---------------------
Updated S" syntax tree:
=======================
?
I'm not a specialist but in the last case – and in my opinion – mmj2 should scream in horror, violently rush out of the room, slam the door and refuse to come in back unless great shows of repentance were made ! – fl 4-Jun-2007
What you are doing is two-way unification, not one-way. In Examples 1 and 2, the variables of both formulas A and S have substitutions made into them. In Example 2, F and G are constants (0-ary connectives) for the purpose of the two-way unification in that example.
The unification of Example 3 is not possible. Your algorithm should detect that and return a "not possible" result (indicated by an empty string, Boolean flag, or whatever method you find convenient). If you look at Peterson's algorithm that I've mentioned before, you'll see that this detection is automatic. Again, I would recommend that you implement his algorithm. The difficulty you are encountering is the same kind of thing I ran into when I tried to "home brew" my own unification algorithm years ago, before I was aware of Peterson's. -- norm 4 Jun 2007
Draft: Proof Step Unification Involving Work Variables
Draft StepUnify – zipped html file. Looks to be a tough read :-) ocat 10-Jun-2007
Status Update 6/20/2007
Coding on the "Work Variables Enhancement" to mmj2 is well under way. ETA for a version ready for user feature-testing is … what … probably two, maybe three weeks? I will upload it after re-running regression tests and my basic thrashing…
The "Work Variables Enhancement" has been described at some length,
but, in short, allows unknown sub-expressions in non- QED derivation steps to be represented as variables ("work variables", default naming is &W1 for wffs, &S1 for sets, etc.), just as in metamath.exe's Proof Assistant (except that it names them 2, etc.)
Unknown proof step sub-expressions most commonly result when formulas are generated (derived), as opposed to being manually entered. An "under- specified" derivation consists of an Assertion label ("Ref") plus 0->n step and hypothesis formulas, where not every variable used in the referenced Assertion and its hypotheses (if any) is the target of a substitution.
One early decision regarding the new enhancement is that for efficiency's sake – and predictable response time – Unification Search processes will not be performed for proof steps (and associated hypotheses) containing work variables. This is not a major restriction because the primary intent of the Work Variables Enhancement is to enable the user to enter a Ref label and generate proof step formulas, so ordinarily there is no need to search for a unifying Ref (assertion). However, mmj2 does have features that involve Unification Search even when a Ref label is entered:
1) If the Ref'd assertion fails to unify, a list of "Alternates" is produced displaying the assertion labels that do unify with the proof step. In the new mmj2 version, if work variables are involved in the proof step, Alternate refs are not produced (because this would require Unification search.)
2) If the Ref'd assertion unifies but has distinct variable errors ("soft" or "hard"), mmj2 performs Unification Search to find the first Assertion that does unify but with zero or less-severe distinct variable errors – and if a hit is made, the found Assertion's label is automatically substituted for the entered Ref label. In the new mmj2 version, not only is this Unification Search not performed, but Distinct Variable restriction validation checks are not performed if work variables are involved in the proof step However, if the entered Ref does unify and all work variables are resolved by the unification, being replaced with the source variables from the proof, then normal Distinct Variable restriction edits and the follow-on searching are performed. (Whew…tricky bit of code… :-)
On the plus side, the "Unify+Get Hints" feature does work in the new mmj2 version even when work variables are involved. This decision is based upon the judgement that Hints – which display the Assertions that unify with just a proof step's formula, disregarding its hypotheses – are specifically requested and are, presumably, earnestly desired; therefore, a regrettably slow response time in a few instances is preferable to disappointing the user (who would, if asked, just say, "Take all the time you need, I really want this answer!) Also, unification of just the individual step formulas during Unification Search is unlikely to be a show stopper in terms of performance – the absolute worst case in performance results from misordered hypotheses, and that would not apply in this scenario.
One final bit of business, regarding which you may wish to offer input… in the cases where not every work variable is resolved and replaced by source variables from the proof steps, mmj2 will be updating proof step formulas on the screen. For example, a work variable "&W1" might be replaced by "( ph → ps )" or "( &W2 → &W3 )".
My initial idea is to reformat each formula that is programmatically updated using the TMFF parameters in use at the time. The alternative would be to only reformat an updated formula if one or more lines grew in length to exceed the user-specified right margin. The drawback to this alternative, besides the extra coding, is that failure to reformat might mean that some TMFF column alignments would be awry; the user could, of course, request reformatting to correct this. On the other hand, the major drawback of reformatting every updated formula is that any user- entered formula alignment is lost; this seems to be a negligible concern given the fact that in most cases work variables will occur in derived formulas, which will of course be TMFF-formatted, not user-formatted.
