This page discusses various topics and subprojects in set.mm (the set theory database for metamath).
This page replaces set.mm discussion, which should no longer be used due to spam activity. All new discussion should be added to this page, not that one.
- That page has been set off-limits in the web server, so it will be neither postable by spammers nor indexed by search engines. --akrowne
- It's not a good idea. They will notice their script has stopped working and they will try to write into another page – fl
Cartesian products
I don't quite understand df-ixp. In a recent copy of set.mm, it is:
$a |- X_ x e. A B = { f | ( f Fn A /\ A. x e. A ( f ` x ) e. B ) } $.How does B depend on x? That appears to me to be limited to the case where a cartesian product is taken with all factors the same set, which makes things like ac9s trivial.
In other words, why isn't the definition something more like:
$a |- X_ x e. A B = { f | ( f Fn A /\ A. x e. A ( f ` x ) e. ( B ` x ) } $.?
Am I missing something here?
Answer
This is an excellent question, which I answered in the "mmnotes.txt" for 7-Mar-05. Unfortunately the theorem it references was made obsolete and was deleted, so I'll rewrite it for ac9s.
- The class B is normally dependent on x, i.e. in an application, x would normally occur as a free variable in the class expression substituted for B. In other words, B should be thought of as B(x). The way you can tell is that B and x are not both in the same distinct variable group, yet B is in the scope of bound variable x. This is an important principle that confuses some people. We also know that A is not dependent on x because A and x must be distinct.
Note, by the way, that I mention B(x) in the description of ac9s to assist the reader, and I should probably do that more often.
There is also a discussion about this in the mmnotes.txt for 11-May-06 regarding the similar situation in sumeqfv, which nicely illustrates how we can also use an explicit function value in place of an implicit A(k). To do this, we normally need to define the function separately, as in the 2nd hypothesis of sumeqfv, in order to be able to prove this kind of theorem. The theorem sumeqfv also illustrates a related point that can be confusing: in that theorem, we don't have a distinct variable group for k and F, but we have the equivalent situation: k is (and must be) bound, i.e. not free, in F. Normally this would be expressed with the hypothesis "( z e. F → A. k z e. F )" (where z is a dummy variable), but in this case that hypothesis would be redundant since it is implied by the second hypothesis that makes a fixed assignment to F. That k is effectively not free in F is then deduced from hbopab1.
In the case of elixp, note that x and A (as well as x and B) aren't in the same distinct variable group. This is because the definition df-ixp doesn't require it (and has no reason to), and in principle we could indeed think of A as A(x) in df-ixp and elixp. However, in most practical applications of the definition, such as ac9s above, a distinct variable requirement on x and A will naturally arise as part of the proof, so that A will become a constant independent of x, as it is in most textbooks.
In elixp, F and x are in the same distinct variable group. With some manipulations, we could eliminate this requirement and replace it with the hypothesis "( z e. F → A. x z e. F )". Still, we wouldn't think of F as F(x) in that case (which would lead to the odd-looking F(x)`x), since x cannot be a free variable in a class expression substituted for F, even though x may occur bound in F.
A theorem I added today, mapixp, shows what happens when we do make B a constant.
--norm 2 Oct 2006
Thanks! Great reply! (I'd actually figured it out myself, but I've got to admit I still think of the way metamath has no variable scope as weird, and had taken to ignoring it even in cases like this, where I shouldn't have).
Would the definition using a function B and B ` x work as well (even if it's less convenient)?
- Well, I don't know what specific proposal you have in mind. It should be possible to prove something like sumeqfv, but as a definition the argument would be limited to function values rather than general class expressions containing a free variable.
I might have a go at proving that later, but I'm still quite bad with metamath's proofs (it took me about 12 hours to prove A. x ( x e. RR → x < ( x + 1 ) ) :-) ).
- I can understand how Metamath can be frustrating in the beginning. The way I would prove this would be to apply ax-gen to ltp1t (2 steps). While I remember the label ax-gen since I use it frequently, to find ltp1t I would "search * '
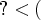 ? + 1 )'" in the metamath program, since I vaguely remember that A<A+1 is in the database. If you're just starting off, "search * <" can give you a general feel for the kinds of theorems available for <. The wildcard sequence
? + 1 )'" in the metamath program, since I vaguely remember that A<A+1 is in the database. If you're just starting off, "search * <" can give you a general feel for the kinds of theorems available for <. The wildcard sequence 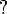 ? will match a token with 2 characters such as ph, and $* will match any string of tokens. By the way, this particular theorem can also be proved automatically with "improve all /depth 1". But don't expect that very often. --norm 4 Oct 2006
? will match a token with 2 characters such as ph, and $* will match any string of tokens. By the way, this particular theorem can also be proved automatically with "improve all /depth 1". But don't expect that very often. --norm 4 Oct 2006
Topology
Today I have come across the definition of a topology in set.mm and the theorem saying that an empty set is always an open subset of a topology. Some times before I had read the same definition and the same theorem in Bourbaki and it had not been clear : many questions had remained in my mind. On the contrary in metamath this theorem and this definition were perfectly clear. There are three reasons for this phenomenon in my opinion. 1 - Bourbaki is written in a natural language. And the words of a natural language (even those of a treatise of mathematics) have always several meanings. On the contrary in metamath each symbol has a single value. 2 - When you don't know the meaning of a concept in Bourbaki it can be painful to find it. In metamath hyperlinks lead you to the meaning of an unknown symbol. 3 - In Bourbaki demonstration can be missing ( left to the reader… in the most sadistic way ). In metamath demonstration is always given. For these reasons I think metamath can be a very good pedagogical tool.
– frl 13-Jul-2006
- Another example is in Munkres' Topology: A First Course. On p. 79 in the proof that every basis generates a topology, he says "there is some basis element B containing x and contained in X." I figured out that "B containing x" means "x is an element of B", whereas "contained in X" means "is a subset of X". But it wasted my time, and it would have taken no more room just to use "included in X" (inclusion = subset).
- This isn't the only book with this problem: I have a mathematical physics book where I literally cannot figure out some of the definitions because I don't know if by "contains" the authors mean element or subset, since they use that word for both. --norm
- .
- I came across A Handbook of Mathematical Discourse by Charles Wells, which is a rather amazing, meticulously referenced 558-page compilation of the nuances of informal mathematical language. For example, he mentions the ambiguous usage of "contains" and says, "Halmos, in [Steenrod et al., 1975], page 40, recommends using 'contain' for the membership relation and 'include' for the inclusion relation." --norm 15-Sep-2006
Stefan planned to prove the following theorems before he was pulled away on something else. Perhaps you'd like to give them a try.
${
$( The indiscrete topology on a set ` A ` is a topology. $)
indistop.1 $e |- A e. V $.
indistop $p |- { (/) , A } e. Top $=
? $.
$} ${
$( The discrete topology on a set ` A ` is a topology $)
distop.1 $e |- A e. V $.
distop $p |- P~ A e. Top $=
? $.
$} ${
$( The indiscrete topology on a set ` A ` is a topological space. $)
indistsp.1 $e |- A e. V $.
indistsp $p |- <. A , { (/) , A } >. e. TopSp $=
? $.
$} ${
$( The discrete topology on a set ` A ` is a topological space. $)
distsp.1 $e |- A e. V $.
distsp $p |- <. A , P~ A >. e. TopSp $=
? $.
