Hopefully, Norman Megill will wander by and answer metamath questions :)
Appendix 4: A Note on Definitions
Question
I don't really understand what Norm is saying in http://us.metamath.org/mpegif/mmset.html, Appendix 4, about soundness. I'm not really sure what soundness checking is.
Answer
I added an example to Appendix 4 that hopefully makes this clearer. --norm 5 Sep 2005
Proper Substitution
Question
How the substitution definition has been coined ? What was the (potential) intellectual process of its creator when he/she invented the definition. I think it can be helpful to grasp a definition that is not as straightforward as the usual one.
Answer
We are interested in "the wff that results when y is properly substituted for x in the wff phi," which we denote by [y/x]phi.
As opposed to "simple substitution" (like Metamath's built-in rule), which blindly replaces variables throughout an expression, "proper substitution" pays attention to their context, i.e. whether they are free or bound at a particular symbol position in the expression, and substitutes only the free occurrences, renaming bound variables when necessary to avoid clashes. For example, the proper substitution of y for x in
(x = y /\ A.x x = y /\ E.y y = x)
would be
(y = y /\ A.x x = y /\ E.q q = y),
whereas simple substitution would result in
(y = y /\ A.y y = y /\ E.y y = y).
These have quite different logical meanings. In logic books, proper substitution is typically presented as a list of mechanical wff construction rules that cover the various cases. These mechanical rules are fine for informal work, where with experience one learns to "see" the proper substutition all at once, but in a formal proof (at the extremely detailed level of Metamath) they can be tedious and distracting.
There is an alternate method for representing proper substitution that is much more compact. The idea is not to construct the substitution instance explicitly according to these rules, but instead to come up with a wff that is logically equivalent. In the end, that is all we care about anyway. I'm not sure who originated this method historically, but it is given in Quine's Set Theory and Its Logic.
The basic idea is to notice that we can prove, as a theorem scheme of standard predicate calculus, the following equivalence when x and y are distinct (http://us.metamath.org/mpegif/sb5.html):
(Note: I am being lazy by just copy/pasting from Metamath web pages; Mozilla will paste the ASCII versions of the symbols into a text editor - a very cool feature, by the way, that Internet Explorer doesn't have. Even though it does not conform to Metamath's white space requirements, I think it's reasonably readable.)
sb5 |- ([y / x]ph <-> E.x(x = y /\ ph)) Distinct variable group(s): x,y
This has the drawback of not working when x and y are the same; we the need proviso $d x y. But with a third auxilliary variable z, we can prove (as shown in Quine) (http://us.metamath.org/mpegif/sb7.html):
sb7 |- ([y / x]ph <-> E.z(z = y /\ E.x(x = z /\ ph))) Distinct variable group(s): x,z y,z ph,z
which works even when x and y are substituted with the same variable.
This still has the drawback of requiring that the third "dummy" variable z be distinct from both x and y as well as not occurring in ph. In set.mm, I wanted to see how far we can go without ever requiring variables to be distinct, i.e. before the $d statement is introduced. (The answer is that it is quite far; in fact all of mathematics can be done without the $d statement, subject to limitations discussed at http://us.metamath.org/mpegif/mmzfcnd.html.) In order to do this, I needed a definition of proper substitution that doesn't depend on the $d statement, and by playing around I found the following equivalence for proper substitution, with no restrictions at all on x, y, or ph (http://us.metamath.org/mpegif/df-sb.html):
df-sb |- ([y / x]ph <-> ((x = y -> ph) /\ E.x(x = y /\ ph)))
The trick is to have x free in the first conjunct and bound in the second, in order to make it work both when x and y are the same and when they are different. Personally, I think this is a very neat trick! However, mixing free and bound variables in this way horrifies many logicians (I will omit tales of their reactions when encountering this) and thus it will probably never find its way outside of Metamath.
Additional discussion can be found at http://us.metamath.org/mpegif/df-sb.html, which of course has the complete formal proofs of the equivalences of the various definitions above. But if you are still confused by df-sb let me know and I'll try to explain it informally.
--norm 25-Sep-05
Proper Substitution (Cont.)
Question
Thank you Norm for this answer. It is an important step for me to some deeper understanding of this definition. I'm still wondering why in sb5 the distinct variable proviso is needed. Obviously the demonstration make it mandatory but when I try to find examples, it seems to me that the proviso is not needed. For example if we decide that ph is the proposition x = x in this case y = y is equivalent to E. x ( ( x = y ) /\ x = x ) . And for this example the distinct variable proviso would not be needed. I think that I have to find a more complex example ( with quantifier I imagine) to fully understand the necessity of the proviso.
--frl 26-Sep-05
Answer
Recall sb5 (http://us.metamath.org/mpegif/sb5.html).
sb5 |- ([y / x]ph <-> E.x(x = y /\ ph)) Distinct variable group(s): x,y
Suppose we violate the proviso and substitute x for both variables. In other words, suppose we claim:
|- ([x / x]ph <-> E.x(x = x /\ ph))
Hopefully you will agree that [x / x]ph should be equivalent to ph (http://us.metamath.org/mpegif/sbid.html). So we get
|- (ph <-> E.x(x = x /\ ph))
Also, x=x is always true (http://us.metamath.org/mpegif/equid.html), so it's redundant and we can eliminate it (http://us.metamath.org/mpegif/biantrur.html).
|- (ph <-> E.x ph)
Let ph be x=z, where z is distinct from x.
|- (x=z <-> E.x x=z)
Then the rhs E.x x=z is true (http://us.metamath.org/mpegif/a9e.html), and we can detach it (http://us.metamath.org/mpegif/mpbir.html) to conclude
|- x=z
Quantifying with generalization (http://us.metamath.org/mpegif/ax-gen.html) we get
|- A.x x=z
which is false in set theory (http://us.metamath.org/mpegif/dtru.html), giving us a contradiction.
I hope I have given enough detail so that, by restating the proviso-free sb5 as an axiom, you should be able to prove this contradiction as a Metamath exercise. Indeed, by detaching the contradictory statements from the antecedents of the Duns Scotus law (http://us.metamath.org/mpegif/pm2.21.html) you can instantly prove anything from Fermat's Last Theorem (or its negation!) to the Goldbach Conjecture to impress your friends. :)
This example shows how fragile a mathematical proof can be. A tiny, barely noticeable oversight such as overlooking a proviso can lead to inconsistency. Imagine if such a subtle defect were hidden deep inside of a long, important proof! The entire proof, and any further results based on it, would collapse into a pile of dust. The elimination of such a possibility is a reason automated proof verification can be useful.
By the way, you cannot show a contradiction from the proviso-free sb5 using predicate calculus alone, which may explain why you were puzzled by it. The reason is that predicate calculus is intended to apply to any theory with a non-empty domain of discourse. In the case of a trivial theory with a single element in its domain, the proviso-free sb5 would hold; in fact it could be used as an axiom for such a theory.
--norm 26-Sep-05
hbth : no variable is (effectively) free in a theorem
Question
This tautology in metamath says that |- ph => |- ( ph → A. x ph ). That's a very strange theorem because the conclusion is the metamath way to say that x is bound in ph. And we conclude from this theorem that x is bound in x = x. Obviously outside from metamath, when we use the usual definition of a bound variable, x is ( according to me ) free in x = x. That's a point on which metamath differs from the usual construction of the bound property.
1) In the comment of hbth Norman says no variable is (effectively) free in a theorem. I wonder why he added "effectively". Does it refer to the curious property described above ? 2) Are there other cases than the one cited above where the metamath definition really differs from the usual concept of binding ?
Answer
Norm answers -
1) The word "effectively" was explained in an older version of the Metamath Proof Explorer Home Page http://de2.metamath.org/mpegif/mmset.html#traditional, which says
- Metamath's axiom system has no built-in notion of free and bound variables. Instead, we use the hypothesis (ph → A.x ph) when we want to say (as we do in stdpc5) that "x is effectively not free in ph." We say "effectively" because any wff that is also a theorem, such as x = x, will satisfy the hypothesis even though x may technically be free in it.
I took this out in a rewrite of that section to reduce the amount of text. Perhaps I should put it back. The current version http://us.metamath.org/mpegif/mmset.html#traditional says
- Metamath does not have the traditional system's notions of "(does) not (occur) free in" and "free for" built-in. However, we can emulate these notions (in either system) with conventions that are based on a formula's logical properties (rather than its structure, as is the case with the traditional axioms). To say that "x is (effectively) not free in ph," we can use the hypothesis ph → A.x ph. This hypothesis holds in all cases where x does not occur free in ph in the traditional system (and in a few other cases as well).
This is not to say that Metamath can't emulate the traditional technical definition, as you are doing in nat.mm, but only that for my axiom system I chose not to, in order to keep the primitive starting concepts (as opposed to derived high-level concepts) as simple as possible.
By the way, although (ph → A.x ph) works as a hypothesis, it will not always work as an antecedent in a formula, since x may be (effectively) free in it. Instead, A. x (ph → A.x ph) will always work both as a hypothesis and as an antecedent in order to denote "(effectively) not free". The first quantifier is usually removed for simplicity in hypotheses since ax-gen can put it back.
2) Another curious example is hbae, which shows that y is (effectively) not free in A. x x = y. Neither A. x x = y nor its negation is a theorem of predicate calculus.
--norm 9 Oct 2005
A third curious example is obtained by combining hbs1 and df-sb:
( ( ( x = y -> ph ) /\ E. x ( x = y /\ ph ) )
-> A. x ( ( x = y -> ph ) /\ E. x ( x = y /\ ph ) ) )when x and y are distinct. This, of course, says that x is effectively not free in [ y / x ] ph when x and y are distinct. But notice that in ( x = y → ph ), not only is x free in x = y, it may also be free in ph! So this is an example where "effectively not free" and "not free" in the traditional sense are quite different. This property, by the way, seems to be intimately tied to ax-11 from which it is derived. In particular, when x and y are distinct, the theorem ax11v gives us
( x = y -> ( ph -> A. x ( x = y -> ph ) ) )
which somewhat counterintuitively quantifies a variable in the consequent that is free in the antecedents.
--norm 17-Dec-2005
Restatement of $d as Metamath formula possible?
Question
Heretofore I have viewed the $d statement as outside of the Metamath grammar, as if it is not actually part of the user-defined language but is somehow outside of it. In a sense, that is true because it only comes into play inside proofs, but now the question of converting arbitrary .mm file(s) to/from other "mathelogical" systems is of more widespread interest, and a mechanical method of mapping $d semantics is desired (which may not be easy to specify?).
Is it possible to convert each $d statement to one or more $e logical hypotheses that exactly capture the meaning of the original $d restriction?
--ocat
Answer
Although I'm not sure what you mean by "exactly," a $d can be converted to a $e with a "distinctor" (see below), with an important catch. The problem is that when the $d is no longer needed, its $e emulation can't be made to vanish, unlike the $d.
Let me describe the situation in more detail. $d x y can be emulated with the hypothesis or antecedent -. A. x x = y, called (by me) a "distinctor". If x and y are distinct, it is true. If they are the same, it is false. Theorem alequcom shows that the order of x and y doesn't matter; -. A. x x = y and -. A. y y = x are equivalent. By virtue of hbnae, a distinctor (effectively) has no free variables, so 19.21ai can be used to emulate generalization when you have the conjunction of a bunch of distinctors hanging around as an antecedent.
The "$d-free fragment" of predicate calculus through ax-15, omitting ax-16, is a complete system of logic, with the important exception that as many distinctors will accumulate as there are dummy variables required by the proof (in addition to any distinctors that are required by the theorem itself). Often distinctors can be minimized or eliminated with tricks like the Distinctor Reduction Theorem (9.4) of my paper.
However, in the end we will ultimately be defeated by a deep theorem of Andréka, which shows that there is no upper bound on the number of dummy variables that may be needed in an arbitrary proof, no matter what tricks you use or how clever you are. This theorem is the real reason we need $d's or some equivalent method to get rid of dummy variables. It means that it is theoretically impossible to avoid the eventual accumulation of distinctors if we don't have such a method.
(So far I haven't found an actual theorem that has a redundant distinctor that can't be eliminated, as should exist per Andréka's theorem, but that is probably because I haven't played around enough in $d-free world. The only thing I've done in that world is to prove the 200 $d-free predicate calculus theorems in set.mm, to obtain the completeness results for the $d-free system for my paper, and to prove $d-free versions of the ZFC axioms. None ever showed up that I couldn't eliminate with various tricks. Who knows, an actual uneliminable redundant distinctor may be one of those elusive things like sentences of arithmetic that are true but not provable, that sort of thing. Or it may be more common. But you can be sure that it's out there, somewhere! Andréka's theorem says so!)
If you use a distinctor in a $e instead of an antecedent, there is another problem (in set.mm, although nat.mm could overcome this). You can't convert it back to an antecedent with the weak deduction theorem because it is never true in predicate calculus. This prevents using tricks such as Distinctor Reduction Theorem. So they will linger forever as $e's in a proof, even when it is otherwise theoretically possible to eliminate them. Eventually they could be eliminated with dtru, although that requires introducing the $d you want to avoid. Alternately, you could have an artificial (but sound) rule that discards a distinctor in a $e when one of its variables is not in the theorem or its non-distinctor $e's.
On the other hand, if we are willing to tolerate the accumulation of distinctors, perhaps hiding them for a human display of the theorem, it is possible to do all of set theory without the $d statement! This is discussed at ZFC Axioms Without Distinct Variable Conditions. I think that is remarkable.
So far, I have talked about replacing 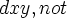 d x ph (which arises from the very useful, although theoretically redundant, ax-17). The $d x ph can easily be emulated with the (weaker) hypothesis $e |- ( ph → A. x ph ), or alternately by replacing ph with A. x ph throughout the theorem in order to "protect" it from x. Note that the hypothesis $e |- ( ph → A. x ph ) is actually just a restatement of ax-17 without its $d requirement.
d x ph (which arises from the very useful, although theoretically redundant, ax-17). The $d x ph can easily be emulated with the (weaker) hypothesis $e |- ( ph → A. x ph ), or alternately by replacing ph with A. x ph throughout the theorem in order to "protect" it from x. Note that the hypothesis $e |- ( ph → A. x ph ) is actually just a restatement of ax-17 without its $d requirement.