- in my opinion allowing the user to modify the buffer is a bad idea that drives you to a field of difficulties such as the one you describe above. Get rid of this feature. – 20-Jun-2007 fl
- I am interpreting your suggestion as license to automatically reformat updated formulas – finesse can always be added later…and formulas containing work variables most likely were generated and auto-formatted in the first place. Now, philosophically speaking, I would not characterize the Proof Text Area as a "buffer". However, even accepting this usage of the term, one might compare the Proof Assistant GUI to a WYSIWYG word processor with spell checking – obviously an application like MSFT.Word has coding complications (ha), but the users seem to love it :-0) Also, part of the inherent goodness of the mmj2 PA is that it does tackle service heretofore left unserved; ideally the user input would be Voice and Digitial Pen, and not these dratted keyboards, but that would be a job for either mmj3 or a team of supermen. --ocat 21-Jun-2007
- Obviously yes reformat automatically! And I disagree with your comparison between mmj2 and Word. The normal human being can expect to write a text letter by letter but he can't expect to write (with ease) a formula symbol by symbol because his faculty to control the syntax at every time is very closed to zero. – fl 22-Jun-2007
- mmj2 would have more features in common with Word if only…wishes were horses… The analogy is flawed due to the scarcity of features in mmj2, not the needs of a document preparer. Also, the syntax difficulties you mention? English syntax (or francais) is harder than set.mm's – after all, set.mm uses a context free grammar where as English is a phrase structure grammar (http://en.wikipedia.org/wiki/Chomsky_hierarchy). What makes writing in English seem natural is just deep familiarity and hard-wiring of the semiotics of the symbols in the brain. If you had learned Norm's ascii shorthand for set.mm beginning as an infant you would believe it to be a most natural way of expressing statements in logic and math. ocat
- In fact I'm afraid I disagree with you and Chomsky :-) The sentences of a natural language are simpler for a human being than the formulas of an artificial language. In particular artificial languages use plenty of parentheses and this is enough to make a human being have the impression that death is better than life. Secondly from a step to another, the greatest part of a formula is copied and expecting that your user appreciates copying the formula and changing a small subformula inside is higly problematic. In short what must be entered (as a major feature at least) are the names of the theorems not the formulas. – fl 23-Jun-2007
- .
- Metamath.exe (and mmj2) require the concrete syntax to match the abstract syntax, which in effect seems to require extra parentheses for grouping (unless we use prefix or postfix notations). And of course, Metamath's restriction to ASCII tokens further limits its semiotic powers. But actually thinking in English, for example, may be the intellectual equivalent of walking around carrying a 100 kilo sack of rocks. I direct your attention to Heinlein's story, "Gulf" in his collection "Assignment In Eternity": "'Normal' languages, having their roots in days of superstition and ignorance, have in them inherently and unescapably wrong structures of mistaken ideas about the universe. One can think logically in English only by extreme effort, so bad is it as a mental tool. For example, the verb 'to be' in English has twenty-one distinct meanings, /every single one of which is false-to-fact/." In fact, you might look at E-Prime. --ocat
- .
- I really appreciate Shakespeare or Carroll in E-prime; no longer the same texts I dare say. It reminds me a French writer called Jacques Roubaud ( also a mathematics teacher ) who had invented a marvellous technics he called co-decimation. Decimation in Rome consisted in killing one men out of ten in an army as a punition. Co-decimation consists in keeping one verse out of ten in poems that Roubaud finds too long. He has co-decimated "Phèdre" by Racine for example and to tell the truth it is much, much, much better. This way la Comédie Française in one evening can play all the tragedies by Racine. It is saving time and money. – fl 24-Jun-2007
- mmj2 would have more features in common with Word if only…wishes were horses… The analogy is flawed due to the scarcity of features in mmj2, not the needs of a document preparer. Also, the syntax difficulties you mention? English syntax (or francais) is harder than set.mm's – after all, set.mm uses a context free grammar where as English is a phrase structure grammar (http://en.wikipedia.org/wiki/Chomsky_hierarchy). What makes writing in English seem natural is just deep familiarity and hard-wiring of the semiotics of the symbols in the brain. If you had learned Norm's ascii shorthand for set.mm beginning as an infant you would believe it to be a most natural way of expressing statements in logic and math. ocat
- Obviously yes reformat automatically! And I disagree with your comparison between mmj2 and Word. The normal human being can expect to write a text letter by letter but he can't expect to write (with ease) a formula symbol by symbol because his faculty to control the syntax at every time is very closed to zero. – fl 22-Jun-2007
- I am interpreting your suggestion as license to automatically reformat updated formulas – finesse can always be added later…and formulas containing work variables most likely were generated and auto-formatted in the first place. Now, philosophically speaking, I would not characterize the Proof Text Area as a "buffer". However, even accepting this usage of the term, one might compare the Proof Assistant GUI to a WYSIWYG word processor with spell checking – obviously an application like MSFT.Word has coding complications (ha), but the users seem to love it :-0) Also, part of the inherent goodness of the mmj2 PA is that it does tackle service heretofore left unserved; ideally the user input would be Voice and Digitial Pen, and not these dratted keyboards, but that would be a job for either mmj3 or a team of supermen. --ocat 21-Jun-2007
In conclusion, expect a new version of mmj2 somewhere around July 10 – barring misfortune and diety disfavor. I hope that you will then take the opportunity to enjoy a lengthy trial period and offer suggestions regarding favorable changes to the functions of mmj2. This will perhaps be the penultimate major mmj2 release (because of entropy), so we should make a major last-ditch effort to make sure the system is satisfactory (for what it is – as opposed to mmj3 and Sky Pie for everyone…)
Ciao.