$}In our email discussions, the following existing theorems were mentioned regarding Stefan's plans for topology, some of which I added specifically for that purpose: sspr prss prssg 4cases sssn f1dom f1oen brdom bren fodom fodomb difsn difprsn unifi unifi2 iunfi. Some of these are probably relevant to the above, in particular sspr.
--norm 14-Jul-2006
I'll try though I'm not really accustomed to the hilbert style of proving. Today is French Revolution commemoration as you perhaps know and I hope it is a good presage.
– frl 14-Jul-2006
You might want to take a close look at sn0top. I would guess that the proof of indistop would resemble it, using sspr in place of sssn, and in what corresponds to step 22 you would use jaoi twice instead of once. In any case if you want to start it, and see how far you can get - the last 2 steps would certainly be mpbir followed by elopen1 - I could complete it later.
--norm 15-Jul-2006
Update: frl has done the proofs for indistop, distop and indistps. I guess he didn't find the hilbert style of proving so daunting after all. :) Good job, frl!
--norm 19-Jul-2006
Formalization of a theorem of Bourbaki
Here is a translation of a theorem of Bourbaki:
If we associate a set V(x) of parts of X to each element x of a set X such as the properties Vi, Vii, Viii, Viv are true, there exists only one topological structure such as, for each x of X, V(x) is the set of neighborhoods of x for this topology.
Vi - Every part of X which contains a set of V(x) belongs to V(x).
Vii - Every finite intersection of V(x) belongs to V(x).
Viii - The element x belongs to every set of V(x).
Viv - If V belongs to V(x), there exists a set W belonging to V(x) such as for every y e. W, V belongs to V(y).
I think I have succeded in formalizing the greatest part of the proposition but the property Viv is recursive and I don't succeed in integrating it to my formalization.
Here is the beginning of my attempt of formalization:
nei2 = { <. x , y >. | ( ( ( u e. y /\ u (_ v ) -> v e. y ) /\
( ( u e. y /\ v e. y ) -> ( u i^i v ) e. y ) /\
( u e. y -> x e. y ) /\
Here Viv is missing ) }– frl 5-Oct-2006
The Bourbaki excerpt is a little confusing, but I'll try to get you started. First, you don't want a set of ordered pairs; you want the collection of V(x)'s, each of which is a subset of X. Second, your original attempt doesn't reference the starting set X, so it is kind of meaningless. Third, a recursive set can be defined using intersection. See for example the set.mm definition of natural numbers dfnn2. Basically, you take the intersection (i.e. obtain the smallest) of all possible sets with the desired properties. So it might be something like:
|^| { v | v (_ P~ X /\ A. x e. X E. u e. v ..... }where u is what Bourbaki calls V(x). Inside of that E. u, there would be an …E. w e. v… where w would be the V(y). You must show that {v |…} has at least one member in order for the intersection to exist. You would then prove that this final intersection is the set of neighborhoods of exactly one topology.
Offhand, although I'm not sure, this vaguely reminds me of a subbasis for a topology - where for any set X, you can obtain a basis for a topology for that X, and thus the topology itself - and you might want to take a look at the theorems related to subbases that are already in set.mm to see if there is anything that might be helpful.
--norm 5 Oct 2006
Thank you Norm, I had a look to dfnn2. I think I would have never understood by myself that the intersection is asked by the recursive nature of the definition and the necessity to get the smallest set but with your explanations it's perfectly clear.
--frl 6 Oct 2006
An analogy
Norm, do the parallels between Metamath and first-order logic mean anything?
| Metamath | set.mm, |- domain |
| Metamath's rule of production | ax-mp |
| "=>" | → |
| multiple hypotheses ("&") | /\ |
| $v hypotheses | A. quantification |
| $d x y | -. A. x x = y |
I'm inclined to think there's some big-picture philosophical meaning, but nothing particularly relevant to the average person working with Metamath and set.mm.
Still, it's such a hall of mirrors in here…
--jorend 6 Dec 2006
I think I can answer a bit. You should have a look at nat.mm. And you would discover a realm of strange analogies. To be precise however an inference ( => ) is not an implication (->). If you compare 19.20 and 19.20i you will remark that Norm had to quantify the antecedent in 19.20 and that he didn't quantify the premisse in 19.20i (because it was useless). – fl 6-Dec-2006
Hi, jorend. This is a neat picture, but as they say, the devil is in the details, and when you get down to the actual rules of working with the two pictures - i.e. manipulating the symbols in their respective formal systems - I believe the divergence is significant.
As fl suggested, there are some good parallels between the |- of a Gentzen system and the → of a Hilbert-style system (as well as important differences), and what you are seeing with & vs. /\ and => vs. → are along the same lines. One thing you might want to mull over with respect to those parallels is the standard deduction theorem.
- In my opinion it is rather the (informal) => that corresponds to the |- of a Gentzen-style system. In fact I think that the inferences of set.mm are the formulas of nat.mm. What you (informally) note "ph & ps => ch" corresponds to the nat.mm "[ [ [] , ph ] , ps ] |- ch". – fl
- And obviously there is also an analogy between "[ [ [] , ph ] , ps ] |- ch" and "( ph → ( ps → ch ) )" or "( ( ph /\ ps ) → ch )". Anyway as you say the details are important and don't allow to follow the analogy too far. – fl
At the level of Metamath's system as a whole vs. the set.mm logic axioms it describes, I don't think the parallels are as clean as your table suggests. The metalogic of the Metamath language (and a stand-alone Ghilbert module without definitions, I believe) can be described in set-theoretical terms by the formal system in Appendix C of the Metamath book, and that is what you have to deal with if you want to make the comparison rigorous. (I believe that Appendix is correct: incredibly, Bob Solovay thought that it was the spec and learned how the Metamath language worked from it. He even found an error that has since been corrected - so he has effectively given it his blessing.) As you can see, it's somewhat complicated, although less so than the metalogic behind standard predicate calculus as described e.g. by Tarski. – norm 6 Dec 2006
Thanks, fl and Norm.
It is always a little sad to find that a mapping doesn't preserve any nice properties… but that's what I expected.
The Deduction Theorem is actually what brought up the question. I thought: it would be awfully cool if you could prove that metatheorem in Metamath, and then be able to use it directly, avoiding the rigmarole of dedth. I could sort of see a way to do this:…
First, you would have to define a set-theoretic construction of Metamath. (I didn't know about Appendix C at the time, but that's exactly what I mean.) Feed it into Metamath (since "set.mm" is set theory on Metamath, you could call this "mm.set.mm"--Metamath on set theory on Metamath). Call the "real" Metamath "level 0" and this "embedded" Metamath "level 1".
Then you would introduce a new axiom: If a level-1 proof exists for a given level-1 statement, then the corresponding level-0 statement is true. That is,
${
ax-lift.1 $e |- E. x ( x mmProves y ) $( There exists a proof x of the level-1 statement y $)
ax-lift.2 $e |- ( y mmRepresents ph ) $( y is the level-1 representation of the level-0 wff ph $)
ax-lift $a |- ph
$}The intent is that you can "lift" theorems from level 1 to level 0. The motivation is, you could lift the Deduction Theorem (or at least some weaker version of it). More generally, "existence-of-proof proofs" would become expressible, verifiable, and useable in Metamath.
Practicality aside, there are two huge problems here. First, you can only lift theorems of the form "|- wff". No $e hypotheses; no $d constraints. Second, how do you know the level-1 system has all the same axioms as the level-0 system? This is the same problem in a different guise: you could define the set of level-1 axioms as exactly those things which you can "push down" from the level-0 system, but how do you write an axiom that lets you push down a $v? Or a rule involving $e and/or $d?