--norm 15 Oct 2005
Thanks!
I feared as much – and a mechanical conversion from 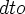 e would involve reworking the proofs.
e would involve reworking the proofs.
http://www.gutenberg.org/dirs/etext91/lglass19.zip
The Queen propped her up against a tree, and said kindly,
'You may rest a little now.' Alice looked round her in great surprise. 'Why, I do believe
we've been under this tree the whole time! Everything's just
as it was!''Of course it is,' said the Queen, 'what would you have it?'
'Well, in OUR country,' said Alice, still panting a little,
'you'd generally get to somewhere else--if you ran very fast
for a long time, as we've been doing.' 'A slow sort of country!' said the Queen. 'Now, HERE, you see,
it takes all the running YOU can do, to keep in the same place.
If you want to get somewhere else, you must run at least twice as
fast as that!'--ocat 15-Oct-2005
Superfluous optional $d statements?
Question (emailed to me)
There's something I don't understand about $d statements. Take for example ddeeq1 from set.mm:
${
$d w z x $. $d w y $.
$( Quantifier introduction when one pair of variables is distinct. $)
ddeeq1 $p |- ( -. A. x x = y -> ( y = z -> A. x y = z ) ) $=
( vw weq ax-17 a8b ddelim ) DCEZBCEABDIAFDBCGH $.
$( [2-Jan-02] $)
$}Here there are three optional $d restrictions (w is disjoint with x, y, and z) and one mandatory one (x and z are disjoint).
But from the reader's point of view, the optional restrictions are really superfluous. They're just an artifact of the way the proof is structured. So these three restrictions are really part of the proof, not of the assertion. Another way to see this: If this were an axiom, then it would suffice to have $d z y $.
Why is it necessary to state them explicitly? How is it possible to prove a wrong theorem when such optional restrictions are left out? Or perhaps that isn't possible, but this is just to help the verify algorithm?
Answer
- But from the reader's point of view, the optional restrictions are really superfluous.
For most readers, yes. You may have noticed they are suppressed in the web page versions of the proofs for this reason, because including them can make the "distinct variable groups" cluttered and confusing.
- They're just an artifact of the way the proof is structured. So these three restrictions are really part of the proof, not of the assertion. Another way to see this: If this were an axiom, then it would suffice to have $d z y $.
Correct.
- Why is it necessary to state them explicitly?
Theoretically it is not necessary, and we could just assume that all dummy variables are distinct from all other variables.
But there can be a minor benefit for the reader. If the $d's for dummy variables were hidden, the reader would have no way of telling by inspection what adjustments could be made to the proof. For example, the proof might have dummy variables v and w that must be distinct from the the theorems' variables but not from each other. Therefore we could change both of them to w to reduce the number of hypotheses and possibly shorten compressed proofs by increasing the likelihood of common subexpressions. Or we could leave it alone if we prefer the better readibility of separate v and w, that may serve two different purposes in the proof.
There are also proofs (e.g. in propositional calculus) where dummy variables are used in the proof for clarity. For example, look at step 2 of http://us.metamath.org/mpegif/biigb.html. Since there is no $d in set.mm, the variables χ (chi) and θ (theta) can be changed to whatever you want, either for best readability or for minimum number of hypotheses. (A person reading the web page wouldn't know this, only someone reading set.mm.)
- How is it possible to prove a wrong theorem when such optional restrictions are left out?
If you are talking about a hypothetical program that automatically assumes $d for dummy variables, then it shouldn't be possible. Everything should be fine.
- Or perhaps that isn't possible, but this is just to help the verify algorithm?
It can make proof verification a little easier, but that is a relatively minor issue. I think it might also make the spec slightly more straightforward, by not having to describe implicit $d's for dummy variables, although it is arguably a toss-up between that and having to describe "optional $d restrictions".
I might also mention that in theory all $d's except those accompanying axioms are superfluous, since the proof verifier could use the violations to reconstruct what they should be. Of course it would be compute-intensive to determine them this way, since proofs could not be verified independently from each other.
The bottom line is, if you are designing a new language based on Metamath, whether you require dummy variables to have distinct variable requirements is largely a matter of taste. Ideally they should be put back automatically when converting to back to Metamath .mm format, but that can also be done with a simple script based on what the failure are (see the next question).
norm 16-Oct-05
Metamath tips and techniques: creating $d statements
Question
What is an easier way to figure out what $d requirements must accompany a complex theorem?
Answer
Sometimes theorems can have rather complex distinct variable requirements. Rather than spend time manually figuring them out, I will often just prove the theorem without them and then use the metamath program's "verify proof" error checking to tell me what they should be. For example, if you remove the $d's from cplem2 in set.mm, "verify proof cplem2" will produce error messages starting with:
?Error on line 39915 of file "set.mm" at statement 13860, label
"cplem2", type "$p":
eqid cplem1 cB c0 wceq wn cB vy cv cin c0 wceq wn wi vx cA wral cB
^^^^^^
There is a disjoint variable ($d) violation at proof step 122.
Assertion "cplem1" requires that variables "x" and "y" be disjoint.
But "x" was substituted with "x" and "y" was substituted with "z".
Variables "x" and "z" do not have a disjoint variable requirement in
the assertion being proved, "cplem2".There are 546 lines of such error messages, with duplicate violations (due to violating more than one referenced theorem) that make them tedious to wade through. However, if you have Linux or Cygwin on Windows, you can type
$ ./metamath 'r set.mm' 'v p cplem2' q | grep 'have' | sort | uniq
yielding
Variables "A" and "w" do not have a disjoint variable requirement in Variables "A" and "x" do not have a disjoint variable requirement in Variables "A" and "y" do not have a disjoint variable requirement in Variables "A" and "z" do not have a disjoint variable requirement in Variables "B" and "w" do not have a disjoint variable requirement in Variables "B" and "y" do not have a disjoint variable requirement in Variables "B" and "z" do not have a disjoint variable requirement in Variables "w" and "x" do not have a disjoint variable requirement in Variables "w" and "y" do not have a disjoint variable requirement in Variables "w" and "z" do not have a disjoint variable requirement in Variables "x" and "y" do not have a disjoint variable requirement in Variables "x" and "z" do not have a disjoint variable requirement in Variables "y" and "z" do not have a disjoint variable requirement in
which can easily be translated manually to the $d statements
$d A w x y z $. $d B w y z $.
Of course, in an ideal world all of this would be automated inside the Proof Assistant. But that is a topic for another day…
--norm 6-Oct-05
If you don't have Linux or Cygwin, you can emulate the above $d filtering command
$ ./metamath 'r set.mm' 'v p cplem2' q | grep 'have' | sort | uniq
as follows, using the "tools" facility of the metamath program. Type this sequence of commands into the metamath program, or put them into a script which can be run with metamath's "submit" command.
read set.mm open log 1.tmp verify proof cplem2 close log tools match 1.tmp 'have' '' unduplicate 1.tmp type 1.tmp 100 exit
--norm 10-Oct-05
Guidelines for adding and removing $d's in proofs in set.mm
Question
How do I convert $d's (distinct variable requirements) to $d-free hypotheses, and vice-versa, when creating proofs in set.mm? How do I get rid of distinctors (antecedent of the form -. A.x x=y) that are theoretically unnecessary?
Answer
Below I list the principle guidelines for dealing with $d's.All of these are implicitly part of the proof of the metalogical completeness theorem in my paper, but I think the practical examples below will be more helpful than some abstract theory.
- 1. Converting $d x y to distinctor - use dvelim. (It is more of an art than a science at this point, since I don't use it very often, but go by the examples of its usage.)
- 2. Converting distinctor to $d x y - use mainly ax-16; see e.g. ax17eq and other uses of ax-16. If you have set theory, it's trivial; use dtru. But it's not hard without dtru either, so don't add set theory just to get dtru. :)
- 3. Converting $d x ph to (ph → A.x ph) hypothesis - usually done via a dummy variable and cbval, cbvex; see e.g. df-eu -> euf.
- I'd like to say to the pure and young metamathician that in fact the $d statement doesn't disappear; it is only transfered to a dummy variable. I want to say that because I wondered where the $d statement had gone for a while since the $d statement about dummy variables are not mentioned on the html pages. frl 11-Nov-2005
- 4. Converting (ph → A.x ph) hypothesis to $d x ph: trivial; use ax-17
- 5. Eliminating unnecessary distinctors - use pm2.61i together with dr* theorems e.g. dral1; see the proof of sb9i for a good example of this.
--norm 25-Oct-2005
Logical vs. metalogical completeness
Question
What is "metalogical completeness"?
Answer
Standard first-order logic or predicate calculus in textbooks has an important property called "logical completeness," which means that it can prove all logical statements that are universally true in a non-empty domain. This was first proved by Gödel, and I have heard it said that he was more pleased that proof than he was with his incompleteness proofs (although the latter of course had a much more profound impact).
In the context of Metamath, you will also see the term "metalogical completeness" brought up from time to time. I will try to explain what this term means with a simple example.
Consider the set.mm theorem a9e, E. x x = y with no proviso (no $d) on x and y.
In textbook predicate calculus with equality, this theorem cannot be proved directly from the axioms. In fact, is not even a theorem but rather a theorem scheme or "metatheorem," where x and y range over the variables of the logic. It is important to keep in mind that x and y are not actual variables of the logic, but are metavariables ranging over them. If we call the variables of the actual logic x1, x2, x3,… (often shown in a different typeface), then we can think of this metatheorem as generating two kinds of infinite sets of actual theorems. The first set is all theorems of this form where x and y are distinct: E. x1 x1 = x2, E. x3 x3 = x2, E. x2 x2 = x1, etc. The second set is all theorems of this form where x and y are the same: E. x1 x1 = x1, E. x2 x2 = x2, etc. Note that in the actual theorems of the logic, all variables are distinct by definition; x1 and x2 are the names of two distinguished objects in an infinite set of actual variables that we are assumed to have available to work with.
In textbook predicate calculus, we would prove the theorem scheme E. x x = y as follows. First, we would prove the theorem scheme x = x (for any variable x1, x2,…), then using the theorem scheme phi → E. x phi we would conclude the theorem scheme E. x x = x.
Next, we start with the scheme y = y, then use specialization to conclude the scheme E. x x = y, where the bound variable x is a variable that is not free in the starting expression y = y. Thus x and y must be distinct variables, i.e if we instantiate x to be the variable x2, then we must select some different variable such as x1 or x3 for y.
Now we must take a metalogical leap and combine these two cases. There is no explicit rule of predicate calculus that allows us to do this - it is more like you use common sense, or high-level mathematical reasoning (i.e. metamathematics), to combine them. After combining them, we conclude the proviso-free theorem scheme (metatheorem) E. x x = y.
When I say "common sense" above, what I really mean is the informal set theory that is implicitly used for metamathematical reasoning. This set theory is applied to the syntactical model of predicate calculus, which consists of an infinite set of variables to choose from, infinite sets of axioms generated by templates called axiom schemes (which typically begin, "all wffs of the form…"), etc. In effect we are forming the union of two infinite sets of theorems, then claiming (with an implicit or explicit proof) that the template E. x x = y, with no provisos, generates the same set of theorems as that union.
Thus, to derive a theorem scheme of predicate calculus from other theorem schemes, we are not directly using predicate calculus at all, in the sense of a formal predicate calculus proof. Instead, we are really using set theory to manipulate the schemes at a much higher level. In fact if we used only the actual formal predicate calculus we would be severely constrained in the kinds of general things we could say. We could not even prove such a simple thing as "A. x phi → phi for all wffs phi" because that is not a theorem of predicate calculus, but a theorem scheme.
Therefore, textbooks rarely show actual formal predicate calculus proofs except as simple examples to illustrate what they are talking about. The metamathematics is what lies at the heart of being able to do useful things (i.e. prove general schemes) in predicate calculus, and that implicitly involves informal set theory, which in turn requires a certain level of mathematical maturity to grasp. This may be why, even though one would think it should be the starting point for math, predicate calculus is usually taught at an upperclass undergraduate level. It also explains why the predicate calculus in textbooks can be awkward to implement (as described in informal language by textbooks) with a computer program. The problem is even more difficult if you want to have the computer program work with theorem schemes and not just specific formal proofs, because the program would have to "understand" set theory, at least on some level, in order to prove schemes like E. x x = y with no proviso.
In set.mm, on the other hand, we can derive the scheme E. x x = y directly from its axioms. There is no set theory involved in the derivation, just a mechanical substitution rule. It effectively does the metamathematics directly, without set theory. (That's why I called it "Metamath".)
In order to achieve this, we restrict the allowable kinds of metatheorems to be of the form that you see in set.mm's axioms. We formally implement provisos with the $d statement. And we state the axioms in a specific way that allows all possible metatheorems (of this restricted form) to be proved directly from the axioms - this is what I call metalogical completeness - with no set theory or other metamathematical notions at all, other than what's involved in its simple substitution rule. The restricted metalogic that set.mm uses is called simple metalogic. All of this is more precisely described and proved in my "Finitely Axiomatized…" paper. More discussion can be found at http://us.metamath.org/mpegif/mmset.html#axiomnote.
Axiom ax-17 is an example of an axiom that is not needed for logical completeness but is required for metalogical completeness. Also, it can be shown that ax-11 is not needed for logical completeness, but it is unknown whether it is needed for metalogical completeness - a problem that has been open since its publication in 1995.
--norm 22-Oct-2005
ZF vs. NBG set theory in set.mm
Question Why does set.mm use ZF (Zermelo-Fraenkel) set theory and not NBG (von-Neumann-Bernais-Gödel) set theory?
Answer
(Several people have asked this over the years. The following is an excerpt from an email I wrote.)
I think the fact that E. x = V doesn't hold in ZF and A. x x e. U. V (see Quine for why "union V" and not just "V") does (the opposite of NBG) is something of a red herring. It makes people (several so far) think that the only reason we need virtual class variables is because ZF can't directly handle proper classes, and therefore they wonder why I didn't use NBG to make things simpler.