P.S. StepUnifier?.java coding complete. The description/spec document, Step Unifier has a few typos (I switched "target" and "source" in a couple of places - but detected the errors while coding…) A bit of retrofitting into ProofUnifier? and ProofAsst?, and it will be time for the Big Bang test (in principle I disapprove of of testing as it displays weakness and lack of confidence superimposed on top of Unclear on the Concept – if it compiles clean then it ought to work – but I will run a few tests in spite of my principles…) --ocat 24-Jun-2007
P.P.S. I disovered several more flaws in my StepUnifier? document. 1) Unification of the derivation steps must proceed from top to bottom because in theory two steps with formulas to be derived may be linked, with the 2nd using the first as an hypothesis. 2) Distinct Variable checking can and should be performed for formulas that contain work variables, assuming all other processing, including unification, is successful. The reason is that the new Step Unifier unification algorithm converts substitutions made to source variable (variables in the theorem to be proved) into substitutions into work variables; therefore, the substitutions ultimately made into the target variables are at least as granular as the target variables and so "hard" $d errors can be detected (but the "soft" error must be bypassed because there will be no $d statements for work variables. 3) It is unclear to me at what point the program should make the executive decision to convert work variables into "dummy" (optional frame) variables. Clearly, once the "qed" step is unified successfully and there are no missing hypotheses in the derivation chain, any remaining work variables in the derivation chain can be replaced with "dummy" variables – but can the program make that determination earlier (otherwise, re-processing of derivation steps and $d's will be needed.) 4) In the process of converting work variables to dummy variables, it is unlikely that the program could make the same choices used by the original theorem's author, so therefore the existing $d statements for optional variables will often be "wrong". So, the user will possibly want to use the "Generate Replacements" $d processing option to regenerate $d's automatically. --ocat 27-Jun-2007
Well, I now must complete just one final bit of retrofitting in ProofUnifier?.java to account for the existence of Work Variables. Then I will be ready to run a few tests and release the new mmj2 code for functionality testing by the users! (Whew…)
The Final Scenario is this: the "qed" step is unified and it has unification status equal to "unified with work variables", which indicates that one of its logical hypotheses, or one of their logical hypotheses still contains a Work Variable, but that all of them were unified successfully.
Thus, the final proof will contain "dummy" variables – variables in the Optional Frame of the theorem being proved – and the remaining Work Variables in the derivation chain leading up to the "qed" step must be replaced with these dummy variables.
To accomplish this feat is a really tedious piece of work (which must be done because a serious user would want this operation handled automatically, no questions asked):
1) figure out which "dummy" variables are already in use, and which are still available for use.
2) assign a unique "dummy" to each remaining Work Variable in the derivation chain – and if we run out of available dummy variables in the Optional Frame, then report an error and halt the fix-up.
3) update each affected derivation step's parse tree, formula and assertion substitution items with the new dummy variables, update the unification status, and reformat the formula for display on the screen.
4) for each affected derivation step which does not have a "hard" Dj Variables error status, rerun the Dj Vars editing process to pick up the final "soft" Dj Vars error data/messages.
--ocat 30-Jun-2007
the proof contains Work Variables that requireconversion to dummy variables.
Several different Work Variable → Dummy Variable conversion algorithms are possible:
1) Perform a one-to-one mapping of the remaining Work Variables to the unused Optional Frame variables. This is easiest and requires just a single pass through the proof steps applying the mapping to the proof step assrtSubst, parseTree and formula fields. The drawback is that the number of unused Optional Frame variables may be insufficient; and even if we were to require the user to read an error message and then update the input .mm file to add more Optional Frame variables, the restriction is arbitrary and unprofessional. After all, whereas the mathematician/authors such as Megill, et al would expect common dummy variables such as x, y and z to be reusable, mmj2 would potentially require an infinite supply!
2) For each proof step where a "dummy" Work Variable is "discharged" (not present in the step's formula but present in its hypotheses), determine which Optional Frame variable is unused within the subtree terminating at the proof step which contains the discharged variable, and then apply the change to proof steps containing the discharged Work Variable. This is possibly the optimal algorithm in terms of user satisfaction because it is maximally economical with dummy variables. It is also the trickiest to program, and may not be necessary if a Third Way is available…
3) Starting with the "qed" step subtree - the "qed" step cannot contain Work Variables, by definition – compute the set "A" of proof steps in the subtree that introduce or use Work Variables discharged by the "qed" step. Hypotheses of the steps that introduce the Work Variables of set "A" would be pruned and put into a different set, "B", for subsequent processing. In most cases the set of Work Variables used by steps in set "A" will be smaller than the total set of Work Variables; this is because "dummy variables" tend to be discharged along the way as a proof develops. The algorithm from algorithm #1 would then be applied to set "A" and its work variables. Then, for each proof step in set "B" which has unification status of "unified with work variables", the algorithm would be repeated, taking each proof step from set "B", finding the pruned subtree's set "A", etc.
4) Unfortunately, algorithm #3 will not work exactly as-is in the case where an hypothesis is reused – that is, used in more than one subsequent derivation proof step. We would update the reused hypothesis twice and might apply inconsistent updates to some of its descendants!
There is a Fourth Way! In the example below for theorem "hilhl" you see a Proof Worksheet showing what happens when unification and proof generation is performed without converting leftover Work Variables to dummy variables.
Because of the way new Work Variables are allocated in the mmj2 Proof Assistant, when a new "dummy" variable is introduced, repeated introductions and discharges, for example, of dummy variable "x" result in multiple different Work Variables – &S4, &S3, &S8, etc. Then when unification is performed, what remains are disjoint sets of dummy Work Variables:
{ &S4, &S5, &S6 } – steps 4, 5, 6, etc. { &S3, &S7 } – steps 13, 15, etc. { &S8, &S9 } – steps 22, 23, etc.