(sigh) If only there were a way to use wffs to talk about other parts of Metamath. Hence my question.
Is there really no way to do this?
(Surely this is all well-trodden ground in metalogic; I don't know where to look to read up on it though.)
--jorend 8 Dec 2006
The concept you are talking about is called reflection. You might want to take a look at John Harrison's "Metatheory and Reflection in Theorem Proving: A Survey and Critique."
A long time ago I briefly considered the idea of having Metamath talk about itself. Disregarding that I may not have been approaching it right to begin with, it looked like the notation to work at the "meta" level was going to be cumbersome, and it wasn't clear that it would buy anything in the end (the Deduction Theorem was one thing I had in mind). At least for the math I was interested in doing, normal proofs didn't seem to be a problem, and they don't involve a nonstandard reflection axiom that seemed uncomfortably outside of what ZFC (the supposed foundation for mathematics) is capable of expressing. Overall it didn't seem to be in the spirit of what I wanted to accomplish, so I didn't pursue it. I can understand that in principle there might be theorems whose proofs could be made more compact by proving that a proof exists, but I don't think any proof I've done so far would benefit, particularly given the overhead that would be involved in jumping between meta levels. It might be interesting to reconsider in light of Harrison's paper, but I don't think I will be doing myself any time soon. The issue of consistency seems very subtle and tricky, and I'm not sure that I'm competent to prove it. – norm 8 Dec 2006
Norm, thanks again, especially for the link. You're awfully generous with your time. --jorend 11 Dec 2006
Ack! I think ax-lift is inconsistent with set.mm!! I think ax-lift essentially claims that (set.mm+ax-lift) is consistent. So, by Gödel's second incompleteness theorem, it isn't. I'm still trying to digest this. --jorend 17 Jan 2007
Sums
Hi Norm,
I want to prove this lemme:
sum_ k e. ( 1 ... ( N + 1 ) ) ( k ^ 2 ) = sum_ k e. ( 0 ... N ) ( ( k + 1 ) ^ 2 )
I think that I have to modify the formula to make sequences (seq) appear. I'm right or is there something simpler ? – fl 8-Dec-2006
No low-level seq stuff should be necessary. Use fsumshft, csbopr1g, csbvarg, and cbvsum. – norm
Images
Hi Norm,
we have ( ( F o. G ) ' P ) = ( F ' ( G ' P ) ). But can we say that ( ( F o. G ) " A ) = ( F " ( G " A ) ) ? – fl 11-Dec-2006
fl, It's true not only for functions but for relations generally. Try this (probably pretty clunky; this is my second proof):
${
$d x y z F $.
$d x y z G $.
$d x y z A $.
imvco $p |- ( ( F o. G ) " A ) = ( F " ( G " A ) ) $=
( vz vy vx ccom cima cv wcel wbr wrex wa wex visset elima brco rexbii
bitr rexcom4 r19.41v exbii anbi1i bitr4 df-rex eqriv ) DBCGZAHZBCAHZHZDIZ
UHJZEIZUKBKZEUILZUKUJJULUMUIJZUNMZENZUOULFIZUMCKZFALZUNMZENZURULUTUNMZFAL
ZENZVCULVDENZFALZVFULUSUKUGKZFALVHFUKUGADOZPVIVGFAEUSUKBCFOVJQRSVDFEATSVE
VBEUTUNFAUAUBSUQVBEUPVAUNFUMCAEOPUCUBUDUNEUIUEUDEUKBUIVJPUDUF $.
$( [?] $) $( [11-Dec-2006] $)
$}--jorend 11 Dec 2006
Thank you a lot jorend. Impossible to find this by myself. I'm ashamed :-) fl
- Absolutely no need to feel ashamed. What we're seeing here is the very beginning of a real community where people are collaborating on proving theorems in the set.mm universe. There's nothing at all wrong with asking for help, as it's one of the very best ways to learn. raph
- In fact I was moderatly ashamed. :-) I've given up the idea of being a mathematical genius many years ago. – fl
I like this theorem, so I added it here: imaco – norm 12 Dec 2006
V
I knew that ( A e. B → A e. V ). I've just discovered that -. V e. V and that ( V C_ A <→ A = V ). And I've realized that -. V e. A. V has very strange properties.
But then a question comes to my mind. Category theory deals with classes like V or the class of all groups or the class of all vector spaces. Does it mean that these three classes don't belong to a larger class ? And to say the things loosely that there is a sort of equivalence between them. – fl 29-Dec-2006
Category theory cannot be done using the existing definitions of the class of all groups, etc. in the set.mm database, since those objects are proper classes. Instead, these objects would have to be redefined to be members of a set that models ZFC set theory (i.e that ZFC set theory can be done inside of), called a Grothendieck universe. This is the intended purpose of Grothendieck's axiom ax-groth. The form of this axiom is taken from Mizar's version (which is the shortest equivalent that I know of), and my idea is that category theory would be developed in set.mm in the same way that it is in Mizar.
The following is a quote from Bob Solovay, that is reproduced in the Preface of the Metamath book:
- "This axiom is how Grothendieck presents category theory. To each inaccessible cardinal
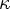 one associates a Grothendieck universe
one associates a Grothendieck universe 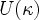 . consists of those sets which lie in a transitive set of cardinality less than . Instead of the ``category of all groups,'' one works relative to a universe [considering the category of groups of cardinality less than ]. Now the category whose objects are all categories ``relative'' to the universe '' will be a category not relative to this universe but to the next universe.
. consists of those sets which lie in a transitive set of cardinality less than . Instead of the ``category of all groups,'' one works relative to a universe [considering the category of groups of cardinality less than ]. Now the category whose objects are all categories ``relative'' to the universe '' will be a category not relative to this universe but to the next universe. - "All of the things category theorists like to do can be done in this framework. The only controversial point is whether the Grothendieck axiom is too strong for the needs of category theorists. Mac Lane argues that ``one universe is enough'' and Feferman has argued that one can get by with ordinary ZFC. I don't find Feferman's arguments persausive. Mac Lane may be right, but when I think about category theory I do it à la Grothendieck.
- "By the way Mizar adds the axiom ``there is a proper class of inaccessibles'' precisely so as to do category theory."
Wikipedia also has a page on Tarski-Grothendieck set theory that says, "Unlike Von Neumann–Bernays–Gödel set theory, TG does not provide for proper classes containing all sets of a particular type, such as the class of all cardinal numbers or the class of all sets. It therefore does not support category theory or model theory directly. However, such theories can be approximated using suitable constructions on inaccessible cardinals." I am by no means an expert on this, but I believe this information is misleading. First, unlike what it implicitly suggests, NBG cannot do category theory, because even though it can quantify over proper classes, proper classes cannot belong to any other proper class, making it useless for that purpose. Second, Bob's statement above seems to suggest that Grothendieck's axiom is sufficient for category theory, not just an "approximation" of it.