If I were to do NBG instead of ZF, I think I would keep the set variable / class variable dichotomy exactly the same, including the 'cv' set variable to class variable converter. Off-hand I can't think of any definition or syntax construction that would be different. To make it less misleading I would rename the tokens 'set' and 'class' to something else, perhaps 'class' and 'vclass', or even the more generic 'var' and 'term' that could apply to both ZF and NBG, but that is a human nicety and not technically necessary.
My use of class variables follows Quine's Set Theory and Its Logic very closely (who calls them "virtual classes"), and, as in Quine, does not really commit to a specific set theory. Quine, for example, is completely agnostic as to the set theory used, and the exact same virtual class theory applies to both NBG and ZF as well as his own NF set theory.
In NBG, of course, quantified variables range over all classes, and the axioms and theorems would be different. I initially considered NBG, and the main reason I rejected it was because many standard (practical) theorems would have to be quantified with "A. x e. U. V" instead of "A. x", which I thought would be a nuisance. In retrospect, as you can see from the numerous theorems involving unrestricted class variables, this probably wouldn't be a major nuisance, and all of these theorems would remain exactly the same. I'm still happy with the ZF choice, though. For one thing it's more popular in the literature. Another reason is that it would be relatively straightforward to convert from ZF to NBG, with almost all proofs beyond the axiom-related stuff essentially the same, whereas the reverse might be difficult (if quantified class tricks were used to shorten proofs - in ZF you sometimes have to jump through hoops since you don't have this available) to impossible (some theorems involving proper class existence could not be converted). In this sense ZF provides a kind of "lowest common denominator".
It is easy to state the NBG axioms in Metamath - it is finitely axiomatized, with 7 class existence axioms in place of the Replacement scheme of ZF. And in principle, this is all we need. However, these can be awkward to work with, and they also cannot directly be used to prove more general theorem schemes (metatheorems with wff variables) in Metamath. Most texts will use these individual axioms to prove a metatheorem, called the Class Existence Theorem, that applies to wffs with a property called "predicative". (In versions of NBG, this is an axiom scheme rather than a metatheorem, used in place of the 7 individual class existence axioms.) This property might be somewhat awkward to express in Metamath, and I haven't thought about the best way to do it. There might be weaker-than-Class-Existence but unrestricted theorem schemes that could be borrowed from ZF for practical work, but I'm not sure.
--norm 2-Nov-05
Finitely axiomatized
Question
By the way let's speak about this property. The `finitely axiomatized' property is what you discuss in your article in Notre Dame journal of logic. This article is hard for me to understand. According to me its aim is to describe a logic system that could be checked by a computer program. In fact this article is the theoretical base of the metamath program. One of the condition for checking proofs with a program is that the axioms are in a finite number (because computers are finite device). However in traditional logic books the axioms are in infinite number. Therefore it's impossible to use these descriptions to realize a computer-aided checking. And then you had to describe a system with a finite number of axioms before realizing metamath.
But I have a question. Having a finite number of axioms seems very natural to human beings. For example when Margaris describes his system, he explains what a scheme is, then he says that there is an infinite number of axioms and eventually he explains he will make the proof with the scheme ( considered as a class of axioms ). In fact that's what everybody does when he makes a proof. So why is the description of infinitely axiomated logic so frequent when in fact it is possible to describe finitely axiomatized logic and when the genuine way to do logic seems to use finitely axiomatized logic.
--frl 9-Nov-2005
Answer
Just as "logical completeness" is a different concept from "metalogical completeness," "finitely axiomatized" in the Metamath sense has a different meaning than "finitely axiomatized" in the traditional sense.
In standard logic texts, a first-order theory is defined as finitely axiomatized if it involves a finite number of axioms (no axiom schemes) added to first-order logic. ZF is not finitely axiomatized because it requires a scheme for the axiom of Replacement. NBG is finitely axiomatized because it requires no schemes.
In both the ZF and NBG cases, however, the traditional predicate calculus underneath is not finitely axiomatized - it requires schemes. This means that if you start with a blank slate, and want to start writing down all possible proofs, under traditional predicate calculus you are faced with an infinite number of choices for the very first proof step.
In my paper (PDF file), what I call "finite axiomatization" means that at any point in a proof, there are only finitely many choices available for the next step of the proof. This is achieved by treating wff metavariables as individual variables, using a carefully devised system of axioms that is "metalogically complete." In addition, we replace the rule of modus ponens with a unification-based equivalent rule called "condensed detachment" (invented by logician Carew Meredith in the 1950s) and the rule of generalization with an analogous rule I called "condensed generalization". With this type of system, not only does predicate calculus becomes finitely axiomatized, but so does ZF set theory (as well as NBG, which already is anyway). Condensed detachment does the following: given any two schemes as its inputs, its output is the most general scheme that can result from modus ponens applied to the inputs (assuming modus ponens can be applied; otherwise the result is undefined, and that application of condensed detachment would not be a legal proof step).
The system S1 presented in my paper is finitely axiomatized. The Metamath Solitaire applet is internally an implementation of system S1 (actually a mild extension incorporating distinct variables), although to the user the results are displayed in the notation of "regular" Metamath (system S3' in the paper). The finite axiomatization means that there are only finitely many choices for the next step in any proof. To create the proof, the user successively selects from the possible choices displayed in a dynamic drop-down list. It would be impossible to make a Metamath Solitaire for the traditional axiomatization of predicate calculus, because the drop-down list would be infinitely long.
The fact that all possible proofs can be simply enumerated in system S1 means it is easy to write a computer program to exaustively search for shortest proofs (although the exponential search space blows up at around 20 steps, and beyond that heuristic techniques are needed). Early on I did this for propositional calculus for fun, and later it was done in a much more sophisticated way by Greg Bush. The results can be seen on the "shortest known proofs" page for the propositional calculus theorems in Principia Mathematica.
Now, the fact that traditional predicate calculus is not finitely axiomatized doesn't mean that computers can't "do" math with it, of course. There are algorithms, such as Robinson's resolution, that, given a specific theorem of predicate calculus (not a theorem scheme), will attempt to find a proof. This proof can, in principle, be translated back into a sequence of axiom and rule references to instances of the traditional schemes of the Hilbert-style formulation.
Resolution-type theorem provers have, in effect, the schemes of predicate calculus embodied in their algorithms. However, beyond that, they cannot deal with schemes - i.e. schemes outside of the implicit schemes their algorithms embody. So, if they are to be used to prove theorems in a first-order theory added to predicate calculus, that theory must contain a finite number of axioms.
In particular, resolution-type theorem provers cannot, in general, prove theorems of ZF set theory. On the other hand, they can work with NBG set theory by using its finitely axiomatized version. This is why set theory work with the Otter theorem prover has focused on NBG.
There is a twist to all of this: a resolution-type theorem prover can encode the finitely axiomatized Metamath-type system S1, along with any first-order extension such as ZF set theory. We define the predicate "is provable", then give the resolution prover the denial of the sentence "theorem xxx is provable in system S1". The prover will then go off and try to prove us wrong by refuting this denial - and when it succeeds, its refutation will encode a Metamath proof! So, in this very indirect way, resolution-type theorem provers can do ZF set theory! The problem is that there is eventually an exponential blow-up of possibilities it must explore to find a refutation, and practically speaking this technique will only work for theorems that have short proofs (although hints - theorems already proved - could be given to guide it along). I played around with this with the Otter theorem prover in the early 90's on a 40MHz Macintosh IIfx with 8MB memory, showing that this works in principle - it found Metamath proofs, and even found a clever, shorter proof for the theorem scheme "A. x P → A. x A. x P" than the one I found by hand (this was the D4GD4G5 proof in the Appendix of my paper) - but it ran out of steam at about ten proof steps or maybe less, as I vaguely recall.
--norm 9-Nov-2005
Conjecture
|- ( [ x / y ] y = z <→ x = z ) provided that 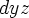 .
.
I can't find this proof in metamath. Is it wrong, is it useless ?
--frl 3-Dec-2005
It's correct. Here's a proof in Ghilbert syntax:
import (SET_MM_AX zfc/set_mm_ax () "") import (SET_MM zfc/set_mm (SET_MM_AX) "")
var (set x y z w)
thm (frl051203lem ((x y) (y z)) ()
(<-> ([/] (cv x) y (= (cv y) (cv z))) (= (cv x) (cv z)))
(
x y equsb2
x y z equequ1
x y sbimi
ax-mp
x y (= (cv x) (cv z)) (= (cv y) (cv z)) sbbi mpbi
(= (cv x) (cv z)) y ax-17 x sbf
bitr3
)) thm (frl051203 ((y z)) ()
(<-> ([/] (cv x) y (= (cv y) (cv z))) (= (cv x) (cv z)))
(
(= (cv y) (cv z)) w ax-17 x y sbco2
w y z frl051203lem
x w bisb
x w z frl051203lem
bitr
bitr3
))The lemma proves the theorem with the additional dv constraint x,y, and the main theorem gets rid of that dv constraint by introducing a new variable (w), and making that take the place of y with respect to the constraint.
As to whether it's useful, that mostly depends on whether you've got other theorems that make use of it :)
– raph 3-Dec-2005
Thank you for this beautiful proof Raph. Concerning the fact something is useful or not I often notice that what I consider mandatory is viewed as absolutely optional by Norm :) I succeeded in repeating frl051203lem but (for me) the order of the steps is not yet as clear for frl051203.
– frl 4-Dec-2005
I added Raph's proofs to set.mm. The proofs above are in equsb3lem and equsb3.
Another example of this technique is shown by sbccomg, which takes the otherwise identical sbccomglem and eliminates 4 of its 7 distinct variable pairs. In this case, the separate lemma reduces the database size significantly, since it is referenced four times in the main theorem.
By the way in the past couple of weeks I have introduced proper substitution into class variables into set.mm: df-csb. By clicking on "related theorems" you can see a bunch of theorems for it.
Also in the past couple of weeks, I have renamed a large number of theorems with "bi" in their names, e.g. bisb (which is used above) became sbbii, to be consistent with the "eq" series such as dmeq, dmeqi, dmeqd. I have been doing this over time, and I hope with this last change I have finally completed it. The changes are all documented at the beginning of set.mm
– norm 4-Dec-2005
Axiom of variable substitution: ax-11
Question
According to its name, this axiom is connected to the [ x / y ] operator. But what connexion exactly ? Could we reformulate this axiom using the substitution operator ?
– frl 13-Dec-2005
Answer
Recall ax-11:
( -. A. x x = y -> ( x = y -> ( ph -> A. x ( x = y -> ph ) ) ) )
Theorem sb6 shows that the wff "A. x ( x = y → ph )" is equivalent to "[ y / x ] ph" when x and y are distinct, i.e. when "-. A. x x = y". This is the connection to substitution.
On the other hand, if we blindly replace "A. x ( x = y → ph )" with "[ y / x ] ph" in ax-11, the "essence" of the axiom vanishes, and we merely get a weakening of sbequ1:
( x = y -> ( ph -> [ y / x ] ph ) )
which is derivable without invoking ax-11. So this would not give you the reformulation you seek.
Still, it should be possible to state an axiom containing the substitution operator that could replace ax-11, but I'm not sure what form it would take. It might be interesting to try to work that out. A possible candidate is dfsb2, since I wasn't able to derive it without invoking ax-11, but that is just a guess. Theorem sb4 is another promising candidate.
Overall, ax-11 is a rather mysterious and subtle axiom. It is not needed for logical completeness (which means that any theorem without wff variables can be proved without ax-11, as is shown in my "Finitely Axiomatized…" paper). But so far no one has proved or disproved that it is needed for metalogical completeness. Off and on I have made unsuccessful attempts to prove it from the others. The furthest I got, after considerable effort, was to prove the $d elimination theorem without using ax-11: dvelimf2. This result was something of a surprise to me and may be useful for further work on the problem.
--norm 15-Dec-05
Thank you Norm for this clearing up. I better understand this axiom and its mystery.
--frl 16-Dec-05
BIG NEWS!! Juha Arpiainen has proved the independence of axiom ax-11. See the Metamath Most Recent Proofs page for the details and very clever proof of this 11-year-old open problem.
--norm 21-Jan-2006
Guys your are really, very, very good !
--frl 21-Jan-06
$d statement, distinctor and ax-16
Question
For a while I had thought that the `$d statement is absolutely unnecessary in principle' (I'm auto-quoting myself from a mail to Norm that he was kind enough to quote in a page of the metamath site). But it seems to me now that it is more difficult than that.
Individual variables are variables that can be replaced by other individual variables and by nothing else. So `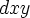 .' means `x' and `y' can't be replaced by the same variable.
.' means `x' and `y' can't be replaced by the same variable.
Norman Megill calls `-. A. x = y' a distinctor because it means that x and y have to be distinct.
ax-16 says that ` ( A. x x = y → ( ph → A. x ph ) )' provided that x and y are distinct (`$d x y').
If a distinctor and a $d statement were synonyms, we could replace the `$d' statement by a distinctor in ax-16. In this case we would have:
ax-16.1 $e -. A. x = y $. ax-16 ( A. x x = y -> ( ph -> A. x ph ) )
But obviously Norm didn't do that, and in a certain way he couldn't do that, but for me it is not yet clear why.
– frl 4-Jan-2006
Answer
In general, $d x y can be replaced with an antecedent consisting of the "distinctor" -. A. x x = y, and vice-versa. With various theorem-proving techniques summarized under the heading "Guidelines for adding and removing $d's in proofs in set.mm" above, the distinctor version of a theorem can be converted to the $d version and vice-versa.
If you replace "$d x y" with the hypothesis "-. A. x x = y" (as you did in your ax-16 example), this is also a sound thing to do; your modification of ax-16 is still a theorem. But I would conjecture that in general this weakens a theorem too much to recover its $d version with predicate calculus only (short of reproving the $d version from scratch). In particular, the Weak Deduction Theorem cannot be applied, since there is no substitution instance that makes the hypothesis true under predicate calculus. However, you can still recover the $d version in set theory, using the theorem dtru to eliminate the hypothesis.
But even replacing the $d in ax-16 with the antecedent -. A. x x = y gives us ( -. A. x x = y → ( A. x x = y → ( ph → A. x ph ) ) ) which is true by propositional calculus. So this is a sound thing to do. But it would be kind of pointless, since it "cancels" the strength of ax-16, whose purpose is to specify the property of the $d in the first place.