These disjoint sets of Work Variables can thus be treated as independent replacements using the one-to-one mapping described in algorithm #1.
So, for hilhl, these substitutions can be made:
{ &S4, &S5, &S6 } <-> { x , y , z }
{ &S3, &S7 } <-> { x , y }
{ &S8, &S9 } <-> { x , y }This algorithm is not optimal. It may not be the most economical use of Optional Frame "dummy" variables, but it should do the job.
mmj2 keeps a separate ArrayList? of the Work Variables used in each proof step, so implementing #4 is easy. Just go down the proof steps in order from top to bottom until the first step containing Work Variables is found. Then check each succeeding step to see if it has any Work Variables in common with the first step.
If so, the take the union of the steps' ArrayLists?; otherwise, if a succeeding step's Work Variables are disjoint with the first step, start a new set of disjoint variables and check it against each succeeding proof step – and so on.
In the end there will be 'n' sets of disjoint Work Variable lists, each of which can be replaced using the one-to-one mapping of algorithm #1. And in fact, a single update pass through the proof can be made based on the observation that a consolidated list of updates can be built and then applied to each proof step (e.g. &S3 = x, &S4 = x, &S5 = y, &S6 = z, &S7 = y, &S8 = x, and &S9 = z).
$( <MM> <PROOF_ASST> THEOREM=hilhl LOC_AFTER=?
* The Hilbert space of the Hilbert Space Explorer is a complex Hilbert
space. (Contributed by Steve Rodriguez, 29-Apr-2007.)
1::ishlg |- ( <. <. +h , .h >. , normh >. e. CHil
<-> ( <. <. +h , .h >. , normh >. e. CBan
/\ <. <. +h , .h >. , normh >. e. CPreHil ) )
2::isbn |- ( <. <. +h , .h >. , normh >. e. CBan
<-> ( <. <. +h , .h >. , normh >. e. NrmCVec
/\ ( IndMet ` <. <. +h , .h >. , normh >. )
e. CMet ) )
3::hilncv |- <. <. +h , .h >. , normh >. e. NrmCVec
4::eqid |- {
<.
<. &S4
, &S5
>.
, &S6
>.
| ( ( &S4 e. H~ /\ &S5 e. H~ )
/\ &S6 = ( normh ` ( &S4 -h &S5 ) ) ) }
= {
<.
<. &S4
, &S5
>.
, &S6
>.
| ( ( &S4 e. H~ /\ &S5 e. H~ )
/\ &S6 = ( normh ` ( &S4 -h &S5 ) ) ) }
5:4:hilims |- ( IndMet ` <. <. +h , .h >. , normh >. )
= <. H~
, {
<.
<. &S4
, &S5
>.
, &S6
>.
| ( ( &S4 e. H~ /\ &S5 e. H~ )
/\ &S6 = ( normh ` ( &S4 -h &S5 ) ) ) } >.
6::eqid |- {
<.
<. &S4
, &S5
>.
, &S6
>.
| ( ( &S4 e. H~ /\ &S5 e. H~ )
/\ &S6 = ( normh ` ( &S4 -h &S5 ) ) ) }
= {
<.
<. &S4
, &S5
>.
, &S6
>.
| ( ( &S4 e. H~ /\ &S5 e. H~ )
/\ &S6 = ( normh ` ( &S4 -h &S5 ) ) ) }
7:6:hilcms |- <. H~
, {
<.
<. &S4
, &S5
>.
, &S6
>.
| ( ( &S4 e. H~ /\ &S5 e. H~ )
/\ &S6 = ( normh ` ( &S4 -h &S5 ) ) ) } >.
e. CMet
8:5,7:eqeltr |- ( IndMet ` <. <. +h , .h >. , normh >. )
e. CMet
9:2,3,8:mpbir2an |- <. <. +h , .h >. , normh >. e. CBan
10::hilabl |- +h e. Abel
11:10:elisseti |- +h e. V
12::hvmulex |- .h e. V
13::df-hnorm |- normh
= {
<. &S3
, &S7
>.
| ( &S3 e. H~
/\ &S7 = ( sqr ` ( &S3 .ih &S3 ) ) ) }
14::ax-hilex |- H~ e. V
15:14:funopabex2 |- {
<. &S3
, &S7
>.
| ( &S3 e. H~
/\ &S7 = ( sqr ` ( &S3 .ih &S3 ) ) ) }
e. V
16:13,15:eqeltr |- normh e. V
17::hilabl |- +h e. Abel
18::ablgrp |- ( +h e. Abel -> +h e. Grp )
19:17,18:ax-mp |- +h e. Grp
20::ax-hfvadd |- +h : ( H~ X. H~ ) --> H~
21:19,20:grprn |- H~ = ran +h
22:21:isphg |- ( ( +h e. V /\ .h e. V /\ normh e. V )
-> ( <. <. +h , .h >. , normh >. e. CPreHil
<-> ( <. <. +h , .h >. , normh >. e. NrmCVec
/\ A. &S8
e. H~
A. &S9
e. H~
( ( ( normh ` ( &S8 +h &S9 ) ) ^ 2 )
+
( ( normh
` ( &S8 +h ( -u 1 .h &S9 ) ) )
^
2 ) )
= ( 2
x.