Beyond that, I claim no expertise in the matter, and would suggest that Mizar's development of category theory would be the one to study as the next step, with the goal of eventually translating it to set.mm. An ideal situation would be to use the same Grp, Top, etc. objects for those existing theories in set.mm as would be used for category theory, but we would have to rework the definitions of them, since right now they are proper classes. I do not plan to do this myself in the near future, but it would certainly be a very desirable thing for someone to pursue (and as a bonus end up learning category theory in a very rigorous way at the same time). – norm 29 Dec 2006
$d's and meta vs. object language
Hi Norm, I apologize in advance if this question seems particularly dense, or lazy. I want to nail down in my mind the application of $d's. Take set.mm, for example. It is written in a meta-language, the subject language and discusses an object language. If we stipulate that the object language contains the same symbols and convert a meta-theorem into an instance of the theorem in the object language, then by virtue of the metalogical proof of the metatheorem, the object language instance of that theorem is also valid – and assuming that the object language version of the formula is expressed with properly distinct variables, then the object language formula can be validly manipulated using "proper substitution" and the usual mechanisms of formal logic. In essence, a specific instance of the metatheorem generated into the object language is valid and no further use of distinct variables would be required assuming proper substitutions are obeyed. Yes? Any caveats?
P.S. The context of this question is that I am investigating OMDoc with a tenative goal of converting Metamath .mm files to OMDoc format – and perhaps vice-versa. The idea is that as a common format, or "software bus", OMDoc would enable us to send a new set.mm theorem to the various provers, get a proof back, and then convert the proof back into the original .mm symbols; voilà! The common OMDoc format would also be a worthy target of other projects discussed on this wiki, such as a speech-enabled interface.
--ocat 4-Jan-2007
Answer
In the object language, two individual variables with different names are distinct by definition (simply because they have different names - that's what "distinct" means).
In most formal logic textbooks, and in the Metamath note on schemes, the names of individual variables and the metavariables that range over them are different to avoid confusion. And this confusion is a problem, based on questions I see asked about Metamath; it seems hard to communicate that Metamath is a metamathematical language and not the object language, in spite of its very name. :) The reason may be that superficially its theorem schemes look the same as actual theorems of the object language. I thought this was an advantage, but maybe I should have picked some cryptic glyphs for its metavariables so they would be obviously different.
However, in principle there is no reason why variable and metavariable names can't be same as long as it is clear from context. With this in mind, a (Metamath) theorem scheme having metavariables x, y,… ranging over individual variables can be converted (by switching context) to an object language theorem with individual variables x, y,… simply by dropping any $d's, since $d's are meaningless in the context of actual theorems.
Keep in mind two things. First, this resulting object language theorem will be only one of several possible theorems that the scheme could range over, so in that sense it would be weaker than the original scheme, even though (aside from any $d's that were dropped) it looks identical to the original scheme.
Second, the object language has only individual variables, and there is no such thing as a wff variable. So it is impossible to "translate" a theorem (scheme) of even propositional calculus to the object language by switching contexts in this way. All we can do is pick specific instances of wffs, constructed from individual variables and connectives, to substitute for the wff metavariables of a propositional calculus theorem scheme. The result, of course, is necessarily a much weaker and less general statement than the original scheme. For most predicate calculus provers, this is not a problem because they handle propositional calculus (and schemes of predicate calculus that involve wff metavariables) in the code itself, not with explicit external axioms like Metamath does. Internally, program variables are in effect emulating wff metavariables when they manipulate object language wffs.
To a certain extent, we can emulate wff metavariables in the object language by artificially introducing new predicates into the language. (Set theory itself has only two predicates, equality and membership.) For propositional calculus, we could introduce 0-ary, true/false predicate constants P, Q,… (which could even be called ph, ps,… if you want to have the same names after switching the context). For predicate calculus, we would introduce n-ary predicates such as P(x,y,…) where x,y,… are some variables that aren't in a distinct variable pair with the corresponding wff metavariable ph. However, keep in mind that this emulation isn't perfect: in the object language, a wff cannot be substituted for a predicate symbol - predicate symbols are not variables. However, since the predicate symbols behave in many ways like wff metavariables, under certain circumstances we can carefully jump "outside of the system" with a metalogical rule that lets us pretend that they are, so that we can substitute for an n-ary predicate a wff containing at most the n individual variables in its argument list, or in a more sophisticated system, a wff containing at most those n variables free.
I don't know what languages might support or not support such a feature that emulates wff metavariables in this way. It can get a little clumsy: the 0-ary constants in a propositional calculus theorem actually should be assumed to be oo-ary predicates (infinite number of variables) for full generality, otherwise they would be useless for predicate calculus. Or, at least have all the variables used by the proof, which you don't know in advance what they will be. Similarly, fully general n-ary predicates should have all variables except those that aren't allowed. So it would be more efficient to list what variables aren't allowed - oops, we're getting back to $d's. :) – norm 4 Jan 2007
The category Set
Question
Here is an excerpt of the wikipedia page:
http://en.wikipedia.org/wiki/Category_of_sets
"In mathematics, the category of sets, denoted as Set, is the category whose objects are all sets and whose morphisms are all functions. It is the most basic and the most commonly used category in mathematics.
Because of Russell's paradox, which shows assuming the existence of the set of all sets leads to a contradiction, the object class of Set is a proper class, and thus the category is large."
The reference of the page is Mac Lane, Saunders (September 1998). Categories for the Working Mathematician. Springer. ISBN 0-387-98403-8 (alternate, search). (Volume 5 in the series Graduate Texts in Mathematics)
So it seems it means that we can work in the category theory with V. It's a bit contradictory with what you were saying in our discussion about V. Is there something I've not understood ?
– fl 25-Jan-2006
Answer
I think I answered this in the discussion called "V" above. Basically, ZFC set theory can be modelled inside of a Grothendieck universe. Russell's paradox ru is therefore avoided - the set {x|x e/ x} becomes {x e. U|x e/ x}, where U is a Grothendieck universe that exists (U e. V) by Grothendieck's axiom ax-groth.
Mizar does it this way. One way to learn category theory axiomatics and at the same time put it into set.mm might be to "translate" the Mizar development (by hand, since no converters exist). Some category theory books I've looked at tend to be a little unclear, or hard to understand, about how the axioms can be modelled in set theory (or even what the axioms are), because foundational issues are not their main concern. So the fact that it is actually done in Mizar, using the exact Grothendieck axiom that is present in set.mm, would probably be useful for a very rigorous and clear understanding of the model for the axioms.
Wikipedia can be misleading sometimes. – norm 25 Jan 2007
- I'm happy to learn that, because when I read the article my mind began to wander. Here is the issue of "Formalized Mathematics" which defines a category (p. 409 and followings):
http://mizar.org/fm/1990-1/cont1-2.htm
And the definition of Ens is here ( pp. 527-533 ):
http://mizar.org/fm/1991-2/cont2-4.htm
I find Mizar issues much more difficult to read than Metamath Explorer's pages. But it's perfectly impressive to see they are able to build and to manage such a complicated structure as a category in their second volume. – fl 25-Jan-2007
The Euclidean topology
Question
fl asked me in an email what would be a better way to develop Euclidean topology:
- Introduce Euclidean topology using intervals (following Morris's way - see ''Topology without Tears'' chapter 2, e.g. p. 43)
or
- Introduce Euclidean topology using metric spaces and cnms.
Opinions? – norm 25 Jan 2007
Here is my opinion by the way. Morris's purpose is to be as pedagogical as possible. He needs a very good and useful example: that's the reason why he describes the euclidean topology in its second chapter. He describes metric space much later (chapter 6) and it would be too late to introduce euclidean topology then.
Not sure that in Metamath the purpose is the same.