Finally, if we omit ax-16 entirely, using distinctor antecedents to serve the same purpose, then according to Andréka's theorem mentioned above there will be some theorems that will not be provable without redundant distinctors. For example, instead of being able to prove ( x = y → y = x ), we might only be able to prove ( -. A. z z = x → ( x = y → y = x ) ). (This is not a real example, since we can prove the first one. I've been unable to find a real example, but Andréka's theorem says they exist.)
--norm 6-Jan-2006
From my pseudo-example of Andréka's theorem, ( -. A. z z = x → ( x = y → y = x ) ), I can now see how to recover ( x = y → y = x ) without proving it directly: we substitute y for z and also prove separately ( A. y y = x → ( x = y → y = x ) ), then apply pm2.61i. I think this technique would apply to any theorem of the form ( -. A. z z = x → <wff> ) where z is a variable not in <wff>: we substitute a variable y in <wff> for z and use ax-10 in particular to help us obtain the ( A. y y = x → <wff> ) version. This is essentially the Distinctor Reduction Theorem in my Finitely Axiomatized… paper.
Therefore, I would conjecture that any example of Andréka's theorem must have at least two distinctor antecedents: ( -. A. z z = x → ( -. A. z z = y → <wff> ) ), where <wff> has at least two variables x and y and where z is a variable not in <wff>.
In case you are wondering, the distinctor antecedents with z would arise from a dummy variable z that would occur in the $d version of the proof of <wff>. Andréka's theorem says that some theorems are impossible to prove without invoking such dummy variables, and moreover there is no upper bound on how many such dummy variables might be needed. In a system of predicate calculus that omits ax-16, we would introduce these dummy variables into a proof by using distinctors. Subject to this constraint - that per Andréka's theorem we will accumulate distinctor antecedents that can't be eliminated - my paper proves that the system ax-1 through ax-15 + ax-mp + ax-gen is otherwise a complete system of predicate calculus with equality and a single binary predicate.
--norm 7-Jan-2006
Size of a proof
Hi Norm, in the news you often say that a new proof is shorter but how do you calculate it ?
--frl 27-Feb-2006
From set.mm:
Usually I will automatically accept shorter proofs that (1) shorten the set.mm file (with compressed proofs), (2) reduce the size of the HTML file generated with SHOW STATEMENT xxx / HTML, (3) use only existing, unmodified theorems in the database (the order of theorems may be changed though), (4) use no additional axioms, and (5) involve none of the special cases listed below [see set.mm for special cases].
--ocat 27-Feb-2006, revised norm 15-Mar-2006
Oh yes thanks and is there a way to count the steps of a proof where all the intermediate rules would have been replaced by their own proofs recursively until only the axioms remain ? – frl 28-Feb-2006
Yes, the 'trace_back' command will do this, up to a billion steps.
MM> show trace_back prth / count_steps / essential The statement's actual proof has 5 steps. Backtracking, a total of 56 different subtheorems are used. The statement and subtheorems have a total of 199 actual steps. If subtheorems used only once were eliminated, there would be a total of 25 subtheorems, and the statement and subtheorems would have a total of 143 steps. The proof would have 2589 steps if fully expanded. The maximum path length is 22. A longest path is: prth <- imp4b <- imp4a <- impexp <- imbi1i <- impbi <- bi3 <- expi <- expt <- pm3.2im <- con2d <- con2 <- nega <- pm2.18 <- pm2.43i <- pm2.43 <- pm2.27 <- id <- mpi <- com12 <- syl <- a1i <- a1i.1 .
Beyond 2^31 steps, the arithmetic overflows the way the program is written now. Rather than mislead the user with a garbage number, it stops at a billion and just prints ">1000000000".
MM> show trace_back 2p2e4 / count_steps / essential The statement's actual proof has 11 steps. Backtracking, a total of 2153 different subtheorems are used. The statement and subtheorems have a total of 22775 actual steps. If subtheorems used only once were eliminated, there would be a total of 1569 subtheorems, and the statement and subtheorems would have a total of 21535 steps. The proof would have >1000000000 steps if fully expanded. The maximum path length is 134. A longest path is: 2p2e4 <- 2cn <- 2re <- readdcl <- axaddrcl <- addresr <- 0idsr <- [...]
Note that 'show trace_back' without '/count_steps' will list all subtheorems found during backtracking. In principal, this backtrack list could be used (by a program or metamath function that does not yet exist) to create a minimal set.mm subset needed to prove a particular theorem. Without '/essential', the steps used to construct wffs (that you see in 'show proof xxx/all') will also be counted. 'show trace_back/essential/axioms' tells you the axioms and definitions assumed for the proof.
--norm 28-Feb-2006
Well thank you. I wonder if it is possible to prove that a given proof is the shortest one (once all the steps have been recursively replaced by the axioms). --frl 1-Mar-2006
The only way I know of to "prove that a given proof is the shortest one" from the axioms is exhaustive enumeration. The only project (that I am aware of) that has been concerned with this is the "Shortest known proofs of the propositional calculus theorems from ''Principia Mathematica''". All proofs up to length 21 (or maybe 23) were found by exhaustive enumeration of all possible proofs, so they are therefore the theoretical shortest. Any longer proofs were found by "cleverness" and may not be the shortest possible. --norm 2-Mar-2006
The Bernays problem
Question
Here is the problem. A (propositional calculus) theorem (let's say stricto sensu; not an inference) being given, is it possible to design a system of axioms from which the theorem can't be derived? I think we can name this problem (if it is a problem after all) after the creator of intuitionism. I have always found highly funny the decision that Brouwer had taken to remove a certain theorem from propositional calculus (namely `the tertium non datur') only because he considered it to be immoral. --frl 6-Mar-2006
Answer
I asked mathematician Eric Schechter to answer this. He has written a wonderful book, Classical and Nonclassical Logics: an introduction to the mathematics of propositions, that covers these kinds of topics and that I highly recommend. This is not just another introductory logic book, but it goes into many exotic propositional logics that are topics of recent research, yet it provides all the necessary background in a very clear and readable style, with few mathematical prerequisites.
- Pretty expensive ( as a French I'm always amazed by the price of technical books in the anglo-saxon world ) but I'll ask main public libraries in Paris whether they can add it on their shelves. – frl 9-Mar-2006
- I'm happy to announce that Classical and Nonclassical Logics: an introduction to the mathematics of propositions is now available in free access in Paris at the library of Beaubourg. The book is new; it is very well printed; it is very well written; the pedagogical sense of Schechter is perfect; his sense of humour is great ( I have really liked his development about relationships between insomnia and set theory ) and his way of presenting logics is different from the tradional books with an emphasis put on the non classical logics. His presentation of semantic is crystal clear. The only regret is that there is no section about predicate calculus. frl 1-Jul-2006
- .
- .
- University libraries may have it already, or if not would probably be receptive to adding it. The MIT library has it, for example. – norm 10-Mar-2006
Here is his response (the period between paragraphs is mine because I don't know how to put a blank line between indented paragraphs - anyone?):
- The question doesn't make much sense unless we add the requirement that the system of axioms can derive certain other things. In other words, we want to find a system of axioms (and assumed inference rules, though in many cases detachment is enough) such that certain given formulas are derivable, but certain other formulas are not derivable.
- .
- The answer is yes, there are plenty of examples of that. In fact, my whole book is chock full of them; that's just the kind of example that my book is all about. The simplest examples are given by finite matrix interpretations.
- .
- All we need is soundness. That's the easy half of completeness; it's discussed in Chapter 21 (a very short chapter). It is a way of establishing that all the theorems of some axiomatic system are tautologies (i.e., always-true formulas) of some interpretation. It then follows (contrapositively) that any non-tautology is not derivable from the axioms.
- .
- (Of course, the fact that we can use this contrapositive is because I'm assuming the metalogic is classical. If we use some nonclassical logic for our metalogic, we could run into complications, since some versions of the contrapositive law fail in some nonclassical logics.)
- .
- For instance, tertium non datur (the law of excluded middle) is not derivable from the axioms of intuitionistic logic, which I prefer to call constructive logic. To see that, we just need to consider some topological interpretations. All the axioms, and therefore all the theorems, of constructive logic hold in every topological interpretation; that's established in 22.14 of my book. But tertium non datur fails in many (though not all) topological interpretations. For instance, it fails for the Euclidean topology of the real line (see 10.4). It also fails for a finite interpretation, given by taking the set {0,1} and equipping it with the topology { emptyset, {0}, {0,1} }.
- .
- But perhaps frl actually wanted not just some examples, but an algorithm for producing examples to fit some particular specifications. That's a much harder problem, one for which I don't have an answer. And, depending on how the problem is posed, it might even be unsolvable.
- .
- I do have a partial answer: There are some computer programs that can assist with looking for such examples. Some of the best programs of this type are described at
- Among those, the only one I've used is
- MaGIC? (Matrix Generator for Implication Connectives)
- which was written by John Slaney and ported to Windows by Norm Megill. And I've really only used it once. I used it to discover the interpretation that I call "Church decontractioned", which is described in sections 9.14-9.18 of my book. I found it as an example to show that what I call "basic logic" (chapters 13-14), plus the formula
specialized contraction (15.3.a) (A -> (A -> ~A)) -> (A -> ~A)
- is not sufficient for deriving
weak contraction (15.2.b) (A -> (A -> ~B)) -> (A -> ~B)
- – in other words, specialized contraction is strictly weaker than weak contraction, even in the presence of all of basic logic. To prove that fact, we simply observe that "Church decontractioned" is sound for basic logic plus specialized contraction, but weak contraction is not tautological in that interpretation.
- .
- …name this problem (if it is a problem after all) after the creator of intuitionism.
- .
- I don't see any reason to name it after Brouwer. If you want to name it after someone, maybe a better choice would be Paul Bernays. Rescher's book "Many-valued Logic" says that Bernays was the first to use multivalued logics to demonstrate that some formula cannot be derived from some axiomatic system.
Thank you, Eric.
norm 7-Mar-2006
Thank you Eric, thank you Norm frl
Compressed Sub-Proof Start Demarcation
Question
Metamath.pdf's description of sub-proof in the documentation of Compressed Proofs is not explicit about the start of a sub-proof and how to find it. I am thinking that the "Z" marks the end of a sub-proof and that the number immediately prior to a "Z" will correspond to one of the parenthesized labels?
Also, the parenthesized labels are the non-syntax assertions referenced in the proof?
Excerpt from Metamath.pdf:
The letter Z identifies (tags) a proof step that
is identical to one that occurs later on in the
proof; it helps shorten the proof by not
requiring that identical proof steps be proved
over and over again (which happens often when
building wff’s). The Z is placed immediately
after the least-significant digit (letters A
through T) that ends the integer corresponding to
the step to later be referenced. The integers that the upper-case letters
correspond to are mapped to labels as follows. If
the statement being proved has m mandatory
hypotheses, integers 1 through m correspond to
the labels of these hypotheses in the order shown
by the show statement ... / full command, i.e.,
the RPN order of the mandatory hypotheses.
Integers m+ 1 through m+ n correspond to the
labels enclosed in the parentheses of the
compressed proof, in the order that they appear,
where n is the number of those labels. Integers m
+ n + 1 on up don’t directly correspond to
statement labels but point to proof steps
identified with the letter Z, so that these proof
steps can be referenced later in the proof.
Integer m+n+1 corresponds to the first step
tagged with a Z, m+n+2 to the second step tagged
with a Z, etc. When the compressed proof is
converted to a normal proof, the entire subproof
of a step tagged with Z replaces the reference to
that step.(I'm having one of my El Stupido days. Eventually I could probably figure out the algorithm but I am hoping for a big clue.)
Thanks. ocat 14-Mar-2006
Answer
OK, here's a first attempt at an explanation. We'll keep trying if it doesn't suffice.
Consider first a compressed proof with no Z's in it. Hopefully you are at the point where you can see how this can be translated to a standard RPN proof.
Now, given anything in RPN - whether a proof or a formula - if you pick an arbitrary point in the middle, there is a smallest sequence of previous steps that leads to that point. Think of an arithmetical expression in RPN: (2+3)+4=9 in RPN is 23+4+. For any point in that expression, there is a corresponding subformula. Going left to right, the subformulas are: 2, 3, 23+, 4, 23+4+.
When it is verifying a proof, the Metamath program actually doesn't care about subproofs. It scans along the the compressed proof string, pushing and popping the stack as it goes along. Whenever it sees a Z, it simply saves the stack top for later use whenever it gets referenced later in the proof. It is that simple, and it makes verification fast.
For some purposes, such as translating the proof to non-compressed, you do need to know where subproofs start. To do this, you scan the proof from left to right and populate a parallel integer array with the length of the subproof at each step. For the formula example above, the array for 23+4+ above would have subexpression lengths 1,1,3,1,5. (A number has subproof length 1. When a + is encountered, you add the lengths of the two subexpressions it connects, plus 1. So to compute all subexpression lengths, you need only a one-pass scan through the RPN expression.) Then whenever a subproof is referenced, you copy as many steps as are indicated by this parallel array. A subproof can reference another subproof, but if you transform the compressed proof into the complete non-compressed proof as you scan along, copying the corresponding piece of the "subproof length" array along with the subproof, this should all take care of itself automatically, in a single pass through the proof.
Also, the parenthesized labels are the non-syntax assertions referenced in the proof?
The label list includes any non-mandatory $f's (used for dummy variables in the proof) as well as all the assertions used by the proof, syntax and non-syntax, in any order. Its purpose is to map long label names to the short uppercase "numbers" in the compressed proof. The label list doesn't include mandatory $f's nor $e's, since they can be inferred from the "frame" (context) of the $p statement and thus would be redundant. This of course has an impact on how statements with compressed proofs can be edited, which is discussed in Section 2.5 of the book.
--norm 14-Mar-2006
(I copied the following from the mmj2Feedback page since it supplements this topic.)