( ( ( normh ` &S8 ) ^ 2 )
+
( ( normh ` &S9 ) ^ 2 ) ) ) ) ) )
23:11,12,16,22:mp3an
|- ( <. <. +h , .h >. , normh >. e. CPreHil
<-> ( <. <. +h , .h >. , normh >. e. NrmCVec
/\ A. &S8
e. H~
A. &S9
e. H~
( ( ( normh ` ( &S8 +h &S9 ) ) ^ 2 )
+
( ( normh
` ( &S8 +h ( -u 1 .h &S9 ) ) )
^
2 ) )
= ( 2
x.
( ( ( normh ` &S8 ) ^ 2 )
+
( ( normh ` &S9 ) ^ 2 ) ) ) ) )
24::hilncv |- <. <. +h , .h >. , normh >. e. NrmCVec
25::normpart |- ( ( &S8 e. H~ /\ &S9 e. H~ )
-> ( ( ( normh ` ( &S8 -h &S9 ) ) ^ 2 )
+
( ( normh ` ( &S8 +h &S9 ) ) ^ 2 ) )
= ( ( 2 x. ( ( normh ` &S8 ) ^ 2 ) )
+
( 2 x. ( ( normh ` &S9 ) ^ 2 ) ) ) )
26::hvsubvalt |- ( ( &S8 e. H~ /\ &S9 e. H~ )
-> ( &S8 -h &S9 )
= ( &S8 +h ( -u 1 .h &S9 ) ) )
27:26:fveq2d |- ( ( &S8 e. H~ /\ &S9 e. H~ )
-> ( normh ` ( &S8 -h &S9 ) )
= ( normh
` ( &S8 +h ( -u 1 .h &S9 ) ) ) )
28:27:opreq1d |- ( ( &S8 e. H~ /\ &S9 e. H~ )
-> ( ( normh ` ( &S8 -h &S9 ) ) ^ 2 )
= ( ( normh
` ( &S8 +h ( -u 1 .h &S9 ) ) )
^
2 ) )
29:28:opreq2d |- ( ( &S8 e. H~ /\ &S9 e. H~ )
-> ( ( ( normh ` ( &S8 +h &S9 ) ) ^ 2 )
+
( ( normh ` ( &S8 -h &S9 ) ) ^ 2 ) )
= ( ( ( normh ` ( &S8 +h &S9 ) ) ^ 2 )
+
( ( normh
` ( &S8 +h ( -u 1 .h &S9 ) ) )
^
2 ) ) )
30::axaddcom |- ( ( ( ( normh ` ( &S8 +h &S9 ) ) ^ 2 )
e. CC
/\ ( ( normh ` ( &S8 -h &S9 ) ) ^ 2 )
e. CC )
-> ( ( ( normh ` ( &S8 +h &S9 ) ) ^ 2 )
+
( ( normh ` ( &S8 -h &S9 ) ) ^ 2 ) )
= ( ( ( normh ` ( &S8 -h &S9 ) ) ^ 2 )
+
( ( normh ` ( &S8 +h &S9 ) ) ^ 2 ) ) )
31::hvaddclt |- ( ( &S8 e. H~ /\ &S9 e. H~ ) -> ( &S8 +h &S9 ) e. H~ )
32::normclt |- ( ( &S8 +h &S9 ) e. H~
-> ( normh ` ( &S8 +h &S9 ) ) e. RR )
33:31,32:syl |- ( ( &S8 e. H~ /\ &S9 e. H~ )
-> ( normh ` ( &S8 +h &S9 ) ) e. RR )
34:33:recnd |- ( ( &S8 e. H~ /\ &S9 e. H~ )
-> ( normh ` ( &S8 +h &S9 ) ) e. CC )
35::sqclt |- ( ( normh ` ( &S8 +h &S9 ) ) e. CC
-> ( ( normh ` ( &S8 +h &S9 ) ) ^ 2 )
e. CC )
36:34,35:syl |- ( ( &S8 e. H~ /\ &S9 e. H~ )
-> ( ( normh ` ( &S8 +h &S9 ) ) ^ 2 )
e. CC )
37::hvsubclt |- ( ( &S8 e. H~ /\ &S9 e. H~ ) -> ( &S8 -h &S9 ) e. H~ )
38::normclt |- ( ( &S8 -h &S9 ) e. H~
-> ( normh ` ( &S8 -h &S9 ) ) e. RR )
39:38:recnd |- ( ( &S8 -h &S9 ) e. H~
-> ( normh ` ( &S8 -h &S9 ) ) e. CC )
40::sqclt |- ( ( normh ` ( &S8 -h &S9 ) ) e. CC
-> ( ( normh ` ( &S8 -h &S9 ) ) ^ 2 )
e. CC )
41:37,39,40:3syl |- ( ( &S8 e. H~ /\ &S9 e. H~ )
-> ( ( normh ` ( &S8 -h &S9 ) ) ^ 2 )
e. CC )
42:30,36,41:sylanc |- ( ( &S8 e. H~ /\ &S9 e. H~ )
-> ( ( ( normh ` ( &S8 +h &S9 ) ) ^ 2 )
+
( ( normh ` ( &S8 -h &S9 ) ) ^ 2 ) )
= ( ( ( normh ` ( &S8 -h &S9 ) ) ^ 2 )
+
( ( normh ` ( &S8 +h &S9 ) ) ^ 2 ) ) )
43:29,42:eqtr3d |- ( ( &S8 e. H~ /\ &S9 e. H~ )
-> ( ( ( normh ` ( &S8 +h &S9 ) ) ^ 2 )
+
( ( normh
` ( &S8 +h ( -u 1 .h &S9 ) ) )
^
2 ) )
= ( ( ( normh ` ( &S8 -h &S9 ) ) ^ 2 )
+
( ( normh ` ( &S8 +h &S9 ) ) ^ 2 ) ) )
44::2cn |- 2 e. CC
45::axdistr |- ( ( 2 e. CC
/\ ( ( normh ` &S8 ) ^ 2 ) e. CC
/\ ( ( normh ` &S9 ) ^ 2 ) e. CC )
-> ( 2
x.