So describing euclidean topology as a metric space would give us a full access to all the theorems proper to topology as well as to those that are particular to metric space. So I think we should describe euclidean topology as a metric space. – fl 25-Jan-2007
I wrote that it's better to consider euclidean topology as an example of metric space but I'm so eager to ptrove Morris's theorems and to use the new intervals added by Norm to set.mm that in fact I will consider that euclidean topology is defined using intervals. – fl 26-Jan-2007
Metamath and Mizar
Reading the Formalized mathematics journal it comes to my mind that it is a very beautiful work. Sometimes the reason for some decisions are perfectly unclear to me (their art of defining things is a terrible mess compared with metamath's one. I suppose it is due to the fact they had several goals at the same time but, since it is not documented, the rationality behind is out of my reach ). Sometimes they met some difficulties and it is interesting to identify them: for instance it is more difficult to read a mizar proof than a metamath proof because the system of links that allow us to find quickly a theorem or a definition doesn't exist.
However, reading this, the question of the final goal of metamath comes to my mind. Perhaps could you answer this question Norm. What has been driving you for more than 10 years now, daily writing set.mm (which represents a huge work). – fl
The average person is able to watch television 5 hours per day, year in and year out, sometimes for literally decades of their life. That is what I find amazing. In any case, the world is not yet ready to know what the final goal of Metamath is. To reveal it now would upset humanity's world-view, leading to chaos and anarchy. – norm
:-) Lacan would have said that the best strategy to communicate is "mi-dire". (I don't know how to translate that (it's a neologism) "half-tell" perhaps, and in French it is not very far from "médire" ("speak ill")). – fl
Replacing a variable
I have:
|- ( ph -> E. y ( y e. J /\ U. a = ( y i^i Y ) )
I'd like to have (working backward):
|- ( ph -> E. z ( z (_ J /\ U. a = ( U. z i^i Y ) ) )
How can I do that ? fl 5-Apr-2007
It's not clear to me that this is true unless J is a topology and you apply something like uniopnt. But the idea of what you want may be contained in rexxfr and its friends, ralxfr and ralxfrd. You may want to look at examples of how they are used. – norm 6-Apr-2007
Yes J e. Top and uniopnt can be applied. Thank you for the answer. I will try rexxfr. – fl 6-Apr-2006
Hi Norm, I can't solve the problem. So the lemma I need is:
$p |- ( ( J e. Top /\ ph ) -> ( E. y e. J U. a = ( y i^i Y )
<-> E. z ( z C_ J /\ U. a = ( U. z i^i Y ) ) ) ) $= ? $.- Perhaps you should try to prove each direction of the biconditional separately then combine with impbid. For each direction, find an example that satisfies the conclusion, convert the conclusion to existence with cla4ev/rcla4ev, and finally apply 19.23adv/r19.23adv to get existence on the antecedent. Can you solve either direction that way? BTW is this from a book, and if so how does the author prove it? In topology direct proofs are often not possible, and things are proved by constructing elaborate contradictions, in which case the above method may not work. The "ph" does not appear in the conclusion - why is it there? – norm
- ph is there because I have other (non significant) antecedents.
- Then I can tell you for certain that the last step of your proof will be adantr. That will allow us to focus on a simpler subproblem, without wondering if there is a typo in the consequent. :)
- No it doesn't come from a book it is a branch of a theorem. In fact I'm trying to prove that a sub-topology is a topology. You agree that such a step doesn't seem completely silly, don't you ?- fl
- Well, it doesn't seem silly, although I don't know what a sub-topology is - it isn't defined in Munkres. If you mean subbasis, two theorems are subbas and subbas2.
- No in fact in English you call that a subspace topology.
- Well, it doesn't seem silly, although I don't know what a sub-topology is - it isn't defined in Munkres. If you mean subbasis, two theorems are subbas and subbas2.
- ph is there because I have other (non significant) antecedents.
Could you help me because I am as desesperate as an american housewife. I have tried rexxfr or more exactly I have realized a rexxfrd version but I need E. x e. B in both sides of the biimplication. And this is the problem. I have tried a more complicated version:
$p |- ( ( J e. Top /\ ph ) -> ( E. y e. J U. a = ( y i^i Y )
<-> E. y e. J E. z ( y = U. z /\ ( z C_ J /\
U. a = ( U. z i^i Y ) ) ) ) ) $= ? $.but I don't succeed in proving it. – fl
A conjecture
The conjecture is:
|- ( ( Fun F /\ B (_ ( F " A ) ) -> E. x ( x (_ A /\ B = ( F " x ) ) )
How can I prove that ? I vaguely think that it implies to use the axiom of choice (or one of it's derivative). – fl 7-Apr-2007
I put the proof here: ssimaex. The axiom of choice is not required for its proof, so it doesn't imply the axiom of choice. – norm 8-Apr-2007
Oh my god I thought it was an easy proof. Thank you very much. If I understand well in fact your proof consists in deriving ssimaex from fvelima. I mean that fvelima is the most important step in the proof. – fl 8-Apr-2007
It has been made shorter now. Yes, fvelima/fvelimab are important for the proof and are used in 3 places. The overall idea is to show that the set "{ y e. ( A i^i dom F ) | ( F ` y ) e. B }" satisfies the properties required by x, then apply cla4ev. This proves it for "A i^i dom F" in place of A. (We need the dom F restriction so that F ` y is meaningful.) Finally we generalize the result for any A.
By the way, the theorem might also be true assuming just B e. V instead of the stronger A e. V. But I think that would require some powerful machinery involving minimum ranks and Scott's trick scottex. – norm
Hilbert space
I have had a look at your axioms for the Hilbert Space because I wanted to do the same for categories but with your axioms it is perfectly impossible to prove that something is a Hilbert isn't it – fl 14-Apr-2007
I am not sure what you mean. cnhl, for example, proves that the set of complex numbers is a Hilbert space. – norm 14 Apr 2007
- In the Hilbert Space Explorer you begin with a list of axioms and not with a definition don't you ? You have added the definition of the complex Hilbert spaces latter haven't you ? Using the axioms ax-hilex you can't expect to prove that something is a Hilbert space, can you ? – fl
OK, you mean the axioms of the Hilbert Space Explorer. No, by themselves they can't be used to prove that something is a Hilbert space, and they aren't intended for that. They are meant as a simplified abstraction to derive Hilbert space properties by postulating that the object we start with already is a Hilbert space. This makes the development of that theory much simpler.
- I don't understand why you say "a simplified abstraction" ? Does it mean that the properties that your would derive from CHil wouldn't ressemble those axioms ?
- You can derive exactly those axioms from CHil. (It is in the plan.) It is just more awkward to state: for each theorem we will need 5 or 6 additional hypotheses specifying the variables for the various operations, constants, and underlying space.