In marnix's 440-line Hmm proof verifier, the compressed proof code (located in HmmImpl.hs) is 80 lines long. The compressed proof format is precisely documented in Appendix B of the Metamath book, from which Marnix wrote his verifier. He provided me with this helpful outline of his nice algorithm, which I have now incorporated into the Metamath program also:
A..T stand for 1..20 in base 20, and U..Y stand for 1..5 in base 5. (So not 0..19 and 0..4.) This is when counting A=1, etc., as in the book; which seems most natural for this encoding. Then decoding can be done as follows:
* n := 0
* for each character c:
* if c in ['U'..'Y']: n := n * 5 + (c - 'U' + 1)
* if c in ['A'..'T']: n := n * 20 + (c - 'A' + 1)For encoding we'd get (starting with n, counting from 1):
* start with the empty string
* prepend (n-1) mod 20 + 1 as character using 1->'A' .. 20->'T'
* n := (n-1) div 20
* while n > 0:
* prepend (n-1) mod 5 + 1 as character using 1->'U' .. 5->'Y'
* n := (n-1) div 5--norm 15-Mar-2006
Proof Compression Algorithm
Question
Hi Norm, I have coded Decompression (though not yet tested it), and I have come to the conclusion that I must code Proof Compression also. I imagine that seeing a 600 line uncompressed proof pop up in the mmj2 Proof Assistant would be most unwelcome. Given that there are only 2 mmj2 "customers", I must go the extra mile and not annoy either of you :0)
For it is written:
For I say unto you,
That unto every one which hath shall be given;
and from him that hath not,
even that he hath shall be taken away
from him.
(Luke 19:26 KJ)The problem of compressing a Metamath proof in the most efficient manner, either as a "one off" or as part of a batch (all proofs in a file), is interesting. It seems to amount to finding duplicate subtrees of depth > 1 in a proof tree and replacing them with pointers (or in technical terms, "gnarfling the garthok".)
Do you have an elegant algorithm in hand?
Thx. ocat 18-Mar-2006
Answer
Well, I don't know if it's "elegant", but the functions are relatively short.
The encoding algorithm used by the metamath program involves 2 functions:
- 1. 'nmbrSquishProof' creates a "compact" proof.
- 2. 'compressProof' generates the compressed proof syntax.
These two functions exist in mmdata.c.
A "compact" proof is a superset of the normal RPN proof syntax that has backreferencing internal labels. You can see it if you use the (undocumented) 'save proof xx/compact' command then look at the new source output.
The 'nmbrSquishProof' algorithm works approximately like this (looking at the comments in that function, which I haven't visited in years). It scans forward through the proof and considers the subproof at the current step. It scans the rest of the proof from the current step, and anywhere it finds that subproof, it replaces it with a reference to the current step. The reference consists a negative number representing the offset of the earlier subproof; negative is used so it won't be confused with a real label, which is always a positive integer. (Internally it doesn't store the actual labels, but their "statement number", so the proof is an array of integers.)
Because we always want the longest possible earlier subproofs to be referenced, the replacements are done in a parallel array so that the subproof matches won't be upset by earlier replacements. Or something like that…I refer the reader to mmdata.c. Hey, it works. :) It is kind of fuzzy to me now, and I don't have a lot of time to spend at the moment, but ask me more questions if you need help figuring it out and I will look at it more deeply.
(There are probably other ways to do this, but the idea is just to find the longest match to an earlier subproof. I suspect you'll probably come up with you own way of doing it that may even be better.)
The 'compressProof' function is just a mechanical translation to the compressed proof syntax. It will actually work with an "unsquished" (standard RPN) proof, which is a subset of the "compact" proof syntax, although it wouldn't make sense to do that; my point is that it is completely independent of 'nmbrSquishProof'.
--norm 18-Mar-2006
- Thanks. I will review your algorithms and make a serious attempt at this problem. I spent some time on Google looking for related information. Came across Dick Grune's name again, and found that people all over the world are beavering away on "repeated subproofs" and tree compression. I will post some links that seem interesting (though not obviously useful on this problem). --ocat 18-Mar-2006
Data Mining set.mm
Question
I wonder how many repeated subproofs are repeated across theorems in set.mm – not including "syntax proofs". And might there be repeats that merely use different variables and could be unified to a common subproof? Perhaps we could data mine set.mm's proofs to discover candidates for theorem-hood? --ocat 24-Mar-2006
Answer
I am always on the lookout for common subproofs, and I will add one as a new theorem when the total size of the new theorem (including its comment) is less than the total size it trims off of the proofs that it ends up shortening. In other words, I always like to add a new theorem that "pays" for itself by reducing the total size of set.mm (measured with compressed proofs).
Indeed, I encourage people to try to discover such patterns, and that is one way to get your name into set.mm. From set.mm,
- Usually I will also automatically accept a new theorem that is used to shorten multiple proofs, if the net size of set.mm (including the comment of the new theorem) is decreased as a result.
Whenever (based on the date stamp) you see a more recent theorem used to prove an older one, most likely the more recent one was a new recurring subproof that was discovered. One example is peano2re, which just says "( A e. RR → ( A + 1 ) e. RR )", replacing the sequence ax1re, mpan2, axaddrcl. This shortens 43 proofs and more than "pays" for itself.
Something like peano2re that saves only a step or two typically needs to be used between 10 and 20 times before "paying" for itself.
When I notice a pattern I think I've seen a number of times before, I'll test a new theorem for the pattern by running a script that attempts to use it everywhere possible with the Proof Assistant's "minimize_with" command. Too often I find I was deluded by determining that it shortens only say 2 or 3 proofs, in which case I will scrap it unless I think it will eventually pay for itself in the future.
Every now and then I'll run across a gem that will pay for itself in only one extra proof that it simplifies. One of the most impressive examples is en2/dom2 and friends, which simplify equinumerosity proofs so dramatically, by removing all of the messiness of existentially quantified 1-1 functions and so on, that their compressed proofs listings are sometimes shorter than the textbook versions in terms of number of lines. Look at dom2: from very simple hypotheses, we conclude the relatively advanced relation of dominance (which is indicated by all the definitions the proof is based on, shown on the bottom of the proof page). The proof of dom2 (actually dom2d) takes all the messy function stuff and distills it down to something very simple, involving no quantifiers and nothing more advanced than = and epsilon. I'm actually rather proud of it. :)
--norm 26-Mar-2006
Minimizing proofs
Question
I recently came across the metamath "minimize" feature. It seems to me that one can only use it with the proof one is just working on. But supposing one adds a new theorem and one wants to minimize the proofs of the existing theorems, is there a way to do that in a – let's say – batch style? frl 6-May-2006
Answer
There is no built-in automatic way. The following is one way to do it with commands typed in at the MM> prompt. 'xxxx' is the new theorem name. You can also reformat the 'show label' output with a Unix script instead of the 'tools' commands if you prefer.
You can put parts of this procedure in a command file for the 'submit' command, with the restrictions: (1) you can't 'submit' from inside of a command file and (2) the 'submit' command doesn't take arguments, so you can't send the the theorem name to it. [Both of these features could be added in principle, but currently they are not on my to-do list for lack of demand.]
open log 1.tmp show label */linear close log tools match 1.tmp $p '' delete 1.tmp '' ' ' delete 1.tmp $ '' add 1.tmp 'prove ' '&minimize xxxx&save new_proof/compressed&quit' substitute 1.tmp '&' '\n' all '' quit submit 1.tmp
At the end, 'show usage xxxx' will tell you which proofs were reduced. Alternately, before 'submit 1.tmp', I like to 'open log 2.tmp'. Then I can search the log for the word 'decreased' to see how much the proofs were reduced. --norm 6-May-2006
Nat.mm is nearly finished
In fact I have succeeded in importing Frank Pfenning's axioms. I only simplified predicate calculus ones ( I removed the substitution operator ) but it is not an important modification, we could just have left the existing axioms but it would have been less smooth. Propositional calculus is imported with no modification. As you know I didn't succeed in finding a set of axioms to implement the syntactical definition of bondage ( I still think it should be possible however ) but the new axiom which uses the '(ph → A. x ph )' statement works perfectly. There is only two points that I can't understand in Pfenning's set of axioms. 1) He gives two axioms to deal with equality (in fact stdpc6 and stdpc7) but from these two axioms I think we can't expect to derive back set.mm axioms about equality. Therefore I guess the only point on which set.mm really differs from a textbook set of axioms concerns its way to manage equality : could you tell us more about it ?
- I assume you have read Appendix 3: Traditional Textbook Axioms of Predicate Calculus with Equality. We can add stdpc6 and stdpc7 as axioms - and it would probably be a good idea, to help the user correlate your work with Pfenning's - but they will not be sufficient. The problem is again (just as for variable binding) that the traditional (Pfenning's) system involves metamathematics about the structure of a formula in its concept of "free for", whereas the axioms in set.mm deal only with the logical properties of a formula. So, "free for" is expressed with a logically (but not structurally) equivalent representation involving set.mm's proper substitution notation, as you can see in stdpc7. The advantage of doing this is that we need no "external" metamathematics, e.g. in the proof checker, to prove general-purpose metatheorems from the axiom schema. This is what the "meta" in "Metamath" is all about, and it makes Metamath's proof-checking engine very simple. The disadvantage, though, is that the implicit metalogic in the textbook schema effectively has to be performed explicitly in the proof itself to arrive at logically equivalent results, and we need a bunch of technical axioms, ax-8 through ax-16, to accomplish that. Now if you add stdpc6 and stdpc7 to ax-8 through ax-16, it is very possible that several of ax-8 through ax-16 will become redundant - and it would be an interesting exercise to try to determine which ones - but most likely not all of ax-8 through ax-16 can be eliminated.
- .
- Thank you Norm for all these answers. There are many different things and I shall try to elucidate them during the next week. Obviously there is still something that I don't understand about the exact nature of metamath. I think there is something that could help me: giving a definition of metamath logic in formal terms (very formal in the most 'metamathical' fashion in fact) ant trying to compare it with a formal textbook definition of logic. I will try too. The things I hope to grasp more deeper this way is
- .
- 1) the relationship of metamath with the logical systems you describe in your paper
- .
- I wouldn't worry too much about that, since most of the paper focuses on $d-free systems. The system S3' (set.mm's) is basically an extension adding in the $d's to make it more flexible.
- .
- 2) the absence (?) of schemas in metamath and their presence in textbook logic,
- .
- Metamath's "axioms" (a misnomer) are really schemas just like the schemas of textbook logic. Try to think of them in that way. For prop. calc., these schemas are the same. The main difference in pred. calc. is that the metalogical notions the schemas are allowed to use are more restricted than in textbook logic - e.g. no explicit "free variables" - and as a result we need more schemas for completeness. But each Metamath schema can be (metalogically) derived from textbook schemas. In fact I strongly recommend doing this as a pencil and paper exercise - from Hilbert-style textbook schemas, not Pfennings, to start with - so that you can see the connection. If you get stuck, even on the first one if you don't "get" the idea, post here and I'll help you work through it.
- .
- 3) The fact that individual variables are distinct in normal logic system and the fact they are not distinct in metamath
- .
- That Metamath's variables are not distinct by default is merely a convention. An alternate equivalent language could be devised where instead of specifying $d's for distinct variables, we specify say $n's for ones that don't have to be distinct.
- .
- My choice of not having $d's in most of the axioms in set.mm was also arbitrary. It was mainly done (1) to show how far we could get without $d's, (2) to make the axioms more compact by effectively combining two cases into one, e.g. E. x x = y and E. x x = x, and (3) because the technical simplicity of a $d-free system, with no free/bound variable conflicts ever to worry about, appealed to me. Perhaps this was a poor design decision from a human point of view, I don't know. But it is certainly possible to have a logically complete set.mm axiom system with $d's on all set variables in all axioms. Then, if we want metalogical completeness (optional, not a logical necessity), we'd add one or more axioms to give us all the non-$d cases. This would a kind of reverse of what we now do with ax-16. And, provided we choose the metalogical completeness option, we could derive each system from the other in Metamath itself. (If we don't choose that option, we could still derive them from each other, but with informal metalogic outside of Metamath.)
- .
- The mmnotes.txt entry for 11-May-06 also has a related discussion about informal textbook notation P(x) to indicate that x is a free variable in wff P.
- .
- 4) the use of metalogic in proof-checkers other than metamath. – frl 19-May-06
- .
- Only a few of them allow wff metavariables (Isabelle does, Otter doesn't). I don't know how it is usually implemented, but I would guess it is probably not a natural fit but instead an awkward add-on to the main algorithm, perhaps simulating wff variables with temporary predicate constants. In Otter, the issue has been avoided in one of its set theory developments by using finitely axiomatized NBG set theory. – norm 20-May-2006
2) Pfenning doesn't give axioms for the 'belongs to' operator.
- ('Belongs-to operator' is usually called the 'membership relation'.) Actually, he does. All of the equality axioms for the membership relation follow immediately from the equivalent of stdpc7 in Pfenning's system. To see this, write down one of the membership equality axioms, and look very carefully at the definition of "free for", keeping in mind that the membership relation is a binary predicate symbol. But to derive them from set.mm's version of stdpc7, you almost certainly need some of the technical axioms ax-8 through ax-16, but offhand I don't know which ones.
In set.mm you say that it is possible to give a definition of equality using the 'belongs to' operator. But is it possible to omit the 'belongs to' axioms and to define it using equality ? --frl
- No, it is not possible to define the membership relation in terms of equality. --norm 18-May-2006
P.S.: In the htmldef statements you use a _wff.gif image that I can't find in symbol.zip. Where is it ?
- symbols.zip has only standard black symbols. Colored and custom symbols such as _wff.gif are found in the mpegif directory, and their names almost always start with an underscore ('_'). --norm 15-May-2006
- Ah thank you.