( ( ( normh ` &S8 ) ^ 2 )
+
( ( normh ` &S9 ) ^ 2 ) ) )
= ( ( 2 x. ( ( normh ` &S8 ) ^ 2 ) )
+
( 2 x. ( ( normh ` &S9 ) ^ 2 ) ) ) )
46:44,45:mp3an1 |- ( ( ( ( normh ` &S8 ) ^ 2 ) e. CC
/\ ( ( normh ` &S9 ) ^ 2 ) e. CC )
-> ( 2
x.
( ( ( normh ` &S8 ) ^ 2 )
+
( ( normh ` &S9 ) ^ 2 ) ) )
= ( ( 2 x. ( ( normh ` &S8 ) ^ 2 ) )
+
( 2 x. ( ( normh ` &S9 ) ^ 2 ) ) ) )
47::normclt |- ( &S8 e. H~ -> ( normh ` &S8 ) e. RR )
48:47:recnd |- ( &S8 e. H~ -> ( normh ` &S8 ) e. CC )
49::sqclt |- ( ( normh ` &S8 ) e. CC
-> ( ( normh ` &S8 ) ^ 2 ) e. CC )
50:48,49:syl |- ( &S8 e. H~
-> ( ( normh ` &S8 ) ^ 2 ) e. CC )
51::normclt |- ( &S9 e. H~ -> ( normh ` &S9 ) e. RR )
52:51:recnd |- ( &S9 e. H~ -> ( normh ` &S9 ) e. CC )
53::sqclt |- ( ( normh ` &S9 ) e. CC
-> ( ( normh ` &S9 ) ^ 2 ) e. CC )
54:52,53:syl |- ( &S9 e. H~
-> ( ( normh ` &S9 ) ^ 2 ) e. CC )
55:46,50,54:syl2an |- ( ( &S8 e. H~ /\ &S9 e. H~ )
-> ( 2
x.
( ( ( normh ` &S8 ) ^ 2 )
+
( ( normh ` &S9 ) ^ 2 ) ) )
= ( ( 2 x. ( ( normh ` &S8 ) ^ 2 ) )
+
( 2 x. ( ( normh ` &S9 ) ^ 2 ) ) ) )
56:25,43,55:3eqtr4d
|- ( ( &S8 e. H~ /\ &S9 e. H~ )
-> ( ( ( normh ` ( &S8 +h &S9 ) ) ^ 2 )
+
( ( normh
` ( &S8 +h ( -u 1 .h &S9 ) ) )
^
2 ) )
= ( 2
x.
( ( ( normh ` &S8 ) ^ 2 )
+
( ( normh ` &S9 ) ^ 2 ) ) ) )
57:56:rgen2 |- A. &S8
e. H~
A. &S9
e. H~
( ( ( normh ` ( &S8 +h &S9 ) ) ^ 2 )
+
( ( normh
` ( &S8 +h ( -u 1 .h &S9 ) ) )
^
2 ) )
= ( 2
x.