- I have tried to derive the first axiom of the Hilbert Space Explorer from CHil because I wanted to see exactly how the axioms of the Hilbert Space Explorer and Chil connect together. You can find the result in my sandbox on this wiki. I have used functions in order that the theorem has the feel and look of the axiom in the Explorer. I think that this technic (using function) is interesting because this way theorems are very readable and it prevents cryptic hypothesis of the ( 1st ` ( 1st ` U ) ) style. It is the technic used by categorists to access a category ( functions are called id, obj, morph … ). Using such function I think we can express categories axioms without giving an express definition of Cat and then later it will be easy to give a more precise definition of Cat without having to rewrite all the proofs. Only the proofs of the "axioms" will have to be written. – fl 16-Apr-2007
- The CHil things you show are pretty much what I have in mind eventually, as I have done with earlier structures (such as Id, inv, IndMet, and ip). I am still thinking about the names for these things (I may change ip to .i (dot sub i) and use another one for the Hilbert Space Explorer, and also steal its +v and .s), but I will probably define them for vector spaces generally or at least normed vector spaces - I am a little torn about which - so that they will be more useful (for Banach spaces, etc.) instead of being restricted to Hilbert space. Once they are defined it will be simple to retrofit existing theorems. I still plan to use variables assigned to them in the hypothesis, for reasons I explained in the mmnotes.txt entry of 19-Oct-2006, and your versions can be recovered with equid. Right now Hilbert space with CHil is in the very early stages, and I need to get some general theorems out of the way first. (Also, in a few days I hope to have a proof showing that the H~ structure is in CHil.) What you are saying about predefining id, ob, morph then using them as part of the Cat definition - if I understand you - may be a good way to build up "layers". – norm
- I have tried to derive the first axiom of the Hilbert Space Explorer from CHil because I wanted to see exactly how the axioms of the Hilbert Space Explorer and Chil connect together. You can find the result in my sandbox on this wiki. I have used functions in order that the theorem has the feel and look of the axiom in the Explorer. I think that this technic (using function) is interesting because this way theorems are very readable and it prevents cryptic hypothesis of the ( 1st ` ( 1st ` U ) ) style. It is the technic used by categorists to access a category ( functions are called id, obj, morph … ). Using such function I think we can express categories axioms without giving an express definition of Cat and then later it will be easy to give a more precise definition of Cat without having to rewrite all the proofs. Only the proofs of the "axioms" will have to be written. – fl 16-Apr-2007
- You can derive exactly those axioms from CHil. (It is in the plan.) It is just more awkward to state: for each theorem we will need 5 or 6 additional hypotheses specifying the variables for the various operations, constants, and underlying space.
- Anyway I'd like to use such axioms to implement categories ( because the definition of Cat is too long otherwise ). Is it a good idea ? – fl
- I don't know. The Hilbert Space Explorer (HSE) was done in the days before the foundations for CHil were developed, and philosophically, I much prefer the "pure" (ZFC-only) theorems derived from CHil. However, as you can see, those theorems (and the many earlier ones for vector spaces, groups, etc.) are a little awkward and even somewhat hard to read compared to the corresponding HSE theorems, because of all the hypotheses needed to specify variables for the objects. While I will continue in the CHil direction, there will also be new things added to the HSE just because it's much easier to prove things there. A result in CHil can be referenced in an HSE proof immediately, but adding an existing HSE result under CHil means the proof has to be rewritten - a CHil result cannot reference an HSE result in a proof.
- .
- As for Cat, I don't know the answer. Philosophically I'd like to avoid additional axioms. Mizar is able to do it without additional axioms - that's what Grothendieck's axiom is for; otherwise Grothendieck's axiom is somewhat pointless for ordinary math. What is preventing the careful buildup of layers like is done for CHil? How does Mizar do it? Even if as a practical matter an HSE approach is used in the end, it would still be preferable to get to the point of at least defining a CHil-like object Cat and showing an example exists, demonstrating the use of Grothendieck's axiom, and deriving from Cat the "axioms" that would be used for the HSE-type approach.
- .
- Well what prevents me from building up layers is that it is a bit difficult to find natural layers. I think that in this article (categories and deductive systems) we can find p. 6 a structure that would meet your wishes but it is difficult for me to find a book where the intermediate layers are really described. In most books (in the joy of cats for instance) the structure is described in one shot. And in the journal of formalized mathematics they describe the structure in one shot as well (the way they define things is very different from the Metamath style: due to the fact the language is typed I suppose). – fl
- BTW the complex numbers were originally done as separate axioms just like HSE, then later those axioms were proved as theorems. That is certainly an ideal approach. But the difference is that there is a standard construction of CC that is representative or isomorphic to all possible constructions. We rarely need the "class of all CC's" for ordinary math; we just construct one example and call it "the" CC. We do need CHil when you want to compare different Hilbert spaces and map between them. HSE assumes there is a "the" Hilbert space for simplicity, but you can't go back, and there are many theorems involving multiple Hilbert spaces that can't be proved in HSE. I guess you might say that I look at HSE, and the Quantum Logic Explorer, as "calculators" for proving results that fit into the limited scope of their axioms, but that CHil is the "real" thing.
- .
- Finally, if you are really serious about categories, you may want to learn how to use Mizar by actually using it, not just reading about it. Learn how it does category theory and prove some variations on its theorems, using the Mizar prover, as exercises to make sure you understand them and Mizar. Anyway, that's what I would do. – norm 15 Apr 2007
We can prove that the hypothetical object described by these axioms is itself a Hilbert space. Specifically, we can prove the theorem "|- <. <. +v , .s >. , norm >. e. CHil" which isn't in set.mm yet but hopefully will be soon.
Another case is the Quantum Logic Explorer - it is an abstraction from Hilbert space theory to simplify working with one particular algebraic aspect of it. The rationale for doing this is described here.
A similar rationale can be used to explain why we introduce ax-hilex, etc. rather than just working directly with df-hl (aside from the fact that CHil was introduced only recently). A few words about this are here. In particular, any actual Hilbert space (such as the complex numbers) satisfies the axioms ax-hilex, etc. with appropriate definitions, so all the theorems derived from ax-hilex, etc. automatically apply to it under these definitions. But again, those theorems are about any abstract object that has the properties of a Hilbert space. There is nothing in the axioms telling us what H~ is, only how it behaves. – norm
Quadrupling
I don't mind if you use the old way (I only wanted to understand the difference between the formulation in the HSE and in the rest of set.mm) but I wonder why you have this quadrupling ? Do you think it will happen for all the proofs or only for the "axioms" ? And secondly I had felt the need to use lemmas in my own proofs. Perhaps that sort of lemmas can can help to factorize the proof branches that are repeated several times. – fl 26-Apr-2006
fl is referring to the increase in proof size of ncvgcl compared to ncvgclOLD that is mentioned in the Notes on Recent Proofs of 26-Apr-2007. The increase in proof size is primarily due to the fact that vafval needs a hypothesis. This affects primarily the initial theorems brought over from more general theories, but still there are going to be a lot of these kinds of theorems. I am studying several ways to improve this. Most likely, I will simply define df-va as
df-va $a |- +v = ( 1st o. 1st ) $.
intead of
df-va $a |- +v = { <. x , y >. | ( x e. NrmCVec /\
y = ( 1st ` ( 1st ` x ) ) ) } $.so the hypothesis "A e. NrmCVec" isn't needed. An alternate approach that is somewhat radical would be to define "+v" as a general-purpose class variable, and use it in place of "G". That might be confusing, though. – norm 27 Apr 2007
The terrors of existence
I have this:
E* u E. v ( v e. J /\ u = ( v i^i A ) )
I suspect it can be proved using moeq but I don't know which intermediate steps to use ? Can you help me ?