{kind=link}
Metamath.pdf Spec Change Proposal
Problem: a Metamath formula's exact meaning is presently
======== unresolved without access to the variable
hypotheses in scope of the statement where
the formula occurs. To determine the Type Code of a variable
in a formula, which is a necessary
determination for parsing, it is necessary
to perform a lookup to find the associated
Variable Hypothesis, which then provides
the associated Type Code.(1) Solution: This extra lookup step could easily be
========= avoided by programs operating on Metamath
databases if: a) Internally formulas can be defined to
consist of Constants and Variable
Hypothesis Labels (instead of Constants
and Variables);and
b) The Metamath.pdf specification is changed
to outlaw a Variable Hypothesis label that
is the same as any Constant in the Metamath
database. Because a Metamath Variable Hypothesis can refer
to no more than one Variable, regardless of
whether the Variable Hypothesis is Active or
Inactive, even if subsequently re-activated,
a Variable Hypothesis label is unambiguous about
which Variable is being referred to. The converse
is not true, as in theory a single Variable can
be referred to by multiple Variable Hypotheses
of different Types. Impact: The likely impact on existing Metamath files
======= is negligible. It is highly unlikely that anyone
has created a Metamath file containing a Variable
Hypothesis label that is the same as a Constant. A trivial change to existing programs that validate
Metamath files will be needed, if full conformity
to the Metamath.pdf specification is to be maintained. Retrofitting existing code such as mmj2 to
immediately take advantage of this specification
change is unlikely. Rather, this change is
proposed for the benefit of future programs. Note also that there are workarounds in the event
that this proposal is not accepted as given. For
example, a formula could be stored as an array
of object references without regard for labels
and symbols. This proposal is intended merely
as a grammatical restriction to provide
flexibility for future uses of Metamath. Footnotes:
==========
1) During initial file load mmj2 takes advantage of
the specification requirement that each variable
reference must refer to a variable declaration that is
Active at the point of reference, and that, at that
point in the input Metamath file/database there must
be an Active Variable Hypothesis pointing to the
variable -- inside the mmj.lang.var.java object a
reference to the currently activeVarHyp is stored.
However, post-initial load the activeVarHyp reference
is useless.--ocat 21-May-2006
What is it with you computer science people? First, Raph had to do a workaround because there used to be a theorem whose label was "1o" (since changed) and a constant named "1o", and now this…
Maybe it's just me, but there seems to be such a fundamental difference between labels and math symbol tokens, down to the syntax of what characters are legal, that I would think that it would be natural for any parser to put them into completely different arrays from the start, as metamath.exe does. Then, for efficiency, all internal mentions of labels and math tokens would be numerical pointers to positions in those arrays, and the corresponding strings never used again (except for display purposes). But I'm no computer scientist. :)
What if I just make the following universal prohibition at the end of 4.1.1, to make everyone happy: "No label token may match any math symbol token.\footnote{This restriction did not exist in earlier versions of this specification. While not theoretically necessary, it is imposed to make it easier to write certain parsers.}"
Discuss. --norm 21-May-2006
Norm, I agree with your proposal. It amounts to specifying that Metamath Constant, Variable and Statement Labels share a single namespace.
Another rationale for the specification change is supporting the eventual converion of .mm files to relational databases – every "math object" will have a unique name. And, as mentioned, a formula can be stored unambiguously as follows:
|- ( wph -> wps )
Just as a side note, the idea of storing set.mm in a fully normalized relational database is not as crazy as it may sound.
The .mm format in plain text files requires continual re-validation to make sure that everything remains consistent. That means re-verifying all proofs and re-parsing formulas pretty much all the time just to be safe. But with a database safeguarding the data, with the help of custom code on top of the RDBMS, that can be avoided. And the full set of modern tools for querying and manipulating databases becomes immediately available. One immediate need would be to extract into .mm format for the benefit of the old "legacy" programs.
It is also likely that availability of Metamath "databases" in real databases will stimulate the imagination of new users, who may be motivated to provide new activities involving Metamath systems.
One reason, perhaps, why Metamath has not become wildly popular on a global basis -- aside from the steep learning curve -- is that the paucity of activities (i.e. "fun stuff"). After all, what can one do with Metamath now except to a) prove theorems and b) read the Proof Explorer website? The spirit-crushing magnitude of set.mm alone may deter all but the most courageous mountain climbers…
So, we need to manufacture new fun activities for students and adventurers, and at the same time, somehow discover what reasons do the world's mathelogicians have for not using Metamath. (Metamath also contains many universes for computer scientists/programmers to explore.)
--ocat 23-May-2006
I will wait a month and then, based on the discussion here (and the mood I'm in that day :), decide whether to go ahead with the shared namespace spec change. I probably will go ahead with it.
--norm 24-May-2006
I think it makes sense to do, and may be very useful in certain programming contexts, though not all. In the long run it will be helpful for the VR input method handler to know that each "gesture" is unique :)
If I were to implement the change in mmj2 I would most likely combine the Symbol table and Statement table to avoid double lookups at file-load time.
Perhaps users not monitoring the Asteroid should be given notice at the Notes section of metamath.org.
--ocat 26-May-2006
Final disposition
ocat's namespace proposal has been officially approved, and the on-line ''Metamath'' book has been updated (see footnote 6 on p. 94 of the Metamath book). People with a printed copy of the book should add the sentence referenced by that footnote. (A product recall is not planned at this time.) Version 0.07.17 of the Metamath program enforces the new namespace requirement.
This is the second spec change since 1997. The other change was a few years ago, requiring all labels to be unique instead of allowing $e / $f labels to be reused, again to simplify writing parsers.
--norm 30-Jun-2006
Conundrum of Extensionality
Hi Norm,
There are a couple of things I am just not "getting", and they're tangled in a Gordian Knot.
The context is that I am looking at free vs. bound vs. $d statements and at notation differences between Metamath and "standard" set theory notations.
Regarding bound variables, I understand that ' A. ' (for all) and ' E. ' (there exists) bind variables so that they do not occur free in formulas. ' A. x -. x e. x ' binds ' x ' – ' x ' does not occur free in ' -. x e. x '.
I interpret that as meaning that the name of a bound variable 'x' does not matter, another variable name could be used and the meaning of the formula would stay the same. Just as in programming, 'i' could just as well be 'j' in
' for (int i = 1, i < n, i++) { blah } '.If 'n' were changed then the meaning would change because 'n' occurs free in the programming statement. But the name, 'i', is irrelevant in that context.
However, in the following C expression, both 'i' and 'j' are bound; their specific names are irrelevant but their names must be different and must be different than the names of other, free variables referenced in the body of the statment.
' for (int i = 0, j = 1; i < n; i++, j++) { blah } '.Now, in the Axiom of Extensionality, the English definition is "Two sets are equal if they have exactly the same elements.".
In standard set theory notation, the axiom is written:
A. A A. B ( A. x ( x e. A <-> x e. B ) -> A = B )
In that formula, 'A', 'B' and 'x' are bound – there are no free variables, and no mention anywhere of further restrictions (such as 'for all x free in y' or suchlike.)
The Metamath formula of the Axiom of Extensionality is:
$d x y z w v u t $.
ax-ext $a |- ( A. z ( z e. x <-> z e. y ) -> x = y ) $.So now I have three conundrums:
1) Why isn't the Metamath formula written:
$d x y z w v u t $.
ax-ext $a |- A. x A. y ( A. z ( z e. x <-> z e. y ) -> x = y ) $.I assumed that the prefix 'A. x A. y' are not necessary because of the $d specifications… but if so, then…
- No, it doesn't have to do with the $d's. The versions with and without the prefix 'A. x A. y' are equivalent: ax-gen can add it to set.mm's version, and ax-4/ax-mp can remove it. I chose to remove it to shorten the axiom. Some texts add it obtain wffs with no free variables (called "statements"), either as a matter of style or to be compatible with predicate calculus axiomatizations that do not allow free variables.
2) Why can't it just be written as:
$d x y z w v u t $.
ax-ext $a |- ( ( z e. x <-> z e. y ) -> x = y ) $.- Because this isn't true for all x,y,z. E.g. let x = 0, y = {0}, z = {{0}}. Then the antecedent is 'false <→ false' i.e. true, but the consequent is false.
ALSO…
3) Why are there so many $d restrictions on ax-ext? Wouldn't it be sufficient to write:
$d x z $.
$d y z $.
ax-ext $a |- ( A. z ( z e. x <-> z e. y ) -> x = y ) $.- Yes, it would. In fact this "stronger" version is proved as zfext2 (whose proof I think you will find instructive). I am simply following the usual textbook convention of stating the starting axioms with all variables distinct. There is also the opposite extreme of stating them with no $d's. :) – norm 8-Jun-2006
--ocat 8-Jun-2006
I'm having a hard time translating ax-ac into a concise yet faithful English sentence:
ax-ac $a |- E. y
A. z
A. w
( ( z e. w /\ w e. x ) ->
E. v
A. u
( E. t
( ( u e. w /\ w e. t ) /\
( u e. t /\ t e. y ) )
<-> u = v
)
) $.--ocat 19-Jun-2006
Answer
"Given any set x, there exists a y that is a collection of unordered pairs, one pair for each non-empty member of x. One entry in the pair is the member of x, and the other entry is some arbitrary member of that member of x."
Actually, I don't think it's worth trying to understand its raw axiomatic form. It is simply the shortest equivalent to the longer standard axiom that I was able to come up with by applying logical transformations without regard to meaning. Perhaps an analogy is Meredith's axiom, whose purpose is just to show a shortest possible single axiom for propositional calculus: you "understand" it by showing its equivalence to axioms that make sense to humans.
You may want to look at ac3, which is ax-ac restated with abbreviations and is accompanied by a detailed explanation as well as a concrete example.
The standard textbook version of AC is derived as ac8.
--norm 19-Jun-2006
Substitutability WRT Named Typed Constants and $d
Question
A rarely considered fact is that $d restrictions only apply to variables substituted into variables; any constants inside the expressions substituted in are ignored, even if these are Named Typed Constants representing actual classes.
I have not yet satisfied myself regarding the rationale behind this. Obviously, it makes sense to ignore punctuation/delimiter constants such as "(", when verifying distinct variable restrictions, but the reasoning is not so clear when constants naming actual class objects are considered. In effect, a class object could be substituted into two variables subject to distinct variable restrictions, and no error message would result. --ocat
Answer
Here is one way to think about it. Whenever you have a theorem with $d x A, it is logically correct to substitute for A any class expression in which all variables are bound (although Metamath won't let you do this directly when the expression contains x, even if x is bound.)
All set variables in the definition of a Named Typed Constant must be bound. For example, "(/)" is defined as "{ x | x =/= x }", where x is bound. Indeed, this is a requirement for the definition to be sound.
Now, consider the theorem "E. x x = { A }" (the singleton of any class exists). We need $d x A for this to hold - otherwise, we could conclude E. x x = { x }, which is false in ZF set theory. Now, replace A with (/), to obtain E. x x = { (/) } with no $d. Then, replace (/) with { x | x =/= x }, to obtain E. x x = { { x | x =/= x } }, again with no $d. But no $d is necessary, since x is bound on the rhs of the =. In fact, this can be a useful trick to get rid of unnecessary $d's: in the original theorem, we are not allowed to substitute { x | x =/= x } for A at all, and we are not allowed to substitute { y | y =/= y } for A unless we specify $d x y. --norm 27-Jun-2006
OK, that makes perfect sense now. A Named Type Constant or its underlying definition can logically be properly substituted for a class variable because there are no side effects with variables in the enclosing scope (of quantification.) Done deal as far as I am concerned. And the definition for a Named Typed Constant must not contain any free variables or else it will not be a sound definition.
I will need to work more on substitutability, squaring this with this language: Substitutability (a bit more restrictive – "y does not occur in t and t is substitutable for x in a").
Getting closer. I'm dangerous now :) --ocat 27-Jun-2006
By the way, an equivalent way to say "t is substitutable for x in a" used by many books is "x is free for t in a".
That Wikipedia page illustrates the complexity of the metalogic of the traditional approach to predicate calculus, when it is fully formalized. The difficulty of verifying proofs using that metalogic was one of the motivations for the different, but logically equivalent, approach that Metamath uses.
The set.mm axioms are similar in many respects to the ones in Tarski's simplified formalization of predicate logic with identity, and were in fact greatly influenced by them. Tarksi writes in that paper:
- "Two of the notions commonly used in describing the formalism of (first-order) predicate logic exhibit less simple intuitive content and require definitions more careful and involved than the remaining ones. These are the notions of a variable occurring free at a given place in a formula and the related notion of the proper substitution (or replacement) of one variable for another in a given formula. The relatively complicated character of these two notions is a source of certain inconveniences of both practical and theoretical nature; this is clearly experienced both in teaching an elementary course of mathematical logic and in formalizing the syntax of predicate logic for some theoretical purposes."
Perhaps it would also be helpful to revisit the discussion of Metamath vs. the Traditional Textbook Axioms of Predicate Calculus with Equality. Most of the discussion involving free variables in a wff phi also applies to free variables in a class variable A. (In set theory, wff (meta)variables and class (meta)variables can be viewed as two different ways of representing the same thing, and one can be transformed to the other. An analogy might be the time domain and frequency domain in the theory of electrical signals.)
I should also mention that there are two logically equivalent (although not structurally identical) ways to express the concept of "x is not free in A", and they can be converted to each other. The first way is just $d x A, such as in theorem n0. The second way is the hypothesis $e |- ( y e. A → A. x y e. A ), where y is a new variable with $d y x and $d y A, such as in theorem n0f. I think of these mentally as "weak" and "strong" ways, since it is easy to go from "strong" to "weak" (just use ax-17) but hard the other way (see, for example, how dfss2 is converted to dfss2f). There is no exact match between either of these to the traditional "not free in" notion, but we have: "strong" => traditional not-free-in => "weak", where "=>" means superset of the wffs for which the condition holds. Examples: x isn't not-free in x = y in all three senses; x is not-free in x = x in the "strong" sense but isn't not-free in the traditional and "weak" senses; x is not-free in A. x x = x in the "strong" and traditional senses but not in the "weak" sense; if $d x y, then x is not-free in y = y in all three senses.
Since neither of the set.mm "not free in" concepts correspond exactly to the traditional one, it is perhaps confusing to call either of them by that name, although both are logically equivalent to it. Sometimes I call the "strong" one above "effectively not free in". Their advantage over the traditional one is that they don't need a (somewhat complex) recursive definition. But neither of them apparently appear in the literature, so there seems to be no standard terminology for them.