( ( ( normh ` &S8 ) ^ 2 )
+
( ( normh ` &S9 ) ^ 2 ) ) )
58:23,24,57:mpbir2an
|- <. <. +h , .h >. , normh >. e. CPreHil
qed:1,9,58:mpbir2an
|- <. <. +h , .h >. , normh >. e. CHil $= cva csm cop cno cop chl wcel cva csm cop cno cop cbn wcel cva csm
cop cno cop cphl wcel cva csm cop cno cop ishlg cva csm cop cno
cop cbn wcel cva csm cop cno cop cncv wcel cva csm cop cno cop cims
cfv cms wcel cva csm cop cno cop isbn hilncv cva csm cop cno cop
cims cfv chil &S4 cv chil wcel &S5 cv chil wcel wa &S6 cv &S4 cv &S5
cv cmv co cno cfv wceq wa &S4 &S5 &S6 copab2 cop cms &S4 &S5 &S6
&S4 cv chil wcel &S5 cv chil wcel wa &S6 cv &S4 cv &S5 cv cmv co cno
cfv wceq wa &S4 &S5 &S6 copab2 &S4 cv chil wcel &S5 cv chil wcel
wa &S6 cv &S4 cv &S5 cv cmv co cno cfv wceq wa &S4 &S5 &S6 copab2
eqid hilims &S4 &S5 &S6 &S4 cv chil wcel &S5 cv chil wcel wa &S6 cv
&S4 cv &S5 cv cmv co cno cfv wceq wa &S4 &S5 &S6 copab2 &S4 cv chil
wcel &S5 cv chil wcel wa &S6 cv &S4 cv &S5 cv cmv co cno cfv wceq wa
&S4 &S5 &S6 copab2 eqid hilcms eqeltr mpbir2an cva csm cop cno cop
cphl wcel cva csm cop cno cop cncv wcel &S8 cv &S9 cv cva co cno cfv
c2 cexp co &S8 cv c1 cneg &S9 cv csm co cva co cno cfv c2 cexp co
caddc co c2 &S8 cv cno cfv c2 cexp co &S9 cv cno cfv c2 cexp co caddc
co cmul co wceq &S9 chil wral &S8 chil wral cva cvv wcel csm cvv
wcel cno cvv wcel cva csm cop cno cop cphl wcel cva csm cop cno cop
cncv wcel &S8 cv &S9 cv cva co cno cfv c2 cexp co &S8 cv c1 cneg &S9
cv csm co cva co cno cfv c2 cexp co caddc co c2 &S8 cv cno cfv c2
cexp co &S9 cv cno cfv c2 cexp co caddc co cmul co wceq &S9 chil wral
&S8 chil wral wa wb cva cabl hilabl elisseti hvmulex cno &S3 cv
chil wcel &S7 cv &S3 cv &S3 cv csp co csqr cfv wceq wa &S3 &S7 copab
cvv &S3 &S7 df-hnorm &S3 &S7 chil &S3 cv &S3 cv csp co csqr cfv
ax-hilex funopabex2 eqeltr &S8 &S9 cvv cvv cvv csm cva cno chil cva chil
cva cabl wcel cva cgr wcel hilabl cva ablgrp ax-mp ax-hfvadd grprn
isphg mp3an hilncv &S8 cv &S9 cv cva co cno cfv c2 cexp co &S8 cv c1
cneg &S9 cv csm co cva co cno cfv c2 cexp co caddc co c2 &S8 cv cno
cfv c2 cexp co &S9 cv cno cfv c2 cexp co caddc co cmul co wceq &S8
&S9 chil &S8 cv chil wcel &S9 cv chil wcel wa &S8 cv &S9 cv cmv co
cno cfv c2 cexp co &S8 cv &S9 cv cva co cno cfv c2 cexp co caddc co
c2 &S8 cv cno cfv c2 cexp co cmul co c2 &S9 cv cno cfv c2 cexp co
cmul co caddc co &S8 cv &S9 cv cva co cno cfv c2 cexp co &S8 cv c1
cneg &S9 cv csm co cva co cno cfv c2 cexp co caddc co c2 &S8 cv cno
cfv c2 cexp co &S9 cv cno cfv c2 cexp co caddc co cmul co &S8 cv &S9
cv normpart &S8 cv chil wcel &S9 cv chil wcel wa &S8 cv &S9 cv
cva co cno cfv c2 cexp co &S8 cv &S9 cv cmv co cno cfv c2 cexp co
caddc co &S8 cv &S9 cv cva co cno cfv c2 cexp co &S8 cv c1 cneg &S9 cv
csm co cva co cno cfv c2 cexp co caddc co &S8 cv &S9 cv cmv co
cno cfv c2 cexp co &S8 cv &S9 cv cva co cno cfv c2 cexp co caddc co
&S8 cv chil wcel &S9 cv chil wcel wa &S8 cv &S9 cv cmv co cno cfv c2
cexp co &S8 cv c1 cneg &S9 cv csm co cva co cno cfv c2 cexp co
&S8 cv &S9 cv cva co cno cfv c2 cexp co caddc &S8 cv chil wcel &S9
cv chil wcel wa &S8 cv &S9 cv cmv co cno cfv &S8 cv c1 cneg &S9 cv
csm co cva co cno cfv c2 cexp &S8 cv chil wcel &S9 cv chil wcel wa
&S8 cv &S9 cv cmv co &S8 cv c1 cneg &S9 cv csm co cva co cno &S8 cv
&S9 cv hvsubvalt fveq2d opreq1d opreq2d &S8 cv &S9 cv cva co cno cfv
c2 cexp co cc wcel &S8 cv &S9 cv cmv co cno cfv c2 cexp co cc
wcel &S8 cv &S9 cv cva co cno cfv c2 cexp co &S8 cv &S9 cv cmv co cno
cfv c2 cexp co caddc co &S8 cv &S9 cv cmv co cno cfv c2 cexp co
&S8 cv &S9 cv cva co cno cfv c2 cexp co caddc co wceq &S8 cv chil
wcel &S9 cv chil wcel wa &S8 cv &S9 cv cva co cno cfv c2 cexp co &S8
cv &S9 cv cmv co cno cfv c2 cexp co axaddcom &S8 cv chil wcel &S9
cv chil wcel wa &S8 cv &S9 cv cva co cno cfv cc wcel &S8 cv &S9 cv
cva co cno cfv c2 cexp co cc wcel &S8 cv chil wcel &S9 cv chil wcel
wa &S8 cv &S9 cv cva co cno cfv &S8 cv chil wcel &S9 cv chil wcel
wa &S8 cv &S9 cv cva co chil wcel &S8 cv &S9 cv cva co cno cfv cr
wcel &S8 cv &S9 cv hvaddclt &S8 cv &S9 cv cva co normclt syl recnd
&S8 cv &S9 cv cva co cno cfv sqclt syl &S8 cv chil wcel &S9 cv chil
wcel wa &S8 cv &S9 cv cmv co chil wcel &S8 cv &S9 cv cmv co cno cfv
cc wcel &S8 cv &S9 cv cmv co cno cfv c2 cexp co cc wcel &S8 cv &S9
cv hvsubclt &S8 cv &S9 cv cmv co chil wcel &S8 cv &S9 cv cmv co cno
cfv &S8 cv &S9 cv cmv co normclt recnd &S8 cv &S9 cv cmv co cno