– fl 1-MAy-2007
It is false. Suppose J ={{0},{1}} and A = {0,1}. Then u can be either {0} or {1}, so it is not unique. – norm
Calculus
Hi Norm,
Suppose I have a mapping F : RR -→ RR with ( F ` x ) = x + A . I want to show that that the converse mapping ( `' F ` x ) = x - A . What is the best way to express that sort of theorem ( and the best way to prove it by the way because some attempts make me think it's not absolutely trivial :-) ) ? – fl 19-May-2007
Use f1ocnvfv. – norm 19-May-2007
looks great. Thanks. – fl
Request for comments on proposed "maps to" notation
I am considering adding a new notation to set.mm to abbreviate functions and operations. For example, it will abbreviate
{ <. x , y >. | ( x e. RR /\ y = ( x + 2 ) }to become
( x e. RR |-> ( x + 2 ) )
A similar notation is often used in textbooks, where the above function might be specified as
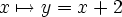
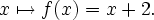
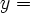 or
or 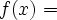 that ours omits.
that ours omits.The class syntax and definitions would be as follows:
cmapsto $a |- class ( x e. A |-> B ) $.
cmapsto2 $a |- class ( x e. A , y e. B |-> C ) $.
df-mapsto $a |- ( ( x e. A |-> B ) <->
{ <. x , y >. | ( x e. A /\ y = B ) } ) $.
df-mapsto2 $a |- ( ( x e. A , y e. B |-> C ) <->
{ <. <. x , y >. , z >. | ( ( x e. A /\ y e. B ) /\ z = C ) } ) $.Unlike new class constants (which I recommend and use for virtually all new definitions), this definition involves a new syntax form that must be carefully considered to ensure that it is unambiguous and compatible with parsers. But I think its size economy and particularly its elimination of a dummy variable may make it worthwhile.
I had also considered the even more compact "x e. A |→ B" and "x e. A , y e. B |→ C" but I am not absolutely sure it is unambiguous (I think it is - if not, I would be curious to see a counterexample) or compatible with existing Metamath parsers. However, O'Cat convinced me that adding the parentheses will be better for human readability.
Any comments? – norm 4 Aug 2007
I would like to see a plan for mappings like say, R^n |→ R, or even R^m |→ R^n (?).
I don't know how to accomplish that or vectorized operands, but it seems to me that in the long run that is desirable.
Also, for example, defining higher level Type Code objects such as Point. Right now we have grammar
class =: yada yada
| <. set , set >.
| <. set , class >.
| <. class , set >.
| <. class , class >.
| { <. set , set >. | wff }
| { <. <. set , set >. , set >. | wff }
| yada yada
Is there a was to define a Metamath syntax that allows statements that refer to operands of Type "Points", "Vector", "N space", or whatever, that are themselves defined in terms of classes?
--ocat 5 Aug 2007
There is no easy mechanism within Metamath that allows a "variable" syntax of n components - if that's what you are suggesting - without adding new syntax types beyond set, class, and wff and defining recursive structures for them. The only one I attempted a few years ago was decimal numbers, with a new syntax types called a "digit" and "digit-string", but it was awkward and required a rather complex soundness justification "outside" of Metamath, and I felt that it was incongruous with the philosophical simplicity of Metamath. In particular, there was no straightforward way to verify its definitional soundness automatically like Ghilbert will eventually do with the existing Metamath syntax structures, so the definition of a decimal number had to be treated more like a new axiom that extended ZFC set theory, than a new definition. (* see note below) Eventually, perhaps, this will be a necessary evil to get a human-like representation of numbers, and I may revive that syntax, but so far it hasn't really been necessary, since the largest number actually used for theorems and proofs is, I think, 4. There is some discussion on on this under df-2, which mentions that even in one of the deepest proofs ever produced by mankind, Wile's FLT, the largest number used is apparently 12.
- (* Note) We can still emulate decimal numbers using the existing (and Ghilbert soundness-verifiable) binary operation mechanism, with a new operation say "#" meaning "10 times the first argument plus the second", so 1234 would be "( ( ( 1 # 2 ) # 3 ) # 4 )". Even though this is verbose at the Metamath language level, a human display could suppress the #'s and parens, giving the appearance of normal numbers like 1234. The digit-string syntax I mentioned would have provided for numbers like "1 2 3 4" natively in the Metamath language itself, but at at price.
Metamath is not ideal for "applied math" with vectors of fixed lengths like 27; instead, it is meant to be able to derive the deeper and more general results (for arbitrary n) that applied math starts with. I believe Raph has a far more ambitious long-term vision for Ghilbert and expects that it will be used eventually for all of math, even formal verification that computer programs are bug-free, as the power of computers grows - who knows what computers will be like in 10, 20, or 50 years. For him, as for me, the key advantage of Metamath-like languages is the simplicity of the underlying verification engine, providing for what amounts to essentially perfect rigor and freedom from bugs.
The actual vector lengths and other "list" sizes that Metamath proofs have needed so far are mostly 1, 2, arbitrary finite n, and infinite, with nothing in between other than perhaps an occasional 3 and very rare 4. These "small numbers" extend to other structures as well; so far we have been able to do fine with just ordered pairs - not even ordered triples - and we haven't suffered much not having operations with more than 2 operands. As time goes on perhaps we will encounter a situation where it is simply impractical to go further without more "advanced" recursive syntax structures, but I don't see that for a long time, if at all, and I don't want to add them until it becomes a clear necessity. Once we do, we will leave the Edenistic garden of conceptual simplicity forever.
I have rambled too long. :) To address your specific suggestion, n-place cross products (as well as infinite ones) are normally emulated with the infinite cartesian product df-ixp, which should work fine with the maps-to syntax I am proposing. – norm 6 Aug 2007
Hi Norm,
I am looking at 3imtr4 and friends. These replace one or more variables in a formula with their equivalencies ("<->").
At a sub-Metamath standard of rigor, a person intuitively just replaces a variable or expression with another which is logically equivalent. Trigonometric identities are good examples of this sort of thing, as are high school Algebra I & II problems :-) In set.mm a person is required to put a formula into a form wherein one of these 3imtr4 sorts of theorems can be used, since obviously, set.mm cannot contain every variation of every formula and a corresponding theorem to replace individual variables in each permutation.
But at a meta-Metamath level is it true to say that as long as no $d restrictions are violated by the substitution, any one – or more than one – occurence of a variable or expression can be replaced (in the sense of formula rewriting) by its logical equivalent (<->)?
- Yes.
So if "ph" occurs twice in a formula, one occurrence of "ph" can be replaced with an equivalent expression. And an expression – or an mmj2 Work Variable – can also be replaced by an equivalent expression, assuming no $d restrictions are violated. Anywhere, anytime.
This seems to be something to which a Proof Assistant for Metamath could aspire to automating while still maintaining a logic-agnostic position. If a .mm logical system contains an "equivalent" operator then the program should be able to determine the intermediate steps to effectuate the substitution given the theorems available within the logical system.
Yes?
- I don't think it can be made completely logic-agnostic. But in the case of set.mm, there are only two possibilities: an outermost "<->" is a wff equivalence, and an outermost = is a class equivalence. In ql.mm there is only the outermost =. It could be different for other logics. So there would have to be a parameter setting for mmj2 that would tell it what connective(s) are equivalence connectives for this purpose. For construction of the final proof, we would have to build up the layers around the expression that is substituted, using anbi1i and friends, such as the buildup from step 22 to step 24 in coass. For mmj2 to recognize that these are layer-building theorems isn't impossible, but it would require a little work given only that <→ and = are the equivalence connectives. – norm 4 Apr 2008
- By "outermost" you mean root of the parse tree ( "|- A = B ") as opposed to, say, " |- ph → A = B "). Yes?
- .
- I hadn't actually thought of "=" in this way WRT to subject at hand, but what you say makes sense: there could be a parameter-controlled specification in the RunParms? (or tool equivalent) of an equivalency syntax axiom for each Type Code. And, for the RunParm? to make sense the user would be requested to double-check that the syntax axiom they are designating has the property of commutativity, which would be a way to guarantee that we are talking about standard equivalence (because we expect to be able to swap B for A and A for B if A and B are "equivalent" – and looking at this another way, "->" can be seen as a non-commutative form of equivalence for the purposes of doing these manipulations, which would have to be double checked by the Unification/Verify process.)