--norm 28-Jun-2006, 30-Jun-2006
A few points:
1. Hirst and Hirst's A Primer for Logic and Proof – Excellent. A breath of fresh air after struggling with Enderton and friends :) I like the abundance of in-line examples for every key concept. And the straight talk down the main path, which can be complicated later by those with an interest in doing so :)
2. The Metamath .mm language is conceptually more fundamental (lower) than predicate calculus and can be used for other theories of reasoning, which may yet be invented. In predicate calculus variable binding is tied to the quantification operators, of which Metamath has no built-in knowledge or logic. As an experiment it would be interesting to define a superset of the .mm language which would include as an extra an optional "bound ___" stipulation on syntax builder axioms (such as "wex", say.) The proof verifier would be responsible for checking for substitutability per the traditional notions of such and verifying the $d restrictions (toggle on/off via runtime parameter.) We would then reprocess all 10,000 Metamath theorem proofs and ponder the results.
3. Unrelated: I googled free/bound and hit ACL2's use of the terms in its unification process. I noted with extreme interest that they recommend putting the "weightiest" hypotheses first to expedite unification – or else the combinatorial explosion problem might prevent finding the match. In mmj2's ProofUnifier I foresaw exactly that same problem thanks to a scan of set.mm which revealed a theorem with 19 hypotheses. I try to avoid the problem by presorting the hypotheses of the step to be unified, putting the longest formulas first and if formulas have equal length, the formula that has at least one variable in common with the unified step's formula gets precedence. Where I think I can optimize my code is that, unless memory fails, I should cache the result of the sort operation (which is only invoked if needed based on local conditions). It is interesting how these sorts of systems tend to need to solve the same problems, though sometimes in different form. In the end we just want to get the job done in the fastest, cleanest way possible. It may be that $d isn't all that much simpler than the "free/bound" concept of substitutability but if it works better then we need to respect that and pay attention to what that means.
--ocat 30-Jun-2006
I really dislike the existential quantifier
Question
How can I substitute x by another variable in an antecedent .
For instance I have |- ( ph → ( E. x ps → ch ) )
and I want |- ( ph → ( th → ch ) )
with somewhere |- ( x = y → ( ps <→ th ) )
Is it possible to do that ? – frl 27-Sep-2006
Answer
I believe you want to apply cla4ev with syl5. To go the other way, use 19.23adv, provided x doesn't occur in ph and ch. This, by the way, is one of the ways to emulate the "C rule" trick of traditional logic, where you get rid of an existential quantifier by introducing an imaginary constant to replace the quantified variable.
The following situation is very common: we want to prove ( ph → ( E. x ps → E. y ch ) ). We are able to prove ( ph → ( ps → th ) ), where th has x in it (basically th is a special case of ch that we are able to find assuming ps). First, we change this to ( ph → ( ps → E. y ch ) ) using cla4ev. Then we change it to ( ph → ( E. x ps → E. y ch ) ) using 19.23adv. An example of this is shown in step 21 of raph's r1pwcl. I personally feel that this technique is easier to understand than the "C rule," but perhaps it is just because I am used to it.
The restricted quantifier versions of cla4ev and 19.23adv are rcla4ev and r19.23adv.
--norm 27 Sep 2006
Equivalence of set.mm's CC and "the" complex numbers
Preface: I'm sure this is a naive comment. I am not a mathematician. I'm probably not even using the word "model" properly. Oh well. --jorend
I have heard that someone is claiming that 2 + 2 = 4. Not wanting to seem gullible, I have looked into it, and I have some questions.
set.mm contains a set-theoretic construction of (you could say: a model of) the complex numbers. It proves the axioms for complex numbers, which I will call "the postulates" here, from set theory and df-c. It seems to me this proves only that Metamath's set-theoretic construction of the reals is at least as strong as the postulates. How do I know it isn't stronger? In other words, you might prove something about Metamath's complex numbers that follows from set theory and the particular definition involved, but which doesn't necessarily follow directly from logic and the postulates. In particular, it seems possible that set.mm's theorem "2 + 2 = 4" does not follow from the postulates.
You could avoid this danger by using set theory only to prove the postulates, and then using only the postulates (and not any theorems involving the underlying set-nature of the model) from that point forward. But I don't think this is the case for the proof of 2p2e4. I clicked on opreq2i and immediately got into trouble.
I imagine there's a theorem of model theory that all models of the complex numbers are isomorphic in some relevant sense (and the same for functions, ordered pairs, etc.); and some sort of metatheorem that says that two isomorphic systems have all the same theorems and proofs. But I don't see anything along these lines in set.mm… am I wrong?
I'll withhold judgement on 2p2e4 until these questions are settled. --jorend 12 Oct 2006
Answer
The construction of complex numbers in set.mm is done in a stand-alone section that leads to the "postulates." The postulates themselves are independent of the construction in the sense that we could remove the Dedekind-cut construction that's there now and replace it with a Cauchy-sequence construction or any other.
When set.mm was first being built, the postulates were in fact true axioms, and a good percentage of the theorems there now about complex numbers were proved using them, as a theory extending ZF set theory. The object CC was primitive, with the only assumptions made about it being those stated in these axioms. Later, when the Dedekind-cut construction was completed, CC was changed from a primitive to a defined object, and the axioms were replaced by theorems (now called "postulates"), with no change to any of the complex number proofs that used them.
The real number developments in textbooks use "axioms" that presuppose and go on top of set theory. In elementary books, this fact may be unstated and informal, although without some set theory you can't get too far with the completeness axiom.
There may be real number systems that go directly on top of logic (not first-order, but second or higher order) and presuppose no set theory, but I am not familiar with them, though, and someone else might have something to say about it. I don't know how such a system would state or work with the completeness axiom.
The theorem opreq2i you mention is a theorem of set theory, but it is not part of the complex number construction, and a formalization that adds complex numbers as axioms would still use it. It was used in the original set.mm when the complex number postulates were still axioms.
An approach that would be "purer" in some sense would be to define the class of all complex number systems, just as set.mm now defines the class of all topologies or the class of all metric spaces. At a future date perhaps such a class might be defined for some purpose (studying sets isomorphic to complex numbers, etc.), and the present construction would provide a proof that the class of all complex number systems has at least one member. However, it is much more efficient to prove theorems about a fixed object CC, rather than have every theorem begin with the hypothesis "Let (CC,…) be a complex number system…"
How do we know that the theorems about complex numbers aren't using some construction-dependent property, that wouldn't hold for some other construction? Metamath does not ensure that directly, but to verify it we would remove the construction and replace the postulates with true axioms. All proofs should still be correct.
I went to some trouble to avoid referencing the construction even when it was tempting to do so. For example, when defining +oo (plus infinity), we need a "new" object. To make this construction-independent, I defined it in terms of CC itself, leading to the requirement that we use the Axiom of Regularity, not otherwise used in the construction of reals, to prove that the object is "new". I saw no way to avoid that axiom and also have a construction-independent +oo.
--norm 13 Oct 2006
Thank you, Norm. What a kind and thought-provoking answer. I meant to put a smiley ;) at the end of the question, by the way.
"real number systems … directly on top of logic": Oh, yes, I completely agree. No, I didn't mean to point in that direction.
"the class of all complex number systems": Interesting! I hope to follow up on this later.
opreq2i: Yes, I see now. Oops.
--jorend 13 Oct 2006
There is at least one other way to look at this question: a discipline of splitting a set.mm-like library into modules, and being careful about which modules import what. In particular, you'd have an interface containing "the axioms of complex numbers," and your set-theoretic construction of these numbers (i.e. df-c and the cloud of theorems supporting it) would export this interface. Then, other theorems like 2p2e4 would import the abstract complex number interface and not be able to reference theorems specific to the construction.
One excellent way to keep the designer of such interfaces honest is to provide at least two different constructions. For example, importing HOL should give access to Harrison's construction of the reals, which is based on entirely different principles than the usual set-theoretic Dedekind cut construction, but should nonetheless be able to export the same abstract complex number interface.
I'm sure there's a fairly deep metatheory around proof modules with interfaces, but frankly it's not of burning interest to me right now. I'm sure you could do a mechanical translation where all of the constants imported become variables instead, and the set of axioms imported is replaced by a big giant antecedent of the form "for all instances of the variables satisfying axiom 1, axiom 2, …, axiom n", and the result would be fairly similar to the "class of all complex number systems" proposed by Norm above. But I'm not really sure how much you gain from this exercise. It may be possible to derive essentially the same results with less pain by using a generic theory of isomorphism, so then you just say "for all systems isomorphic to the one construced in df-c".
What is interesting to me right now is developing a port of set.mm with the kind of module structure I outlined above. Ghilbert Pax is the beginning of such an effort, but it's not quite ready as the basis to do "real work" yet. I'm getting a bit sidetracked on the development of Peano arithmetic, which is of course powerful in its own right because it includes all recursive functions. Even so, it should be possible to jump ahead and develop an interface for complex numbers, to try out the ideas sketched above.
--raph 13 Oct 2006
I think interfaces provide exactly the sort of abstraction I'm looking for.
…which is troubling in a way, because it means interfaces are far more powerful than I had thought. They're not just a harmless artifact of the programming side of the house. They have semantic consequences.
Still, I think I like them.
--jorend 18 Oct 2006
"Peano's arithmetic is inconsistent"
I have just been reading this sentence on a newsgroup. I'm not a specialist but it sounds so strange. So is Peano's arithmetic consistent? (in that case very bravely I will correct the mistake of my French friend :-) ). – fl
It is safe to say that Peano's arithmetic has not been proven inconsistent, as such a proof would revolutionize mathematics and make major headlines in the news. On the other hand, any theory that is able to express elementary arithmetic cannot be both consistent and complete, so we can't say that Peano's arithmetic is consistent, either, although it seems to be a pretty safe assumption from a practical point of view. See Gödel's incompleteness theorem. – norm 31 Oct 2006
Thanks for the reference. By the way I've found the original article by Peano in a book. Very impressive (the birth act (???) of logic in some way). It's in latin. There are about 90 propositional axioms (certainly the largest propositional axiomatic in the world :-) ) and there are axioms that look like '(a e. N → a = a )'. – fl 1-Nov-2006
Also of interest is self-verifying theories that (necessarily) cannot contain Peano arithmetic due to Gödel's incompleteness theorem, but are sufficiently strong that they can prove their own consistency. These have been studied by Dan Willard, and much of the work seems relatively recent (after the year 2000). According to the Wikipedia article, "there are self-verifying systems capable of proving the consistency of Peano arithmetic." I know very little about this field, so I can't say much more, but it sounds quite interesting. – norm 1 Nov 2006
There was a message about self-verifying theories on FOM list: http://www.cs.nyu.edu/pipermail/fom/2006-November/011095.html. michael 12 Nov 2006
One thing I don't understand is that if a self-verifying theory can also prove the consistency of Peano arithmetic, doesn't that make Gödel's second incompleteness theorem irrelevant? I must be missing something fundamental in the big picture, because this would seem to be astonishing news on par with the second theorem itself, but I had never heard of it until I stumbled across mention of "self-verifying theories" quite by accident. Perhaps someone more knowledgeable can answer. – norm 13 Nov 2006
Question about distinct variable restrictions
Question
I'm wondering about the necessity for the disjoint variables statements of a $p assertion to contain $d pairs that involve variables which are not mandatory for the assertion.
If the paragraph on "Verifying Disjoint Variable Restrictions" in section 4.1.4 of the Metamath document were changed to the following:
If two variables replaced by a substitution exist in a mandatory $d statement of the assertion referenced, the two expressions resulting from the substitution must meet satisfy the following conditions. First, the two expressions must have no variables in common. Second, each possible pair of variables, one from each expression, in which both variables are mandatory for the $p statement containing the proof, must exist in an active $d statement of the $p statement containing the proof.
What would break? The non-mandatory disjoint variable restrictions of an assertion play no role when the assertion is used in subsequent proofs… – dank 7 Jan 2007
Answer
Hi Dan,
This is an interesting proposal. As you know, the Metamath spec currently requires that $d's for dummy variables be mentioned explicitly.
Both Ghilbert and Marnix's Hmm verifier for Metamath make this requirement optional, but I think there is a subtle difference in what you are proposing. I believe those programs make the implicit assumption that dummies are distinct from all other variables and still perform the checking implied by the spec. The main intent of their approach is to avoid cluttering the database with those $d's (or Ghilbert's equivalent) that can be inferred from context.
What you are suggesting is that we can skip the distinct variable checking of dummy variables completely, since the necessary requirement will be automatically enforced by the requirement "First, the two expressions must have no variables in common."
As for the spec itself, the current version (for reference) is:
- Each substitution made in a proof must be checked to verify that any disjoint variable restrictions are satisfied, as follows. If two variables replaced by a substitution exist in a mandatory $d statement of the assertion referenced, the two expressions resulting from the substitution must meet satisfy the following conditions. First, the two expressions must have no variables in common. Second, each possible pair of variables, one from each expression, must exist in an active $d statement of the $p statement containing the proof.
marnix has pointed out that clause "First, the two expressions must have no variables in common" is automatically satisfied by "Second,…" since a $d of the form "$d x x" (the same variable for both arguments) is disallowed elsewhere in the spec, thus automatically satisfying the "First,…" clause. Thus, the spec could be simplified to
- Each substitution made in a proof must be checked to verify that any disjoint variable restrictions are satisfied, as follows. If two variables replaced by a substitution exist in a mandatory $d statement of the assertion referenced, the two expressions resulting from the substitution must meet satisfy the following condition. Each possible pair of variables, one from each expression, must exist in an active $d statement of the $p statement containing the proof.
While I have been considering a footnote to point this out - it may speed up some verifiers - my idea was to leave the "First,…" clause in for clarity, even though it is theoretically redundant.
What you are proposing is
- Each substitution made in a proof must be checked to verify that any disjoint variable restrictions are satisfied, as follows. If two variables replaced by a substitution exist in a mandatory $d statement of the assertion referenced, the two expressions resulting from the substitution must meet satisfy the following conditions. First, the two expressions must have no variables in common. Second, each possible pair of variables, one from each expression, in which both variables are mandatory for the $p statement containing the proof, must exist in an active $d statement of the $p statement containing the proof.