cfv sqclt 3syl sylanc eqtr3d &S8 cv cno cfv c2 cexp co cc wcel &S9
cv cno cfv c2 cexp co cc wcel c2 &S8 cv cno cfv c2 cexp co &S9 cv
cno cfv c2 cexp co caddc co cmul co c2 &S8 cv cno cfv c2 cexp co
cmul co c2 &S9 cv cno cfv c2 cexp co cmul co caddc co wceq &S8 cv
chil wcel &S9 cv chil wcel c2 cc wcel &S8 cv cno cfv c2 cexp co cc
wcel &S9 cv cno cfv c2 cexp co cc wcel c2 &S8 cv cno cfv c2 cexp co
&S9 cv cno cfv c2 cexp co caddc co cmul co c2 &S8 cv cno cfv c2 cexp
co cmul co c2 &S9 cv cno cfv c2 cexp co cmul co caddc co wceq 2cn
c2 &S8 cv cno cfv c2 cexp co &S9 cv cno cfv c2 cexp co axdistr
mp3an1 &S8 cv chil wcel &S8 cv cno cfv cc wcel &S8 cv cno cfv c2 cexp
co cc wcel &S8 cv chil wcel &S8 cv cno cfv &S8 cv normclt recnd &S8
cv cno cfv sqclt syl &S9 cv chil wcel &S9 cv cno cfv cc wcel &S9
cv cno cfv c2 cexp co cc wcel &S9 cv chil wcel &S9 cv cno cfv &S9
cv normclt recnd &S9 cv cno cfv sqclt syl syl2an 3eqtr4d rgen2
mpbir2an mpbir2an $.
$)
big.mm
Well, the new mmj2 Work Variables Enhancement has no problem dealing with "big.mm". The Proof Worksheet below unifies with no problems (you can tell it requires a lot of work because the round-trip response time from Ctrl-U to screen output takes about 1/2 second. I hope big.mm becomes part of the official Metamath family, alongside set.mm, ql.mm and peano.mm. This test will definitely be part of the mmj2 test suite!
$( <MM> <PROOF_ASST> THEOREM=theorem1 LOC_AFTER=?
1::ax-min
2::ax-maj
qed:1,2:ax-mp |- e
( e
( e
( x
, e
( y
, e ( e ( e ( y , z ) , e ( u , z ) ) , u ) ) )
, v )
, e ( x , v ) )
$)
July 10 Beta Release Status Update
All proofs for theorems from set.mm Version of 17-May-2007 have been generated by the new mmj2 Work Variables Enhancement code using just the derivation step labels (in RPN order) plus the 'qed' and hypothesis step formulas…except for these theorems:
merlem3
merlem5
merlem8
merlem10
merlem11
merlem13
For these mer* theorems an inadequate number of dummy wff variables in scope were available. To resolve this issue I recommend adding 5 new wff vars and var hyps in local scope. Alternatively, not adding new wff variables will provide a good function test each time mmj2's "BatchTest?,*" is run :-)
Two "spec" errors were discovered during testing:
1) The unification "occurs in" checking as specified in Robinson's algoritm needed to be modified for StepUnifier?.java due to its use of Work Variables – updates of target variables back into the source variables (theorem "mandatory" variables) are converted to updates to Work Variables to emulate a one-way unification. In practice this means that Work Variable "renames" occur, so that these incoming assignments might be seen:
&W1 :=
&W2 := &W1
&W1 := &W3
&W3 := &W2
&W1 := &W3
&W1 := &W1
As long as the mmj2 code doesn't actually store a recursive loop, and correctly detects that these are just renames – and this case leaving &W1 as the final (un-updated) Work Variable, everything is ok.
This seems weird and dangerous, but as long as the variable assignments are consistent and just involve subtrees with level = 1 (renames), it is valid.
2) The final update of Work Variables left in the proof after unification of the 'qed' step, converting them into dummy variables must take into account each step's formula Work Variables plus the step's hypotheses' Work Variables. So, when dummy variables are assigned, they will be disjoint with the set of dummy variables in the step and its hypotheses.
- * *
I plan to enhance the "BatchTest?,*" feature with a "Retest" option that will reprocess the output (ASCII) Proof Worksheet after unification and $d generation. The reason this is necessary is that there already is a "RecheckProofAsstUsingProofVerifier?,yes" RunParm?, but at present the generated $d's are not merged back into the .mm data loaded in core (that is a test-only feature – mmj2 never updates the .mm data from the input file.) So this will read back in any generated $d's – and it will serve as a recheck of the screen-output processing (after reformatting, Work Variable converstion, etc.)
Until I add this final "Retest" feature I won't be able to state with 99% confidence that the code is correct. I'm feeling pretty good about the whole thing now… BUT…there were 11 bugs, an unusually high number for a mere 20K of executable code!
sooo…seem to be on target for a July 10 "beta" release!