- .
- Philosophically, I consider "equivalence" and "equality" to be 99.99% logic agnostic because these ideas are so fundamental to everything we do in communicating. So it is really just a matter of telling the program which syntax axiom to use for which Type Code so that hardcoding can be avoided (but mmj2 sets the defaults for set.mm usage, and anyone else must override with RunParms?.)
--ocat 3-Apr-2008
Follow-up thoughts…
I was put onto an interesting document, The Use of Data-Mining for the Automatic Formation of Tactics, Hazel Duncan, doctoral thesis, 2007, University of Edinburgh.
His project uses genetic programming algorithms to select "useful" sequences of Isabelle rules from existing proofs for application to new theorems.
The results do not seem especially amazing, but I guess even a small improvement over "naive" or brute force is better than nothing. He also surveys other automated provers in use, including Omega.
(I suppose, if one were planning to extend mmj2 it would be wise to do some research before investing more man years in code (which is just a little bit intractable :-))
Slightly unrelated, a problem for people wishing to extend Metamath is the need to have backwards compatibility to/from Metamath. The unique text format and meta-text inside set.mm, for example, not only make it difficult to write an .mm updater, but exporting from Metamath triggers, potentially large chain-reactions of updates when syntax changes, $d's change, and/or statements are rearranged. This is a result of the massively inter-related nature of Metamath statements (example: generalizing 19.2 to two set variables triggered error messages in 3 existing compressed proofs which use 19.2 – caused by need to change their proof trees.)
- I assume you are aware of the Recent Label Changes at the top of set.mm. The 19.2 change is listed as " 2-Apr-08 19.2 [--same--] generalized to use 2 set variables". Basically, whenever the comment field of the label change is not empty, it means some manual work must be done to retrofit, and there is no way to avoid this manual work in general. Whenever the comment field is empty, then the update involves a simple global substitution, which can be done with a script. (I'll call these label changes "automatable" ones.) Right now this hasn't been a big problem. If the user base grows to a point where it does become a problem, then the initial solution I would propose is relatively simple. I would rename the old 19.2 to 19.2OLD and add 19.2OLD in the Recent Label Changes list. Since the 19.2 to 19.2OLD is an automatable label change, updating a user's database using set.mm is simple. However, the suffix "OLD" indicates that 19.2OLD won't be around forever - I could establish a policy of say 1 year - and eventually user must update his/her database with the new 19.2. (Right now I don't put *OLDs in the Recent Label Changes, and I don't retain *OLDs very long - they effectively serve as a to-do list for me of things to get rid of. This is what would change - the *OLDs would be for the user's benefit as well as my own.) – norm 18 May 2008
Given our recent work and discussions which show that the minimum "essential" information in a .mm file about a theorem is just the RPN sequence of the logical assertions and logical hypotheses used in the proof, I think that this might be the most robust way to exchange theorems in the Metamath family of proof verifiers – everything else is recomputed during IMPORT. (Passing along meta-content such as comments is desirable, of course, but is far simpler to arrange.)
- This would solve the problem for 19.2, but that is a rare case where the only change was generalizing it to use two variables without changing its structure. I'm not saying such a tool wouldn't be useful, but it's important to be aware of the kinds of changes that occur in practice, so that you know what to expect. It might be useful to look at the "non-automatable" changes in the Recent Label Changes list (i.e. the ones with a comment) to see the kinds of changes that typically occur in practice. For now, I think that a "low tech" approach with a disciplined change list as I described above should address much of the problem, at least until the user base grows large enough to justify a more sophisticated approach. – norm
I think what we would do is extract from .mm to an intermediate form designed for delta- comparisons (changes between .mm versions). Then automated comparisons of the intermediate file versions would generate EXPORT/IMPORT transactions – the guts of which for a theorem would be logical assertion and hypothesis labels in RPN order. An IMPORT program ought to compute everything from the proof labels, including the formula itself, distinct variable restrictions, mandatory/optional frames, and even the location of the theorem within the .mm database.
ax-10
Congratulations on finding a shorter version of ax-10.
- Thanks. :)
I am wondering how you know that ax-10 is the same as ax-10o except shorter – they look very different to me. If an automated prover had been chugging away for the last 10 years how would it have known that it hit gold?
- I didn't anticipate that the new ax-10 would have exactly this form. Basically, it occurred to me that by putting a quantifier on the first antecedent of ax-11, we had something that looked very close to ax-10o. The new ax-10 was the missing piece that I needed to complete the proof. The nice thing about it is that it has no wff variable, leaving ax-11 as the only one left with both equality and a wff variable.
Also, what is the story about the discovery? What was the motivation, the inspiration for doing the work?
- The three axioms ax-10, ax-11, and ax-12 are very different from anything that exists in textbook or literature FOL. Their purpose is to fill in the gaps necessary to achieve metalogical completeness, meaning all possible theorem schemes that the language can express are provable. This is a stronger kind of completeness than just logical completeness: the system is logically complete without ax-11, for example, since any instance of ax-11 without wff variables is provable from the others. Anyway, I am periodically tempted to look for shorter versions of these, which was successful for ax-11 and now ax-10. Past efforts have also shortened ax-9, taking out its wff variable, and eliminated ax-15 and ax-16. Axiom ax-12 is particularly stubborn, though, as well as long and ugly. My only partial success was breaking it into two slightly shorter ones, shown by ax12study. Interestingly, the two "pieces" can be written as form:
a12study.1 $e |- ( -. A. z z = y
-> ( A. z ( z = x -> z = y ) -> x = y ) ) $.
a12study.2 $e |- ( -. A. z -. z = y
-> ( A. z ( z = x -> -. z = y ) -> -. x = y ) $.- where the 2nd has the same pattern with negations added to some equalities in the 1st. I'm not sure what if anything this means, just an observation that someone might be interested in looking at.
Finally, I am wondering if you can provide an up-to-date list of theorems which should not be used in proofs. I would like this information maintained going forward in the mmj2 RunParms?.txt Run Parm:
ProofAsstUnifySearchExclude,biigb,xxxid,dummylink
which has the minimum (mmj2 searches from start to end at this time, so if the "o" version follows the correct theorem to use the "reject" version is avoided.)
- Well, I don't think you have to be overly concerned with it, since it's trivial to switch from one to the other. It is mainly so I can get a finer-grained view of what is needed for particular proofs. But the current list can be found in the metamath program as follows:
MM> search * "should not be referenced" /comment 3196 ax10 $p "...-10o . This theorem should not be referenced in any proof...." 3198 ax10o $p "...11o . This theorem should not be referenced in any proof...." 3455 ax11o $p "...11o . This theorem should not be referenced in any proof...." 3458 ax11 $p "...-11o . This theorem should not be referenced in any proof...." 9457 axsep $p "...rep . This theorem should not be referenced by any proof...." 9486 axnul $p "...rep . This theorem should not be referenced by any proof...." 9713 zfpair $p "...ioms. This theorem should not be referenced by any proof..." 9714 axpr $p "...oms. . This theorem should not be referenced by any proof...." 16482 axinf2 $p "...eg . This theorem should not be referenced in any proof..."
- – norm 18 May 2008
--ocat 17-May-2008