Basically, the distinct variable requirements for dummy variables will automatically be satified by the "First,…" clause, making it unnecessary to do the checking for them required by the original spec's "Second,…" clause. So in this case, unlike in Marnix's proposal, the "First,…" clause becomes essential.
The reason your proposal works is that we aren't allowed to make substitutions into proof steps to derive new proof steps from them; instead, each earlier proof step must be used as-is towards the derivation of later proof steps. So, the $d's on dummies are implicitly satisfied as soon as the substitution into an external theorem is done (with just the checking for no variables in common), and we never have to check them explicitly since they eventually get dropped.
This is clever, and I hadn't thought of it before. Have you looked at what speedup might result from not checking dummy $d's?
As for changing the spec, I don't like to do that without a lot of thought and other input (I think there has been only one important change since 1997). Since set.mm would be compatible with your change - the $d's on dummies would just become redundant - there is time to think things over, even if you write a verifier using that approach. Or, for Ghilbert, it seems you are home free with its spec as-is - your approach would just be a speedup.
As a spec change, your proposal makes the spec a little less direct, since we need to have a theoretical justification that no distinct variable violations will occur even though we don't check for them. However, if we just take out the requirement that $d's on dummies must be explicit, like the assumption Hmm makes, your approach will be compatible. The spec could be written for the Hmm approach - i.e. implicit $d's, but still checked - for clarity. Then your proposal, rather than a spec change, could be considered an optional faster algorithm for achieving the same goal, and could be mentioned as a footnote to the spec for future implementors.
Aside from historical reasons and inertia, my resistance to making $d's on dummies optional has to do with my feeling that this would make the language more confusing to learn. With the current spec, each proof step can be considered by the user to be a stand-alone theorem in its own right, with all of its $d requirements made explicit, without having to reference the final theorem to determine the implicit $d's of dummy variables (and having to learn that rule in the first place).
As you know, on the web pages I omit any distinct variable groups with dummy variables to make the pages less cluttered. I made this change a few years ago; before that, they were explicit like they are in set.mm. While the result is unquestionably aesthetically more pleasant, and it is unlikely I'd go back, I had and still have some misgivings because novices have been confused. The distinct variable concept is already hard enough to grasp, and in addition we also hit them with (to them) confusing conditions under which they are "optional", "implicit", or "inferred from context". Some emails I have received from newcomers have reflected this confusion. My response and fallback is to point out that it's just a display thing for better readability, but "really" they must be distinct, as the database very explicitly indicates. Their explicit mention in set.mm provides a kind of security blanket against being confused by additional rules for implicit $d's. Since they are not optional, a novice can comment them out to see a detailed error message explaining exactly what they are used for and why they are needed.
Up to now, there was no penalty for requiring the $d's on dummies to be explicit other than a minor increase in the size of set.mm. If your proposal results in a significant speedup of verification, that will be additional impetus for considering a spec change.
– norm 8 Jan 2007
Let's make this discussion more concrete. Suppose the referenced assertion's replaced variables are A and B, and that there is a mandatory $d restriction on them.
Case 1: proof step N substitutes
C and X for A, and
D and Y for B.
Case 2: proof step N substitutes
C and X for A, and
D and X for B.
where C and D are mandatory and
X and Y are optional/dummy.
Assuming that condition 1 (no variables in common) is retained and that condition 2 is modified to restrict the $d inheritance check to just pairs of mandatory variables, then Case 1 is valid and Case 2 is invalid (fails condition 1).
The big saving in Case 1 is not performing the Optional $d lookup for X/Y, C/Y and D/X.
However, algorithmically speaking, the program must now know that X and Y are "dummy" variables in this context – which means doing a lookup to see that both X and Y have $f hypotheses in the mandatory frame of the theorem being proved. Unless the "fact" of each variable's mandatory/optional status is cached somehow, the mandatory $f lookup would need to be performed for each variable of each possible pair of substituting variables (or, perhaps subsequent to a NotFound? result from the mandatory-$d lookup.)
Thus, eliminating Optional $d specifications appears to add complexity to the Proof Verification algorithm but reduces the size of the .mm file.
A further Metamath.pdf change would be required in the area describing Optional Frames. The Optional Frame $d pair lists contain variable pairs mentioned in $d statements wherein one or both of the variables do not have mandatory $f hypotheses.
- This is a good point; metamath.pdf would have to be changed in several places. I'm not sure the best way to introduce it to the user - we already have confusing "mandatory" and "optional" things; we would be adding phantom "implicit" things the user has to imagine in his or her head. :) – norm
And, making this spec change would trigger code changes in each the n proof verifiers that have been written over the years… And, in mmj2's Proof Assistant, for example, the possibly unwise decision was made to use a "combo" Frame that merges the Mandatory and Optional frames (due to the fact that new theorems not present in the .mm file can be proved.) The "combo" frame works precisely because of the parallel structure of the Mandatory and Optional Frames – it doesn't need to know which variables or variable pairs are mandatory or optional/dummy.
--ocat 8-Jan-2007
norm here: Yes, the existing underlying algorithm could affect whether or how much this algorithm would speed things up. But from a complexity point of view, if the two expressions being substituted had n variables each, the number of pairs to be checked could be O(n^2). That's why I would be interested in empirical speedup figures. Actually, by "Metamath," I suspect Dan may really mean "Ghilbert" and is using the Metamath spec for sake of discussion - am I right, Dan? [Later - I see I am right, in his edit below added simultaneously with mine. – n] In that case, this discussion would be not be relevant since Ghilbert doesn't require specifying the dummy $d's. A Ghilbert verifier can choose to use Dan's method or its existing method, whichever is faster.
I understand it would be a big deal to put this into all Metamath verifiers, but since the existing set.mm is compatible (although not the other way), it could be phased in slowly. For metamath.exe, I would probably have both ways implemented - the existing one that requires the presence of dummy $d's, and Dan's that might speed up the verification. For a long time, maybe years, I would probably keep set.mm compatible with the old way, so nothing would have to be changed right away, and there'd be lots of time to experiment and decide whether it is a good idea. We could even keep the present spec and just add Dan's method as an optional "quick verify" for frequent use after set.mm changes, with a "full verify" (existing algorithm) before a set.mm release that makes sure all the dummy $d's are present.
So for mmj2, there is no hurry. And anyway, I'm not eager to make $d's harder to learn by introducing the additional concept of hidden "implicit" $d's, unless I can be convinced that it really isn't more confusing for someone learning Metamath. To me that is an important consideration, and I would like to hear opinions on it. – norm 8 Jan 2007
Norm and ocat,
Thank you very much for your thoughtful and thorough responses to my question!
I hadn't actually been coming to this from the point of view of speeding up verification. I'm presently working on a draft of the Ghilbert language specification, and I was claiming that non-mandatory distinct variable pairs were not needed in Ghilbert's equivalent of the active $d statements for a theorem being proven. However, I was aware that this was not presently the case for Metamath, and also think there may be some small differences in how gh_verify.py and shul deal with this issue, so I wanted to check my understanding of this issue and see if there was a fundamental (subtle?) reason why the "optional" distinct variable pairs must be listed.
I was also wondering if the fact that Ghilbert may not require the optional distinct variable pairs while Metamath does might complicate the translation of theorems proved in Ghilbert back to Metamath, but I don't think that's a serious issue.
As to potential speedup, this would of course depend upon the implementation of the verifier, but I wouldn't expect a big effect one way or the other.
– dank 8-Jan-2007
Hi Norm,
I don't see changing mmj2 as a huge problem. Not at all. Mostly this would be about removing functionality, except for having to "know" that variable v is a "dummy" during $d checking of each pair of variables. Failure to modify the code would simply result in erroneous $d error messages… If this is to be done it would be best to plan it for a given date – say, 3 months in the future. Re-testing everything is the bigger issue, but some of us have regression test cases :)
I think learning Metamath would maybe be simpler without "optional" $d's. (Better to refer to them as "work variables" than "dummies" – which already has connotations – or "optional", which doesn't make much sense to a novice :) Optional Frames are confusing already, along with local $f's -- which otherwise, without them, life would be simpler and we would have nothing but global variables to worry about.
I may be kinda slow, but the whole topic of $d's is tricky without an example of subject-object language distinctions and maybe an example of mapping from the .mm subject language to a real object language.
FYI, I think converting Metamath to OMDoc is going to be very interesting. I think the Tarski-Megill approach is novel and worthy of further research. For example, the use of wff metavariables is like, instead of First Order Logic, you have 1.5th Order Logic :) The guys doing OMDoc, MBase, and the Omega System – see mathweb.org – are actually doing the Asteroid HDM project and they have probably 100 man years invested in it. Their "web" of provers connects existing provers and uses distributed processors in a web that spans Europe! Most of it is Lisp, but they use MySQL? and a distributed-concurrent language called Mozart. Why mention this? Because Metamath is beautiful and elegant – few people can look at Omega and visually inspect everything to know a proof is correct (I suppose). On the other hand, the Metamath proof system has certain rigidities as a result of being logically agnostic ("ontologically uncommitted" as M. Kholhase might say.) Sooooo….I don't see any interest in converting Metamath to OMDoc/MBase, except for me, but the conversion process is bound to be theoretically interesting and will result in, I believe, an addition to the cluster of Logical Frameworks (each with its own theory of entailment.) Part of the conversion must be to describe how the Metamath language works, metalogically with $d's, etc., at a generic level (not just set.mm). So there will be a new opportunity to explain Metamath, and perhaps even to fit it into the growing OMDoc|MBase| Omega|MathWeb universe. (This is going to be slow trucking for me working alone, especially because these folk are so far ahead on the HDM front…and their lead is accelerating, hoho. :) --ocat
Metamath.pdf 4.3.1, Possible Inaccuracy
In the Metamath.pdf section 4.3.1, "The Concept of Unification", sentence 2 of paragraph 2 states:
"The syntax of the Metamath language ensures that if
a set of substitutions exists, it will be unique."That should probably say something like,
"The unambiguous syntax of set.mm ensures that if a
set of substitutions exists, it will be unique. The
author(s) of a Metamath file are solely responsible
for defining an unambiguous formula syntax.
- I agree that the section may be poorly written, but do you have a specific counterexample in mind? --norm 9 Mar 2007
- Simply delete sentence 2 of paragraph 2 of 4.3.1.
- I agree it is misleading, and I'll delete that sentence. It is the specification, not the syntax, that determines uniqueness of substitutions. Earlier, on p. 115: "The Metamath language is specified in such a way that if a set of substitutions exists, it will be unique. Specifically, the requirement that each variable have a type specified for it with a $f statement ensures the uniqueness." Historically, before this requirement was added to the spec, uniqueness was enforced by the verifier, and the spec said, "a unique substitution must exist" for a proof to be valid. Now it says (p. 95), "a (unique) substitution must exist," implying that uniqueness is automatic. In the metamath.exe program itself, this now-redundant check for uniqueness is still there (see mmveri.c, line 821, which prints the error message and shows two of the possible unifications). So if you believe you can construct a counterexample to uniqueness due to a flaw in the spec, the metamath.exe verifier (though probably not the others) will detect it.
- .
- The uniqueness of unification shouldn't be confused with uniqueness of parsing, which is a different issue. The latter has to do with whether there is more than one way to construct the same wff (or class or other expression type). The philosophy of "pure" Metamath (which, for parsing simplicity, has been suppressed in the set.mm implementation, thanks to you) is that a wff construction is just a "proof", and just as there can be more than one way to prove (2+2)=4, in principle there could be - and in fact used to be - different ways to show x=y is a wff. – norm 10 Mar 2007
- Simply delete sentence 2 of paragraph 2 of 4.3.1.
I would also suggest an alteration of 4.3.1 to take into account the fact that a successful unification involves unification of the provable assertion's formula as well as its floating and essential hypotheses – though I realize that Metamath.exe may separate these functions algorithmically.
For example (Prepare to ROTFLYAO at the idea of incorporating what follows into Metamath.pdf :-)
'Metamath "unification" is the process of
determining a consistent set of valid, simultaneous
substitutions to the variables of an assertion and
its essential hypotheses such that the resulting
formulas are identical to the $p assertion formula
and its essential hypotheses' formulas.
Definitions:
"Type" - the constant, first symbol of a
Metamath formula (e.g. "wff", "class"
or "set").
"Expression" - the 2nd through last symbols
of a Metamath formula.
"Valid" - a variable can be validly substituted
with any expression whose Type matches
the Type of the variable's floating
hypothesis formula.
"Simultaneous" - all substitutions are made at once,
which means in effect, that each
substitution is independent of every other.
For example, given "x + y" and substitutions
"x * y" for each "x", and "y * z" for each
"y", the resulting expression is
"x * y + y * z" -- not "x * y * z + y * z".
"Consistent" - all occurrences of a given variable
in the referenced assertion and its hypotheses
must be substituted with the same expression.
An alternative explanation that may be easier to
understand is based on the algorithm used in Mel O'Cat's
mmj2 program -- which has grammatical requirements that
are slightly stronger than those in metamath.exe, but
which are satisfied by the grammars of set.mm and ql.mm:
Suppose that proof step S uses assertion A as
proof justification (for simplicity assume there
are no essential hypotheses involved).
Then, if S and its hypotheses can be unified with A
and its hypotheses, then proof step S is justified --
and provable, subject to any disjoint variable
requirements.
A Formula S can be "unified" with Formula A if
the formulas' abstract syntax trees are identical
except at the variable nodes of Tree A; and
For each variable node "x" in Tree A, there is
a subtree "E" at the corresponding tree node
position of Tree S such that:
E and x have the same Type; and
Simultaneous, consistent replacement of subtree
E for every x node in Tree A is possible.
If all of these conditions are met then unification
yields a consistent set of valid, simultaneous
substitutions that make Tree A equal to Tree S,
and assertion A can be said to justify proof step S,
(subject to any disjoint variable restrictions.)
'
--ocat 9-Mar-2007
An elegant page with a lot of non-latin characters
One of my favourite page: Metamath is cited at the bottom. Characters, pictures: everything is elegant. It's written in Farsi I suppose.
http://fa.wikipedia.org/wiki/%D8%B1%DB%8C%D8%A7%D8%B6%DB%8C%D8%A7%D8%AA